Trong các chương trước, chúng ta đã tập trung vào việc mô hình hóa các biến phản hồi định tính, tức là các biến biểu thị sự lựa chọn hoặc phân loại (Có/Không, A/B/C, Tốt/Trung bình/Kém). Tuy nhiên, trong các hoạt động kinh tế và kinh doanh, có một loại biến rời rạc khác cũng vô cùng phổ biến: dữ liệu đếm (count data). Đây là các biến ghi nhận số lần một sự kiện xảy ra trong một khoảng thời gian hoặc không gian nhất định, ví dụ:
Số lượng sản phẩm một khách hàng mua trong một tháng.
Số lượng khiếu nại mà một trung tâm dịch vụ khách hàng nhận được trong một ngày.
Số vụ tai nạn xảy ra tại một giao lộ trong một năm.
Số lượng bài báo một nhà nghiên cứu xuất bản.
Các biến này là các số nguyên không âm (0, 1, 2, 3, …). Việc áp dụng mô hình hồi quy tuyến tính cổ điển (OLS) cho dữ liệu đếm là không phù hợp vì nó có thể dự báo các giá trị âm và vi phạm các giả định về phân phối của phần dư. Do đó, chúng ta cần một họ mô hình chuyên biệt cho loại dữ liệu này.
Chương này sẽ giới thiệu cho các bạn công cụ nền tảng để phân tích dữ liệu đếm: Mô hình Hồi quy Poisson. Dựa trên nền tảng GLM đã học, chúng ta sẽ khám phá cách mô hình Poisson, cách diễn giải các hệ số của nó một cách trực quan thông qua Tỷ số Tỷ suất (Rate Ratios), và vai trò quan trọng của biến offset trong việc chuẩn hóa các số đếm.
Quan trọng hơn, chúng ta sẽ đối mặt với một thách thức kinh điển của dữ liệu đếm trong thực tế: hiện tượng quá phân tán (overdispersion), tức là khi phương sai của dữ liệu lớn hơn nhiều so với những gì mô hình Poisson dự đoán. Chúng ta sẽ học cách phát hiện và xử lý vấn đề này bằng các mô hình linh hoạt hơn như Hồi quy Quasi-Poisson và đặc biệt là Hồi quy Negative Binomial, mô hình tiêu biểu cho dữ liệu đếm quá phân tán. Cuối cùng, một cái nhìn tổng quan về các mô hình lạm phát không (zero-inflated models) sẽ được giới thiệu để xử lý các trường hợp có quá nhiều giá trị 0 trong dữ liệu.
Mục tiêu chương
Sau khi hoàn thành chương này, người học sẽ có khả năng:
Nhận diện dữ liệu đếm và hiểu sự cần thiết của các mô hình chuyên biệt.
Xây dựng, ước lượng và diễn giải mô hình Hồi quy Poisson.
Hiểu và sử dụng biến offset để mô hình hóa các tỷ suất (rates).
Giới thiệu về vấn đề lạm phát số không và các mô hình giải quyết.
Ứng dụng thành thạo R để phân tích dữ liệu đếm.
7.1 Giới thiệu Dữ liệu Đếm và Hồi quy Poisson
Dữ liệu đếm là các quan sát chỉ có thể nhận các giá trị nguyên không âm \(\{0, 1, 2, ...\}\). Mô hình cơ bản nhất cho loại dữ liệu này là Hồi quy Poisson, một thành viên của họ GLM với các đặc điểm:
Thành phần Ngẫu nhiên: Biến phản hồi (biến phụ thuộc) \(Y\) được giả định tuân theo phân phối Poisson. Một biến \(Y \sim \text{Poisson}(\mu)\) có hàm khối lượng xác suất: \[P(Y=y) = \frac{e^{-\mu}\mu^y}{y!}, \quad y=0, 1, 2, \dots\] Một đặc tính quan trọng và cũng là giả định cốt lõi của phân phối Poisson là kỳ vọng bằng với phương sai: \(E(Y) = Var(Y) = \mu\).
Hàm liên kết: Sử dụng hàm liên kết Log, là hàm liên kết kinh điển cho phân phối Poisson. \(g(\mu) = \log(\mu)\)
Thành phần Hệ thống:\(\log(\mu) = \beta_0 + \beta_1 X_1 + \dots + \beta_k X_k\).
