Sau khi hoàn thành chương này, người học sẽ có khả năng:
Hiểu rõ khái niệm, đặc điểm và vai trò của dữ liệu định tính.
Phân biệt các loại thang đo lường cho biến định tính.
Nắm vững các phân phối xác suất cơ bản cho biến định tính đơn lẻ.
Làm quen với môi trường R và RStudio, thực hiện các thao tác cơ bản và cài đặt các gói cần thiết cho phân tích dữ liệu định tính.
Biết cách tìm kiếm và sử dụng các nguồn dữ liệu định tính.
2.1 Giới thiệu dữ liệu định tính
Trong nghiên cứu khoa học nói chung và các lĩnh vực kinh tế, kinh doanh, tài chính nói riêng, dữ liệu (data) là tập hợp các thông tin thu thập được về một hoặc nhiều đối tượng nghiên cứu. Dữ liệu có thể tồn tại dưới nhiều dạng thức khác nhau, và một trong những cách phân loại cơ bản nhất là dựa trên bản chất của thông tin mà dữ liệu sẽ biểu thị đó là: dữ liệu định tính và dữ liệu định lượng.
2.1.1 Định nghĩa dữ liệu định tính
Dữ liệu định tính (Qualitative Data hay Categorical Data) là loại dữ liệu mô tả các đặc điểm, thuộc tính, phẩm chất hoặc phân loại của đối tượng nghiên cứu mà không thể đo lường trực tiếp bằng các con số có ý nghĩa toán học, nghĩa là có thông thực hiện được các phép toán hoặc phép so sánh hơn kém trên loại dữ liệu này. Thay vào đó, dữ liệu định tính thường được biểu thị bằng tên gọi (names), bằng ký hiệu (symbol) hoặc các mã số quy ước (codes) đại diện cho các phạm trù (categories) hoặc nhóm (groups) khác nhau.
Dữ liệu định tính thường được sử dụng để phân loại, mô tả hoặc phân tích các thuộc tính không thể đo lường bằng số, và thường được thu thập thông qua các phương pháp như khảo sát, phỏng vấn, quan sát, hoặc phân tích nội dung.
Ví dụ:
Giới tính của khách hàng: Nam, Nữ, Khác.
Trình độ học vấn của nhân viên: Trung học, Cao đẳng, Đại học, Sau đại học.
Loại hình doanh nghiệp: Tư nhân, Nhà nước, Cổ phần, Liên doanh.
Mức độ hài lòng của người tiêu dùng về một sản phẩm: Rất không hài lòng, Không hài lòng, Bình thường, Hài lòng, Rất hài lòng.
Ngành nghề kinh doanh: Sản xuất, Dịch vụ, Nông nghiệp, Tài chính.
Quốc gia phát hành trái phiếu: Việt Nam, Mỹ, Nhật Bản.
Mặc dù dữ liệu định tính không mang giá trị số học trực tiếp nhưng chúng ta vẫn có thể thực hiện các phép đếm tần số xuất hiện của mỗi phạm trù, tính toán tỷ lệ phần trăm, và sử dụng các phương pháp thống kê chuyên biệt để khám phá mối quan hệ của dữ liệu này với dữ liệu khác và đưa ra các suy diễn có ý nghĩa.
2.1.2 Tầm quan trọng của phân tích dữ liệu định tính
Trong một thế giới ngày càng phức tạp và rất nhiều quyết định được đưa ra đều dựa trên dữ liệu, việc bỏ qua thông tin từ dữ liệu định tính đồng nghĩa với việc bỏ lỡ những hiểu biết quan trọng. Phân tích dữ liệu định tính đóng vai trò then chốt trong nhiều khía cạnh:
Hiểu biết sâu sắc về khách hàng và thị trường:
Phân khúc thị trường: Dữ liệu về giới tính, độ tuổi (nhóm tuổi), vị trí địa lý, sở thích, phong cách sống,… (tất cả đều có thể là biến định tính) sẽ giúp doanh nghiệp phân chia thị trường thành các nhóm nhỏ hơn để có chiến lược marketing mục tiêu hiệu quả hơn.
Hành vi người tiêu dùng: Phân tích phản hồi khảo sát (mức độ hài lòng, ý định mua hàng, lý do lựa chọn sản phẩm,…) giúp doanh nghiệp cải thiện sản phẩm, dịch vụ và trải nghiệm khách hàng. Ví dụ: Một ngân hàng có thể phân tích dữ liệu về “Loại tài khoản tiết kiệm” (Không kỳ hạn, 3 tháng, 6 tháng, 12 tháng) và “Mục đích gửi tiền” (Mua nhà, Du học, Đầu tư) để thiết kế các sản phẩm tiết kiệm phù hợp hơn.
Quản trị nguồn nhân lực hiệu quả:
Đánh giá hiệu suất: Dữ liệu về “Xếp loại nhân viên” (Xuất sắc, Tốt, Khá, Cần cải thiện) hay “Lý do nghỉ việc” (Lương, Môi trường, Cơ hội phát triển) là đầu vào quan trọng cho việc xây dựng chính sách nhân sự.
Đào tạo và phát triển: Xác định nhu cầu đào tạo dựa trên “Kỹ năng hiện tại” hoặc “Vị trí công việc”. Ví dụ: Một công ty sử dụng dữ liệu khảo sát về “Mức độ gắn kết của nhân viên” (thang đo định tính) để triển khai các chương trình cải thiện môi trường làm việc.
Quản lý rủi ro và ra quyết định tài chính:
Đánh giá tín dụng: Các yếu tố định tính như “Lịch sử tín dụng” (Tốt, Xấu, Chưa có), “Ngành nghề của người vay” có thể được sử dụng trong mô hình chấm điểm tín dụng bên cạnh các yếu tố định lượng.
Phân tích ngành: “Triển vọng ngành” (Tăng trưởng cao, Ổn định, Suy giảm) là một yếu tố định tính quan trọng khi đưa ra quyết định đầu tư. Ví dụ: Các quỹ đầu tư mạo hiểm thường đánh giá “Chất lượng đội ngũ quản lý” (một biến định tính) của một startup trước khi quyết định rót vốn.
Nghiên cứu và phát triển chính sách kinh tế:
Đánh giá tác động chính sách: Chính phủ có thể thu thập dữ liệu về “Mức độ ảnh hưởng của chính sách X đến doanh nghiệp” (Tích cực, Tiêu cực, Không ảnh hưởng) để điều chỉnh cho phù hợp.
Phân tích tình hình kinh tế xã hội: Các chỉ số như “Tình trạng việc làm” (Có việc làm, Thất nghiệp, Ngoài lực lượng lao động) cung cấp cái nhìn toàn diện về nền kinh tế.
Như vậy, khả năng thu thập, xử lý và phân tích dữ liệu định tính một cách khoa học giúp các cá nhân và tổ chức đưa ra quyết định sáng suốt hơn, tối ưu hóa hoạt động và đạt được lợi thế cạnh tranh.
2.1.3 Phân biệt dữ liệu định tính và dữ liệu định lượng
Để hiểu rõ hơn về dữ liệu định tính, việc so sánh nó với dữ liệu định lượng là cần thiết, qua việc so sánh này sẽ giúp chúng ta nhận diện được các đặc điểm riêng biệt của từng loại dữ liệu.
Dữ liệu định lượng (Quantitative Data) là loại dữ liệu được biểu thị bằng các con số có ý nghĩa toán học, các con số này phản ánh số lượng, mức độ hoặc kích thước của một đối tượng hay hiện tượng. Các phép toán số học (cộng, trừ, nhân, chia, tính trung bình) có thể được áp dụng trực tiếp lên dữ liệu định lượng.
Bảng dưới đây sẽ tóm tắt những điểm khác biệt chính giữa dữ liệu định tính và dữ liệu định lượng:
Đặc điểm
Dữ liệu Định tính (Qualitative Data)
Dữ liệu Định lượng (Quantitative Data)
Bản chất
Mô tả thuộc tính, đặc điểm, phân loại
Đo lường số lượng, kích thước, mức độ
Biểu thị
tên, ký hiệu, mã hóa quy ước
Con số có ý nghĩa toán học
Thang đo
Thường là Danh nghĩa, Thứ bậc
Thường là Khoảng, Tỷ lệ
Phép toán
Đếm tần số, tính tỷ lệ. Các phép toán số học trực tiếp thường không có ý nghĩa.
Cộng, trừ, nhân, chia, trung bình, phương sai, v.v.
Câu hỏi
“Là gì?”, “Loại nào?”, “Như thế nào?”
“Bao nhiêu?”, “Mức độ nào?”
Ví dụ
Giới tính, Màu sắc, Thương hiệu, Mức độ hài lòng
Tuổi, Thu nhập, Giá cổ phiếu, Số lượng sản phẩm bán ra
Phân tích
Phân tích tần số, bảng chéo, mô hình logit, probit, log-linear, v.v.
Thống kê mô tả (trung bình, độ lệch chuẩn), hồi quy tuyến tính, phân tích phương sai, v.v.
Lưu ý: Đôi khi, các phạm trù của dữ liệu định tính có thể được mã hóa bằng số (ví dụ: Nam = 1, Nữ = 0). Tuy nhiên, những con số này chỉ mang tính đại diện, không thể thực hiện các phép toán như thể chúng là dữ liệu định lượng thực sự (ví dụ: không thể nói trung bình giới tính là 0.5 có ý nghĩa gì). Ngược lại, dữ liệu định lượng có thể được chuyển đổi thành dữ liệu định tính thông qua việc nhóm hoặc phân loại (ví dụ: biến “Thu nhập” (định lượng) có thể được chuyển thành “Nhóm thu nhập”: Thấp, Trung bình, Cao (định tính)). Việc chuyển đổi này cần được cân nhắc cẩn thận vì nó có thể làm mất thông tin.
2.2 Các thang đo cho biến định tính
Trong thống kê, thang đo (scales of measurement) là công cụ được sử dụng để định nghĩa và phân loại các biến thống kê hoặc chúng ta cũng có thể phân loại dữ liệu thành các loại khác nhau dựa trên một thang đo cụ thể. Đối với dữ liệu định tính, việc xác định thang đo là rất quan trọng vì nó ảnh hưởng đến cách chúng ta phân tích và diễn giải dữ liệu. Đối với dữ liệu định tính, có hai loại thang đo chính:
2.2.1 Thang đo danh nghĩa
Thang đo danh nghĩa (Nominal Scale) được sử dụng để phân loại các đối tượng thành các phạm trù riêng biệt, không trùng lặp và không có bất kỳ sự hơn kém hay thứ tự tự nhiên nào giữa các phạm trù đó. Các phạm trù chỉ đơn thuần là những cái tên hay các ký hiệu khác nhau.
Đặc điểm:
Các phạm trù là phân biệt và loại trừ lẫn nhau (một đối tượng chỉ thuộc về một phạm trù).
Không có ý nghĩa về thứ tự, khoảng cách hay tỷ lệ giữa các phạm trù.
Phép toán thống kê phù hợp: đếm tần số, tính tỷ lệ/phần trăm, tìm yếu vị (mode), kiểm định chi-bình phương.
Ví dụ:
Màu sắc yêu thích: Xanh, Đỏ, Vàng, Tím.
Tình trạng hôn nhân: Độc thân, Đã kết hôn, Ly hôn, Góa.
Loại hình sản phẩm: Điện thoại, Máy tính bảng, Laptop.