Từ đó, ta có thể biểu diễn số đếm kỳ vọng \(\mu\) như sau: \[\mu = E(Y|X) = \exp(\beta_0 + \beta_1 X_1 + \dots + \beta_k X_k)\] Việc sử dụng hàm mũ đảm bảo rằng số đếm kỳ vọng dự báo \(\hat{\mu}\) luôn dương, phù hợp với bản chất của dữ liệu đếm.
7.2 Diễn giải tham số
7.2.1 Tỷ số Tỷ suất
Tương tự như Odds Ratio trong mô hình logistic, cách diễn giải hữu ích nhất cho các hệ số trong mô hình Poisson là thông qua Tỷ số Tỷ suất (Rate Ratio), được tính bằng \(\exp(\beta_k)\).
Hãy xem xét tác động của việc tăng biến \(X_k\) lên 1 đơn vị:
Số đếm kỳ vọng cũ (tại \(X_k\)): \(\mu_1 = \exp(\dots + \beta_k X_k + \dots)\)
Số đếm kỳ vọng mới (tại \(X_k+1\)): \(\mu_2 = \exp(\dots + \beta_k (X_k+1) + \dots) = \mu_1 \times \exp(\beta_k)\)
Tỷ số của số đếm kỳ vọng mới so với cũ là: \(\frac{\mu_2}{\mu_1} = \exp(\beta_k)\)
Diễn giải: Khi biến độc lập \(X_k\) tăng 1 đơn vị, số đếm kỳ vọng (hay tỷ suất) của \(Y\) sẽ thay đổi (tăng hoặc giảm) một lượng bằng \(\exp(\beta_k)\) lần, khi các biến khác không đổi.
Nếu \(\beta_k > 0\), \(\exp(\beta_k) > 1\): Số đếm kỳ vọng tăng. Ví dụ, nếu \(\exp(\beta_k) = 1.2\), số đếm kỳ vọng tăng 20%.
Nếu \(\beta_k < 0\), \(\exp(\beta_k) < 1\): Số đếm kỳ vọng giảm. Ví dụ, nếu \(\exp(\beta_k) = 0.8\), số đếm kỳ vọng giảm 20%.
7.2.2 Vai trò của Exposure và Offset
Thường thì số đếm \(Y\) được quan sát trong một “khoảng” (thời gian, không gian, số lượng) khác nhau giữa các quan sát. Biến đo lường “khoảng” này được gọi là exposure (phơi nhiễm). Ví dụ:
Số vụ tai nạn (\(Y\)) xảy ra trên các đoạn đường có lưu lượng giao thông (exposure) khác nhau.
Số lượng bệnh nhân mắc bệnh (\(Y\)) trong các thành phố có dân số (exposure) khác nhau.
Số lượng lỗi phần mềm (\(Y\)) được tìm thấy trong các module có số dòng mã (exposure) khác nhau.
Để so sánh một cách công bằng, chúng ta cần mô hình hóa tỷ suất (rate), chứ không phải số đếm thô. \[\text{Tỷ suất} = \frac{\text{Số đếm}}{\text{Exposure}} \implies E\left(\frac{Y_i}{t_i}\right) = \exp(X_i\beta)\] trong đó \(t_i\) là exposure của quan sát \(i\). Biến đổi phương trình trên: \[E(Y_i) = \mu_i = t_i \times \exp(X_i\beta)\] Lấy logarit hai vế: \[\log(\mu_i) = \log(t_i) + X_i\beta\] Thuật ngữ \(\log(t_i)\) là một biến trong mô hình có hệ số bị cố định bằng 1. Nó được gọi là biến offset.
Trong R: Chúng ta chỉ định biến offset bằng hàm offset() trong hàm glm() như sau: glm(y ~ x1 + x2 + offset(log(exposure)), ...)
7.3 Đánh giá độ phù hợp và Vấn đề Quá phân tán
Giả định cốt lõi của mô hình Poisson là \(Var(Y) = E(Y)\). Trong thực tế, phương sai thường lớn hơn kỳ vọng (\(Var(Y) > E(Y)\)). Đây là hiện tượng quá phân tán (overdispersion).
Hậu quả: Mô hình Poisson vẫn cho ước lượng hệ số không chệch, nhưng sai số chuẩn (standard errors) sẽ bị ước tính thấp hơn thực tế. Điều này dẫn đến việc các kiểm định thống kê trở nên quá “lạc quan”, làm chúng ta có thể kết luận sai về ý nghĩa của các biến.