Phương thức thanh toán: Tiền mặt, Thẻ tín dụng, Chuyển khoản, Ví điện tử.
Mã cổ phiếu trên sàn giao dịch: VNM, HPG, FPT.
Khi mã hóa dữ liệu danh nghĩa bằng số, các con số này chỉ đơn thuần là mã định danh, không thể so sánh hơn kém. Ví dụ, với biến Hình thức thanh toán nếu mã hóa “Tiền mặt = 1”, “Thẻ tín dụng = 2”, không có nghĩa là thẻ tín dụng “tốt hơn gấp đôi” tiền mặt.
2.2.2 Thang đo thứ bậc
Thang đo thứ bậc (Ordinal Scale) cũng phân loại các đối tượng vào các phạm trù riêng biệt, nhưng khác với thang đo danh nghĩa, các phạm trù này có một trật tự tự nhiên hoặc một sự xếp hạng (ranking) nhất định. Chúng ta có thể nói phạm trù này “cao hơn”, “tốt hơn”, “nhiều hơn” phạm trù kia, nhưng không thể xác định được chính xác “khoảng cách” hay “mức độ khác biệt” giữa chúng là bao nhiêu.
Đặc điểm:
Các phạm trù là phân biệt, loại trừ lẫn nhau và có thứ tự.
Biết được thứ hạng tương đối, nhưng không biết được khoảng cách chính xác giữa các thứ hạng.
Phép toán thống kê phù hợp: Ngoài các phép toán cho thang danh nghĩa, có thể tìm trung vị (median), tứ phân vị, các kiểm định dựa trên thứ hạng (rank-based tests), các thước đo liên hệ thứ bậc (Spearman’s rho, Kendall’s tau).
Ví dụ:
Mức độ hài lòng của khách hàng: Rất không hài lòng < Không hài lòng < Bình thường < Hài lòng < Rất hài lòng.
Trình độ học vấn (theo thứ tự tăng dần): Tiểu học < Trung học cơ sở < Trung học phổ thông < Cao đẳng < Đại học < Sau đại học.
Xếp hạng tín dụng của doanh nghiệp: AAA > AA > A > BBB > BB > B > CCC.
Đánh giá rủi ro đầu tư: Thấp < Trung bình < Cao.
Tần suất sử dụng dịch vụ: Không bao giờ < Hiếm khi < Thỉnh thoảng < Thường xuyên < Rất thường xuyên.
Mặc dù có thứ tự, nhưng khoảng cách giữa các bậc là không nhất thiết bằng nhau. Ví dụ, sự khác biệt về “mức độ hài lòng” giữa “Hài lòng” và “Rất hài lòng” có thể không giống với sự khác biệt giữa “Bình thường” và “Hài lòng”. Đây là điểm khác biệt quan trọng so với thang đo khoảng.
2.2.3 Phân biệt thang đo khoảngvà thang đo tỷ lệ
Để hoàn thiện bức tranh về các thang đo, chúng ta cần nhắc lại một cách ngắn gọn về thang đo khoảng (Interval) và thang đo tỷ lệ (Ratio), vốn thường được áp dụng cho dữ liệu định lượng.
Thang đo khoảng (Interval Scale):
Có tất cả các đặc điểm của thang đo thứ bậc (phân biệt, có thứ tự).
Ngoài ra, khoảng cách giữa các giá trị liên tiếp là bằng nhau và có ý nghĩa. Điều này cho phép thực hiện các phép cộng, trừ.
Không có điểm 0 tuyệt đối (zero point is arbitrary). Nghĩa là, giá trị 0 không có nghĩa là “không có” thuộc tính đó. Do đó, phép nhân và chia trực tiếp (để nói gấp bao nhiêu lần) thường không có ý nghĩa.
Ví dụ:
Nhiệt độ theo độ C hoặc độ F: Khoảng cách từ \(10^o\)C đến \(20^o\)C bằng khoảng cách từ \(20^o\)C đến \(30^o\)C (đều là \(10^o\)C). Nhưng \(20^o\)C không có nghĩa là nóng gấp đôi \(10^o\)C. Điểm \(0^o\)C không có nghĩa là không có nhiệt độ.
Năm lịch: Năm 2000 cách năm 1990 là 10 năm. Không có “năm 0” mang ý nghĩa tuyệt đối.
Điểm số IQ: Một người có IQ 120 không thông minh gấp đôi người có IQ 60.
Thang đo tỷ lệ (Ratio Scale):
Đây là thang đo tổng quát nhất, thang đo này có tất cả các đặc điểm của thang đo khoảng (phân biệt, có thứ tự, khoảng cách bằng nhau).
Quan trọng nhất, nó có một điểm 0 tuyệt đối (true zero point), có nghĩa là tại giá trị 0, thuộc tính đang đo lường thực sự không tồn tại.
Điều này cho phép thực hiện tất cả các phép toán số học, bao gồm cả phép nhân và chia để so sánh tỷ lệ (ví dụ, “gấp đôi”, “một nửa”).
Ví dụ:
Thu nhập: Thu nhập 0 đồng nghĩa là không có thu nhập. Một người có thu nhập 50 triệu đồng kiếm được gấp đôi người có thu nhập 25 triệu đồng.
Tuổi: Tuổi 0 là lúc mới sinh.
Số lượng sản phẩm bán ra: 0 sản phẩm nghĩa là không bán được sản phẩm nào.
Giá cổ phiếu: Giá 0 (mặc dù hiếm) có nghĩa là cổ phiếu không có giá trị.
Cân nặng, chiều cao, thời gian.
Tóm lại:
Thang đo Danh nghĩa: Chỉ được dùng để phân loại.
Thang đo Thứ bậc: Được đùng để phân loại và có thứ tự.