Phát hiện:
Kiểm tra trực quan: So sánh Residual deviance và Residual degrees of freedom từ summary(model). Nếu tỷ lệ \(\phi = \text{Deviance/df} \gg 1\), đó là dấu hiệu mạnh của quá phân tán. \(\phi\) được gọi là tham số phân tán (dispersion parameter).
Kiểm định chính thức: Sử dụng hàm dispersiontest() từ gói AER.
\(H_0\): Không có quá phân tán (\(\phi=1\)).
\(H_a\): Có quá phân tán (\(\phi>1\)).
Một p-value nhỏ cho thấy có bằng chứng về quá phân tán.
7.4 Các mô hình thay thế
7.4.1 Hồi quy Quasi-Poisson
Ý tưởng: Không dựa trên một phân phối xác suất cụ thể, mà bắt đầu từ mô hình Poisson và điều chỉnh cho quá phân tán bằng cách giả định \(Var(Y) = \phi \times \mu\).
Cách hoạt động: Ước lượng \(\beta\) giống mô hình Poisson, sau đó ước tính \(\phi\) và dùng nó để điều chỉnh lại các sai số chuẩn: \(SE_{quasi} = SE_{poisson} \times \sqrt{\hat{\phi}}\). Các kiểm định t và F sẽ được sử dụng thay cho z và Chi-bình phương.
Trong R:glm(..., family = quasipoisson)
Ưu/Nhược điểm: Dễ thực hiện, sửa được sai số chuẩn. Tuy nhiên, không thể dùng AIC/BIC để so sánh mô hình vì nó không dựa trên hàm hợp lý.
7.4.2 Hồi quy Negative Binomial
Ý tưởng: Đây là mô hình thay thế phổ biến và mạnh mẽ nhất, dựa trên một phân phối xác suất cụ thể (Negative Binomial). Nó cho phép phương sai lớn hơn kỳ vọng một cách có hệ thống.
Hàm phương sai:\(Var(Y) = \mu + \frac{\mu^2}{\theta} = \mu(1 + \mu/\theta)\). Tham số \(\theta\) (dispersion parameter, còn gọi là size) đo lường mức độ quá phân tán. Khi \(\theta \to \infty\), mô hình NB hội tụ về mô hình Poisson.
Trong R: Sử dụng hàm glm.nb() từ gói MASS.
Ưu điểm: Dựa trên hàm hợp lý, cho phép sử dụng AIC/BIC để so sánh mô hình. Thường được ưa chuộng hơn Quasi-Poisson.
7.5 Giới thiệu về mô hình Lạm phát số không
Đôi khi, dữ liệu đếm có số lượng các giá trị 0 nhiều hơn hẳn so với dự đoán của mô hình Poisson hay NB. Đây gọi là hiện tượng lạm phát số không (zero-inflation).
Nguyên nhân: Dữ liệu có thể được tạo ra từ hai quá trình:
Quá trình lựa chọn (logit): Quyết định xem một quan sát có thuộc nhóm “chắc chắn có giá trị 0” hay không (ví dụ, một người không bao giờ đi cắm trại sẽ chắc chắn có số lần bắt cá bằng 0).
Quá trình đếm (Poisson/NB): Nếu quan sát không thuộc nhóm “chắc chắn 0”, thì số đếm của nó sẽ được tạo ra từ một phân phối Poisson hoặc NB (vẫn có thể ngẫu nhiên bằng 0).
Giải pháp: Các mô hình Zero-Inflated Poisson (ZIP) hoặc Zero-Inflated Negative Binomial (ZINB) sẽ ước lượng đồng thời cả hai quá trình này.
Trong R: Gói pscl (hàm zeroinfl()) hoặc glmmTMB.
7.6 Ứng dụng R trong phân tích dữ liệu đếm
Chúng ta sẽ sử dụng bộ dữ liệu bioChemists từ gói pscl để minh họa. Dữ liệu này về số lượng bài báo (art) được xuất bản bởi các nhà nghiên cứu tiến sĩ hóa sinh.