Thang đo khoảng: Được dùng để phân loại, có thứ tự và có khoảng cách đều nhau.
Thang đo Tỷ lệ: Được dùng để Phân loại, có thứ tự, có khoảng cách đều nhau và có điểm 0 tuyệt đối.
Việc nhận diện đúng thang đo của biến là bước đầu tiên và cơ bản để lựa chọn phương pháp phân tích thống kê phù hợp, đảm bảo tính hợp lệ và ý nghĩa của kết quả nghiên cứu. Trong giáo trình này, chúng ta sẽ tập trung vào các phương pháp phân tích cho dữ liệu ở thang đo danh nghĩa và thứ bậc.
2.3 Phân phối xác suất cho biến định tính
Khi nghiên cứu một biến định tính, chúng ta thường quan tâm đến tần suất xuất hiện của mỗi phạm trù trong tổng thể hoặc mẫu. Các phân phối xác suất cung cấp một khung lý thuyết để mô tả sự không chắc chắn liên quan đến kết quả của biến định tính đó. Ba phân phối xác suất cơ bản thường gặp nhất khi làm việc với biến định tínhlà Bernoulli, Nhị thức và Đa thức.
2.3.1 Phân phối Bernoulli
Phân phối Bernoulli (Bernoulli Distribution) là phân phối xác suất đơn giản nhất cho một biến định tính chỉ có hai kết quả có thể xảy ra, thường được gọi là “thành công” và “thất bại”.
Thí nghiệm Bernoulli: Một thử nghiệm ngẫu nhiên chỉ có hai kết quả đối lập nhau.
Ví dụ: Tung một đồng xu (sấp hoặc ngửa), một sản phẩm có bị lỗi hay không, một khách hàng có mua hàng hay không, một khoản vay có bị vỡ nợ hay không.
Biến ngẫu nhiên Bernoulli: Một biến ngẫu nhiên \(X\) nhận giá trị 1 (đại diện cho “thành công”) với xác suất \(p\), và nhận giá trị 0 (đại diện cho “thất bại”) với xác suất \(1-p\).
\(P(X=1) = p\)
\(P(X=0) = 1-p\) trong đó \(0 \le p \le 1\).
Hàm khối lượng xác suất (Probability Mass Function - PMF):\[f(k; p) = P(X=k) = p^k (1-p)^{1-k} \text{ với } k \in \{0, 1\}\]
Các tham số đặc trưng:
Kỳ vọng (Expected Value): \(E[X] = p\)
Phương sai (Variance): \(Var(X) = p(1-p)\)
Ví dụ:
Một công ty phát hành cổ phiếu lần đầu ra công chúng (IPO). Gọi \(X=1\) nếu giá cổ phiếu tăng trong ngày giao dịch đầu tiên (thành công), \(X=0\) nếu không tăng. Nếu xác suất giá tăng là \(p=0.6\), thì \(P(X=1) = 0.6\) và \(P(X=0) = 0.4\).
Một nhân viên bán hàng tiếp cận một khách hàng tiềm năng để bán hàng. Gọi \(Y=1\) nếu khách hàng đồng ý mua sản phẩm, \(Y=0\) nếu khách hàng từ chối.
2.3.2 Phân phối Nhị thức
Phân phối Nhị thức (Binomial Distribution) mô tả số lần “thành công” trong một chuỗi \(n\) phép thử Bernoulli độc lập và giống hệt nhau (cùng xác suất thành công \(p\) cho mỗi phép thử).
Điều kiện để một biến ngẫu nhiên tuân theo phân phối Nhị thức:
Thực hiện \(n\) phép thử lặp lại.
Mỗi phép thử chỉ có hai kết quả (thành công hoặc thất bại).
Xác suất thành công \(p\) là không đổi cho mỗi phép thử.
Các phép thử là độc lập với nhau.
Biến ngẫu nhiên Nhị thức:\(X \sim B(n, p)\) là số lần thành công trong \(n\) phép thử. \(X\) có thể nhận các giá trị từ \(0, 1, 2, ..., n\).
Hàm khối lượng xác suất (PMF):\[P(X=k) = \frac{n!}{k!(n-k)!} p^k (1-p)^{n-k}\] với \(k = 0, 1, 2, \dots, n\).
Các tham số đặc trưng:
Kỳ vọng: \(E[X] = np\)
Phương sai: \(Var(X) = np(1-p)\)
Mối liên hệ với phân phối Bernoulli: Phân phối Bernoulli là trường hợp đặc biệt của phân phối Nhị thức khi \(n=1\), tức là \(B(1, p)\).
Ví dụ:
Một ngân hàng khảo sát 100 khách hàng (\(n=100\)) đã vay vốn. Giả sử xác suất một khách hàng trả nợ đúng hạn (thành công) là \(p=0.9\). Số khách hàng trả nợ đúng hạn trong 100 khách hàng này sẽ tuân theo phân phối \(B(100, 0.9)\).
Một nhà máy sản xuất bóng đèn. Tỷ lệ bóng đèn lỗi (thành công, nếu “lỗi” được coi là sự kiện quan tâm) là \(p=0.05\). Kiểm tra ngẫu nhiên 20 bóng đèn (\(n=20\)). Số bóng đèn lỗi trong 20 bóng này tuân theo \(B(20, 0.05)\).
Minh họa bằng R:
Ngôn ngữ R cung cấp các hàm để làm việc với phân phối Nhị thức như sau:
dbinom(k, size=n, prob=p): Tính \(P(X=k)\).
pbinom(q, size=n, prob=p): Tính \(P(X \le q)\) (hàm phân phối tích lũy - CDF).
qbinom(probVal, size=n, prob=p): Tìm giá trị \(q\) nhỏ nhất sao cho \(P(X \le q) \ge \text{probVal}\) (hàm ngược của CDF).
rbinom(m, size=n, prob=p): Sinh \(m\) số ngẫu nhiên từ phân phối \(B(n, p)\).
# Ví dụ 1: Tính xác suất có đúng 5 khách hàng trả nợ đúng hạn# trong 10 khách hàng được chọn,#biết xác suất mỗi khách hàng trả đúng hạn là 0.9.# Sử dụng phân phối Nhị thức B(n = 10, p = 0.9)# X ~ B(n = 10, p = 0.9)# Tính P(X = 5)prob_X_eq_5 <-dbinom(x =5, size =10, prob =0.9)# Ví dụ 2: Tính xác suất có ít nhất 8 khách hàng trả nợ đúng hạn.# P(X >= 8) = P(X=8) + P(X=9) + P(X=10)# Hoặc P(X >= 8) = 1 - P(X <= 7)prob_X_ge_8 <-1-pbinom(q =7, size =10, prob =0.9)# Cách khác:prob_X_ge_8_alt <-sum(dbinom(x =8:10, size =10, prob =0.9))# Ví dụ 3: Sinh 20 mẫu ngẫu nhiên từ phân phối B(10, 0.9)set.seed(123) # Để kết quả có thể tái lặprandom_samples <-rbinom(n =20, size =10, prob =0.9)
Chúng ta có thể vẽ đồ thị hàm khối xác suất của phân phối Nhị thức:
Code
# Vẽ đồ thị PMF của B(n=10, p=0.9)n_trials <-10p_success <-0.9k_values <-0:n_trialspmf_values <-dbinom(k_values, size = n_trials, prob = p_success)# Lưu hình ảnh (nếu cần)png(filename="images/Hình 1.1.png", width=800, height=600) # # Chúng ta sẽ để Quarto tự xử lý việc lưu hình khi renderbarplot(pmf_values, names.arg = k_values, xlab ="Số lần thành công (k)", ylab ="Xác suất P(X=k)",main =paste("Hàm khối lượng xác suất của Phân phối Nhị thức B(", n_trials, ", ", p_success, ")", sep=""),col ="skyblue",border ="black")dev.off() # Nếu đã dùng png()
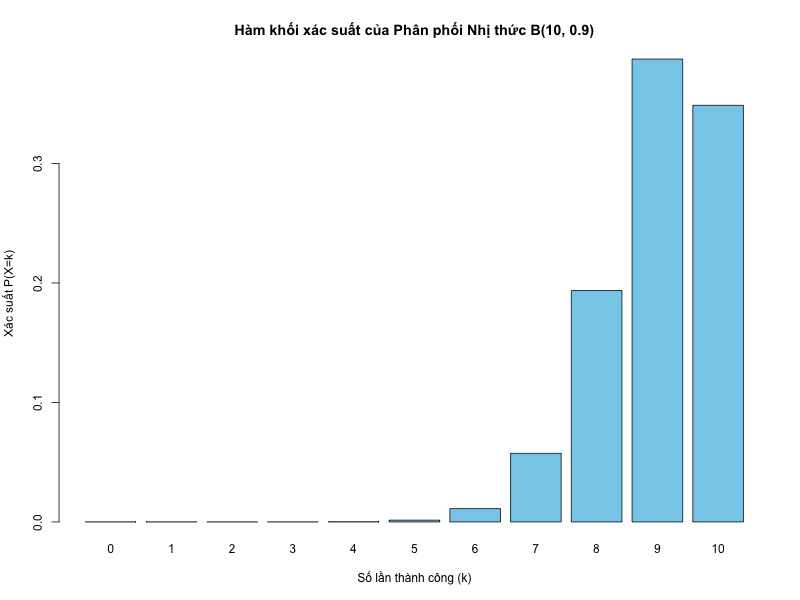
Đồ thị này được tạo ra từ đoạn mã R trên, minh họa xác suất tương ứng với số lần thành công (từ 0 đến 10) trong 10 lần thử với xác suất thành công trong từng lần thử là 0.9. Nhìn đồ thị chúng ta có thể thấy, xác suất cao nhất tập trung quanh giá trị kỳ vọng \(E[X] = np = 10 \times 0.9 = 9\).
2.3.3 Phân phối Đa thức
Phân phối Đa thức (Multinomial Distribution) là sự mở rộng của phân phối Nhị thức khi mỗi phép thử có nhiều hơn hai kết quả có thể xảy ra (tức là biến định tính có nhiều hơn hai phạm trù).
Phép thử Đa thức:
Thực hiện \(n\) phép thử lặp lại độc lập.
Mỗi phép thử có \(J\) kết quả (phạm trù) có thể xảy ra, \(E_1, E_2, ..., E_J\).
Xác suất xảy ra kết quả \(E_j\) trong một phép thử là \(p_j\), với \(p_j \ge 0\) và \(\sum_{j=1}^{J} p_j = 1\). Các xác suất này không đổi qua các phép thử.
Biến ngẫu nhiên Đa thức: Gọi \(X_j\) là số lần kết quả \(E_j\) xuất hiện trong \(n\) phép thử. Vector \((X_1, X_2, ..., X_J)\) tuân theo phân phối Đa thức, với \(\sum_{j=1}^{J} X_j = n\).
Mối liên hệ với phân phối Nhị thức: Nếu chỉ có \(J=2\) kết quả, phân phối Đa thức trở thành phân phối Nhị thức. \(X_1 \sim B(n, p_1)\) và \(X_2 = n - X_1\).
Ví dụ:
Khảo sát 1000 cử tri (\(n=1000\)) về việc họ sẽ bỏ phiếu cho ứng cử viên nào trong số 3 ứng cử viên A, B, C (\(J=3\)). Giả sử tỷ lệ ủng hộ tương ứng là \(p_A=0.4\), \(p_B=0.35\), \(p_C=0.25\). Số phiếu mỗi ứng cử viên nhận được \((X_A, X_B, X_C)\) sẽ tuân theo phân phối Đa thức.