# Cài đặt các gói nếu cần# install.packages(c("pscl", "MASS", "AER"))library(pscl)
Classes and Methods for R originally developed in the
Political Science Computational Laboratory
Department of Political Science
Stanford University (2002-2015),
by and under the direction of Simon Jackman.
hurdle and zeroinfl functions by Achim Zeileis.
library(MASS)library(AER)
Loading required package: car
Loading required package: carData
Loading required package: lmtest
Loading required package: zoo
Attaching package: 'zoo'
The following objects are masked from 'package:base':
as.Date, as.Date.numeric
Loading required package: sandwich
Loading required package: survival
# Tải và khám phá dữ liệudata("bioChemists")str(bioChemists)
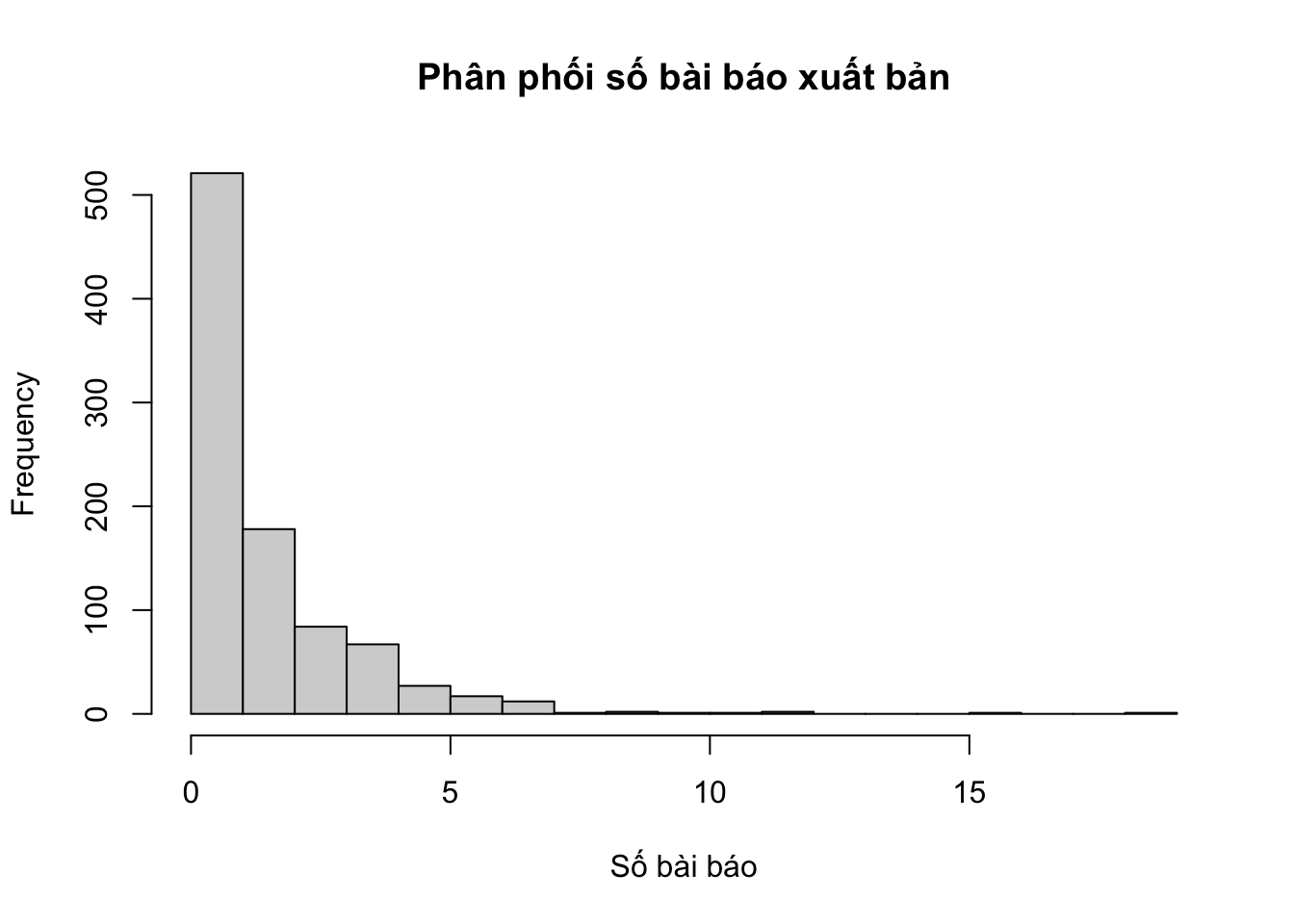
# Vẽ biểu đồ phân phối của biến phản hồihist(bioChemists$art, breaks =20, main ="Phân phối số bài báo xuất bản", xlab="Số bài báo")
1. Xây dựng và kiểm tra mô hình Poisson
poisson_model <-glm(art ~ fem + mar + kid5 + phd + ment, data = bioChemists,family = poisson)summary(poisson_model)# Kiểm tra quá phân tándispersiontest(poisson_model)
Phân tích kết quả:
Tỷ lệ Residual deviance / df = 285.87 / 194 = 1.47, lớn hơn 1.