Một nhà quản lý quỹ đầu tư phân bổ danh mục vào 4 loại tài sản (\(J=4\)): Cổ phiếu (40%), Trái phiếu (30%), Bất động sản (20%), Vàng (10%). Chọn ngẫu nhiên 50 khoản đầu tư (\(n=50\)) từ danh mục của một nhóm khách hàng lớn có cùng chiến lược phân bổ. Số lượng khoản đầu tư rơi vào mỗi loại tài sản \((X_{CP}, X_{TP}, X_{BDS}, X_{Vang})\) sẽ tuân theo phân phối Đa thức.
Minh họa bằng R:
Gói stats trong R (đã được cài đặt và kích hoạt mặc định) có hàm rmultinom(m, size=n, prob=vector_p) để sinh \(m\) bộ mẫu ngẫu nhiên từ phân phối Đa thức. Việc tính chính xác PMF (dmultinom()) cũng có sẵn.
# Ví dụ: Tính xác suất P(X_A=40, X_B=35, X_C=25) # khi n=100, p=(0.4, 0.35, 0.25)observed_counts <-c(40, 35, 25)n_total_obs_multinom <-100probs_categories_multinom <-c(0.4, 0.35, 0.25)prob_multinom_specific <-dmultinom(x = observed_counts, size = n_total_obs_multinom, prob = probs_categories_multinom)# Sinh 5 mẫu ngẫu nhiên từ phân phối Đa thứcset.seed(456) # Để kết quả có thể tái lặpnum_samples_multinom <-5multinom_samples <-rmultinom(n = num_samples_multinom, size = n_total_obs_multinom, prob = probs_categories_multinom)# Đặt tên hàng cho dễ nhìnrownames(multinom_samples) <-c("Ứng viên A", "Ứng viên B", "Ứng viên C")colnames(multinom_samples) <-paste("Mẫu", 1:num_samples_multinom)
Kết quả sinh mẫu cho thấy trong mỗi lần “lấy mẫu” 100 cử tri, số lượng phiếu cho mỗi ứng viên sẽ dao động quanh giá trị kỳ vọng của họ (\(100 \times 0.4 = 40\) cho A, \(100 \times 0.35 = 35\) cho B, \(100 \times 0.25 = 25\) cho C), nhưng có sự ngẫu nhiên nhất định.
Việc hiểu các phân phối xác suất này là nền tảng để thực hiện suy diễn thống kê cho dữ liệu định tính, ví dụ như kiểm định giả thuyết về tỷ lệ hoặc ước lượng khoảng tin cậy cho tỷ lệ, mà chúng ta sẽ tìm hiểu sâu hơn ở các chương sau.
2.4 Giới thiệu cơ bản về ngôn ngữ R và RStudio
Để thực hiện phân tích dữ liệu định tính một cách hiệu quả và hiện đại, chúng ta sẽ sử dụng R, một ngôn ngữ lập trình và môi trường làm việc tích hợp miễn phí, mã nguồn mở, chuyên dụng cho tính toán thống kê và đồ họa. R được phát triển bởi Ross Ihaka và Robert Gentleman tại Đại học Auckland, New Zealand, và hiện nay được duy trì và phát triển bởi một cộng đồng lớn các nhà thống kê và khoa học dữ liệu trên toàn thế giới. Đi kèm với R là RStudio, một môi trường phát triển tích hợp (Integrated Development Environment - IDE) giúp việc sử dụng R trở nên thuận tiện và trực quan hơn rất nhiều.
Tại sao chọn R? * Miễn phí và mã nguồn mở: Ai cũng có thể sử dụng và đóng góp. * Mạnh mẽ và linh hoạt: Cung cấp vô số các công cụ thống kê từ cơ bản đến nâng cao, đặc biệt mạnh cho phân tích dữ liệu. * Khả năng đồ họa xuất sắc: Tạo ra các biểu đồ chất lượng cao, tùy biến linh hoạt. * Cộng đồng lớn mạnh: Hàng ngàn gói (packages) mở rộng chức năng, cùng với sự hỗ trợ lớn từ cộng đồng người dùng. * Tiêu chuẩn trong nghiên cứu: Ngày càng nhiều trường đại học và viện nghiên cứu sử dụng R làm công cụ chính. * Khả năng tái lặp nghiên cứu: Mã lệnh R giúp ghi lại toàn bộ quy trình phân tích, dễ dàng kiểm tra và tái lặp.
2.4.1 Cài đặt R và RStudio
Việc cài đặt R và RStudio tương đối đơn giản. Bạn cần cài đặt R trước, sau đó mới đến RStudio.
Tải xuống phiên bản RStudio Desktop miễn phí phù hợp với hệ điều hành của bạn.
Chạy file cài đặt và làm theo các hướng dẫn mặc định.
Sau khi cài đặt xong, bạn chỉ cần khởi động RStudio. RStudio sẽ tự động nhận diện phiên bản R đã được cài đặt trên máy của bạn.
2.4.2 Giao diện RStudio và các thao tác cơ bản
Khi mở RStudio, bạn sẽ thấy một giao diện thường được chia thành bốn khung (panes) chính (có thể tùy chỉnh bố cục):
Khung trên trái (Source Editor): Đây là nơi bạn viết và chỉnh sửa các mã lệnh R (scripts, thường có đuôi .R), tài liệu R Markdown (như file này, đuôi .qmd hoặc .Rmd), xem dữ liệu dạng bảng, v.v. Bạn có thể mở nhiều file cùng lúc dưới dạng các tab.
Để chạy một dòng lệnh từ script, đặt con trỏ vào dòng đó và nhấn Ctrl + Enter (hoặc Cmd + Enter trên macOS).