Kết quả dispersiontest cho p-value rất nhỏ (\(< 2.2 \times 10^{-16}\)), bác bỏ giả thuyết \(H_0\) (không có quá phân tán).
Kết luận: Có bằng chứng mạnh mẽ về quá phân tán. Mô hình Poisson không phù hợp.
2. Xây dựng mô hình Negative Binomial Đây là lựa chọn hợp lý để xử lý quá phân tán.
nb_model <-glm.nb(art ~ fem + mar + kid5 + phd + ment, data = bioChemists)#summary(nb_model)
Phân tích kết quả:
So sánh summary() của hai mô hình, ta thấy các sai số chuẩn (Std. Error) trong mô hình NB lớn hơn đáng kể so với mô hình Poisson.
Ví dụ, với biến marMarried, p-value trong mô hình Poisson là 0.038 (có ý nghĩa ở mức 5%), nhưng trong mô hình NB là 0.165 (không còn ý nghĩa).
Đây là một kết luận thận trọng và đáng tin cậy hơn, cho thấy mô hình Poisson đã đánh giá quá cao ý nghĩa của biến này.
Tham số Theta (tức \(\theta\)) được ước tính là 1.145. Giá trị hữu hạn này xác nhận sự tồn tại của quá phân tán.
3. Diễn giải kết quả mô hình NB
# Tính Rate Ratiosrr_nb <-exp(coef(nb_model))print(rr_nb)
Diễn giải kid5:exp(-0.186) ≈ 0.83. Với mỗi đứa con dưới 5 tuổi tăng thêm, số bài báo kỳ vọng của một nhà nghiên cứu giảm khoảng 17% (bằng 0.83 lần), khi các yếu tố khác không đổi.
Diễn giải ment:exp(0.084) ≈ 1.088. Với mỗi bài báo của người hướng dẫn tăng thêm, số bài báo kỳ vọng của nhà nghiên cứu tăng khoảng 8.8%, khi các yếu tố khác không đổi.
7.7 Tóm tắt chương
Chương 6 đã giới thiệu các phương pháp mô hình hóa cho dữ liệu đếm, một loại dữ liệu rời rạc phổ biến.
Hồi quy Poisson: Là mô hình nền tảng, thuộc họ GLM, mô hình hóa log của số đếm kỳ vọng. Các hệ số được diễn giải qua Rate Ratios.
Offset: Đã tìm hiểu vai trò quan trọng của biến offset trong việc mô hình hóa các tỷ suất (rates) thay vì số đếm thô, giúp so sánh công bằng giữa các quan sát có “exposure” khác nhau.
Quá phân tán (Overdispersion): Đã thảo luận về vấn đề kinh điển này, khi phương sai lớn hơn kỳ vọng. Chúng ta đã học cách phát hiện (Deviance/df, dispersiontest) và hiểu hậu quả của nó là làm sai lệch các suy diễn thống kê.
Các mô hình thay thế:Hồi quy Quasi-Poisson được giới thiệu như một giải pháp nhanh để điều chỉnh sai số chuẩn, và Hồi quy Negative Binomial là giải pháp tiêu chuẩn, mạnh mẽ hơn dựa trên phân phối xác suất cụ thể.
Lạm phát số không: Đã giới thiệu ngắn gọn về vấn đề có quá nhiều số 0 và các mô hình ZIP/ZINB để giải quyết.
Thực hành R: Đã sử dụng các gói MASS, AER, pscl để xây dựng và so sánh các mô hình này.
7.8 Case studies
Case Study 6.1: Dự báo số lượng xe đạp cho thuê * Bối cảnh: Một công ty cho thuê xe đạp muốn dự báo số lượng xe được thuê (count) mỗi giờ dựa trên các yếu tố thời tiết (temp, humidity) và thời gian (hour, day_of_week). * Dữ liệu: Sử dụng bộ dữ liệu Bike Sharing từ UCI hoặc Kaggle (có thể tìm thấy trong nhiều gói R). * Nhiệm vụ: 1. Xây dựng mô hình Poisson. 2. Kiểm tra và xác nhận có hiện tượng quá phân tán. 3. Xây dựng mô hình Negative Binomial và so sánh kết quả (AIC, ý nghĩa của các biến).