Để chạy toàn bộ đoạn lệnh đã chọn, chọn chúng và nhấn Ctrl + Enter.
Khung dưới trái (Console): Đây là nơi các lệnh R được thực thi và kết quả được hiển thị. Bạn cũng có thể gõ lệnh trực tiếp vào Console và nhấn Enter để chạy. Dấu nhắc > cho biết R đã sẵn sàng nhận lệnh.
Khung trên phải (Environment/History/Connections/Tutorial/Git):
Environment: Hiển thị tất cả các đối tượng (biến, hàm, dữ liệu) mà bạn đã tạo hoặc tải vào trong phiên làm việc hiện tại của R.
History: Liệt kê các lệnh R đã được chạy trước đó.
Connections: Quản lý kết nối tới các cơ sở dữ liệu.
Git: Nếu bạn sử dụng Git để quản lý phiên bản, khung này sẽ hiển thị thông tin liên quan.
Khung dưới phải (Files/Plots/Packages/Help/Viewer):
Files: Hiển thị cây thư mục, cho phép bạn duyệt file và thư mục trên máy tính.
Plots: Nơi hiển thị các đồ thị và biểu đồ được tạo ra bởi R.
Packages: Liệt kê tất cả các gói R đã được cài đặt. Bạn có thể tải (load) hoặc gỡ tải (unload) các gói từ đây, cũng như cài đặt gói mới.
Help: Cung cấp tài liệu hướng dẫn cho các hàm và gói R. Bạn có thể gõ ?tên_hàm hoặc help(tên_hàm) trong Console để xem hướng dẫn.
Viewer: Hiển thị nội dung web cục bộ, ví dụ như các đồ thị tương tác.
Một số thao tác cơ bản: * Tạo script mới: File > New File > R Script (hoặc Ctrl+Shift+N). * Mở script đã có: File > Open File… * Lưu script: File > Save (hoặc Ctrl+S). * Thiết lập thư mục làm việc (Working Directory): Đây là thư mục mà R sẽ đọc file từ đó và lưu file vào đó theo mặc định. * Session > Set Working Directory > Choose Directory… * Hoặc dùng lệnh setwd("đường_dẫn_tới_thư_mục") trong Console. * Xem thư mục làm việc hiện tại:getwd() * Dọn dẹp Console:Ctrl+L * Thoát RStudio: File > Quit Session (RStudio sẽ hỏi bạn có muốn lưu không gian làm việc .RData không, thường thì chọn “Don’t Save” để bắt đầu một phiên làm việc mới sạch sẽ lần sau).
2.4.3 Các kiểu dữ liệu cơ bản trong R
R có nhiều cấu trúc dữ liệu để lưu trữ các loại thông tin khác nhau. Dưới đây là một số kiểu cơ bản nhất:
Vector:
Là cấu trúc dữ liệu một chiều, chứa một chuỗi các phần tử cùng kiểu dữ liệu (ví dụ: tất cả là số, tất cả là ký tự, hoặc tất cả là logic).
Truy cập phần tử trong vector: dùng chỉ số (index) trong dấu ngoặc vuông []. R đánh chỉ số từ 1.
print(ten_thanh_pho[1]) # Phần tử đầu tiênprint(so_nguyen[2:4]) # Phần tử từ 2 đến 4print(so_nguyen[c(1, 3, 5)]) # Phần tử 1, 3, 5
Matrix (Ma trận):
Là cấu trúc dữ liệu hai chiều (hàng và cột), tất cả các phần tử cũng phải cùng kiểu dữ liệu.
Tạo ma trận bằng hàm matrix().
# Tạo ma trận 2x3 từ một vector 6 phần tửdu_lieu_ma_tran <-1:6ma_tran_A <-matrix(data = du_lieu_ma_tran, nrow =2, ncol =3, byrow =TRUE) # byrow=TRUE: điền theo hàngprint(ma_tran_A)# Truy cập phần tử: ma_tran[hàng, cột]print(ma_tran_A[1, 2]) # Phần tử ở hàng 1, cột 2print(ma_tran_A[1, ]) # Toàn bộ hàng 1print(ma_tran_A[, 3]) # Toàn bộ cột 3
Data Frame (Khung dữ liệu):
Là cấu trúc dữ liệu hai chiều (hàng và cột), tương tự như một bảng trong Excel hoặc cơ sở dữ liệu.
Quan trọng: Các cột trong data frame có thể chứa các kiểu dữ liệu khác nhau (ví dụ: cột 1 là số, cột 2 là ký tự, cột 3 là logic), nhưng mỗi cột phải chứa các phần tử cùng kiểu.
Đây là cấu trúc dữ liệu phổ biến nhất để lưu trữ bộ dữ liệu phân tích trong R.
Tạo data frame bằng hàm data.frame().
# Tạo data framema_sv <-c("SV001", "SV002", "SV003")ten_sv <-c("Nguyễn Văn A", "Trần Thị B", "Lê Văn C")diem_tb <-c(8.5, 7.9, 9.1)qua_mon <-c(TRUE, TRUE, TRUE)sinh_vien_df <-data.frame(MaSV = ma_sv, Ten = ten_sv, DiemTB = diem_tb, QuaMon = qua_mon)print(sinh_vien_df)# Truy cập cột trong data frame:print(sinh_vien_df$Ten) # Dùng ký hiệu $print(sinh_vien_df[["Ten"]]) # Dùng tên cột trong [[]]print(sinh_vien_df[, "Ten"]) # Dùng tên cột trong [] như ma trậnprint(sinh_vien_df[, 2]) # Dùng chỉ số cột# Xem cấu trúc của data framestr(sinh_vien_df)# Xem vài dòng đầuhead(sinh_vien_df)
List (Danh sách):
Là một cấu trúc có thứ tự, có thể chứa tập hợp các phần tử thuộc bất kỳ kiểu dữ liệu nào, kể cả các list khác, vector, data frame, hàm…
Tạo list bằng hàm list().