Case Study 6.2: Phân tích số vụ tai nạn trên đường cao tốc * Bối cảnh: Một cơ quan an toàn giao thông muốn phân tích số vụ tai nạn (accidents) trên các đoạn đường khác nhau. Họ có dữ liệu về traffic_volume (lưu lượng xe) và các đặc điểm của đoạn đường (speed_limit, num_lanes). * Nhiệm vụ: 1. Xây dựng mô hình Poisson để dự báo accidents, sử dụng log(traffic_volume) làm biến offset. 2. Diễn giải hệ số của một biến đặc điểm (ví dụ: speed_limit). 3. Thảo luận tại sao việc sử dụng offset ở đây lại quan trọng.
Case Study 6.3: Mô hình hóa số lượng bằng sáng chế của công ty * Bối cảnh: Một nhà kinh tế nghiên cứu các yếu tố ảnh hưởng đến số lượng bằng sáng chế (patents) mà một công ty đăng ký, dựa trên chi tiêu cho R&D (rd_spending) và quy mô công ty (size). * Nhiệm vụ: 1. Xây dựng mô hình NB. 2. Quan sát biểu đồ phân phối của biến patents. Nếu có rất nhiều công ty không có bằng sáng chế nào, hãy thảo luận về khả năng áp dụng mô hình Zero-Inflated. 3. Sử dụng gói pscl để chạy mô hình ZINB và so sánh kết quả.
7.9 Bài tập
7.9.1 Bài tập lý thuyết
Sự khác biệt cơ bản giữa dữ liệu đếm và dữ liệu định tính là gì?
Tại sao mô hình OLS không phù hợp cho dữ liệu đếm?
Giả định cốt lõi của mô hình hồi quy Poisson là gì?
Rate Ratio trong mô hình Poisson có ý nghĩa là gì?
Giải thích sự khác biệt giữa “exposure” và “offset”. Khi nào chúng ta cần dùng offset?
Quá phân tán (overdispersion) là gì? Nêu 2 nguyên nhân có thể gây ra nó.
Hậu quả của việc bỏ qua quá phân tán khi dùng mô hình Poisson là gì?
So sánh mô hình Quasi-Poisson và Negative Binomial.
Lạm phát số không (zero-inflation) là gì?
Hệ số \(\exp(\beta_k) = 0.75\) trong một mô hình Poisson có nghĩa là gì?
7.9.2 Bài tập thực hành với R
Dữ liệu quine: Sử dụng dữ liệu quine từ gói MASS.
Xây dựng mô hình Poisson dự báo số ngày nghỉ học (Days) dựa trên Eth và Sex.
Kiểm tra quá phân tán.
Xây dựng mô hình NB và so sánh kết quả với mô hình Poisson (sai số chuẩn, ý nghĩa biến).
Dữ liệu DebTrivedi: Sử dụng dữ liệu DebTrivedi từ gói AER. Dữ liệu này về việc sử dụng dịch vụ y tế.
Hãy mô hình hóa số lần khám bác sĩ (ofp) dựa trên health (tình trạng sức khỏe) và numchron (số bệnh mãn tính).
Bắt đầu với mô hình Poisson, kiểm tra các giả định, và chọn mô hình phù hợp nhất (Poisson, Quasi-Poisson, hay NB).
Diễn giải các hệ số của mô hình cuối cùng bạn chọn.
Mô hình có Offset: Giả sử bạn có dữ liệu về số ca cúm (flu_cases) và dân số (population) của 50 thành phố.
Tạo dữ liệu giả lập cho flu_cases, population, và một biến vaccination_rate (tỷ lệ tiêm chủng).
Xây dựng mô hình Poisson để dự báo flu_cases, sử dụng log(population) làm offset. Biến độc lập là vaccination_rate.
Diễn giải hệ số của vaccination_rate.
7.10 Tài liệu tham khảo
Cameron, A. C., & Trivedi, P. K. (2013). Regression Analysis of Count Data. Cambridge University Press.
Hilbe, J. M. (2014). Modeling Count Data. Cambridge University Press.
Zeileis, A., Kleiber, C., & Jackman, S. (2008). Regression Models for Count Data in R. Journal of Statistical Software, 27(8), 1–25.
Các tài liệu hướng dẫn của gói R: MASS, AER, pscl, glmmTMB.