thong_tin_ca_nhan <-list(ho_ten ="Nguyễn Thị X",tuoi =30,thanh_pho ="Đà Lạt",da_ket_hon =TRUE,con_cai =c("Con 1", "Con 2"),thong_tin_hoc_van =data.frame(Truong ="ĐH Y", NamTN =2015))print(thong_tin_ca_nhan)# Truy cập phần tử trong list:print(thong_tin_ca_nhan$ho_ten)print(thong_tin_ca_nhan[[1]]) # Dùng [[]] với chỉ số hoặc tênprint(thong_tin_ca_nhan[["tuoi"]])
Factor (Yếu tố):
Được sử dụng đặc biệt để biểu diễn dữ liệu định tính (categorical data).
Về cơ bản, factor là một vector số nguyên, trong đó mỗi số nguyên có một nhãn (label) tương ứng. Điều này giúp R hiểu rằng biến đó là định tính và các giá trị của nó thuộc về một tập hợp các cấp độ (levels) xác định.
Rất quan trọng cho các mô hình thống kê phân tích dữ liệu định tính.
Tạo factor bằng hàm factor().
# Giả sử có vector giới tínhgioi_tinh_vector <-c("Nam", "Nữ", "Nữ", "Nam", "Nữ")# Chuyển thành factorgioi_tinh_factor <-factor(gioi_tinh_vector)print(gioi_tinh_factor)str(gioi_tinh_factor) # Sẽ thấy "Factor w/ 2 levels"levels(gioi_tinh_factor) # Xem các cấp độ# Factor có thứ tự (cho biến thứ bậc)muc_do_hai_long <-c("Hài lòng", "Bình thường", "Rất hài lòng", "Không hài lòng")hai_long_factor <-factor(muc_do_hai_long, levels =c("Không hài lòng", "Bình thường", "Hài lòng", "Rất hài lòng"),ordered =TRUE)print(hai_long_factor)str(hai_long_factor)
Sử dụng factor đảm bảo rằng các biến định tính được xử lý đúng cách trong các hàm phân tích (ví dụ, khi tạo bảng chéo hoặc xây dựng mô hình hồi quy).
2.4.4 Nhập, xuất và quản lý dữ liệu trong R
Một trong những bước đầu tiên của bất kỳ phân tích dữ liệu nào là đưa dữ liệu vào R.
Nhập dữ liệu:
File CSV (Comma Separated Values): Rất phổ biến. Dùng hàm read.csv().
# Giả sử có file "du_lieu_ban_hang.csv" trong thư mục làm việc# my_data <- read.csv("du_lieu_ban_hang.csv")# Nếu file dùng dấu chấm phẩy (;) làm phân tách (phổ biến ở một số nước châu Âu)# my_data_semicolon <- read.csv2("du_lieu_khac.csv")# Xem nhanh dữ liệu# head(my_data)# str(my_data)
Lưu ý: Cần đảm bảo file CSV nằm trong thư mục làm việc của R, hoặc cung cấp đường dẫn đầy đủ đến file. Các tùy chọn quan trọng của read.csv(): header = TRUE/FALSE (dòng đầu có phải tên cột không), sep = "," (ký tự phân tách), dec = "." (ký tự thập phân).
File Excel: Cần cài đặt và sử dụng các gói như readxl (hàm read_excel()) hoặc openxlsx (hàm read.xlsx()).
# install.packages("readxl") # Chỉ cần cài một lần# library(readxl)# excel_data <- read_excel("ten_file.xlsx", sheet = "TenSheetCanDoc")# head(excel_data)
Các định dạng khác: R hỗ trợ nhiều định dạng khác như SPSS (haven package), Stata (haven package), JSON (jsonlite package), dữ liệu từ web, cơ sở dữ liệu (DBI, RPostgreSQL, RMySQL, v.v.).
Xuất dữ liệu:
File CSV: Dùng hàm write.csv().
# Giả sử có data frame 'sinh_vien_df' đã tạo ở trên# write.csv(sinh_vien_df, file = "danh_sach_sinh_vien_xuat_ra.csv", row.names = FALSE)# row.names = FALSE để không ghi chỉ số hàng của R vào file CSV
File Excel: Dùng các gói như openxlsx (hàm write.xlsx()) hoặc writexl (hàm write_xlsx()).
Quản lý đối tượng trong R:
Liệt kê các đối tượng trong môi trường:ls()
Xóa đối tượng:rm(ten_doi_tuong) hoặc rm(list = c("dt1", "dt2"))
Xóa tất cả các đối tượng trong môi trường (cẩn thận!):rm(list = ls())
2.4.5 Cài đặt và sử dụng các gói (packages) trong R
Điểm mạnh lớn của R là hệ sinh thái các gói mở rộng. Gói (package) là một tập hợp các hàm, dữ liệu và tài liệu được biên soạn sẵn để thực hiện các tác vụ cụ thể.
Cài đặt gói:
Chỉ cần làm một lần cho mỗi gói trên một máy tính.
Dùng hàm install.packages("ten_goi"). R sẽ tải gói từ CRAN.
# Ví dụ cài đặt gói tidyverse (một bộ sưu tập các gói rất hữu ích cho thao tác dữ liệu và đồ họa)# install.packages("tidyverse")# Cài đặt các gói sẽ dùng nhiều trong môn học này# install.packages("gmodels") # Cho bảng chéo, hàm CrossTable# install.packages("vcd") # Cho trực quan hóa dữ liệu định tính, mosaic plots# install.packages("MASS") # Chứa nhiều hàm thống kê cổ điển và dữ liệu, ví dụ polr, loglm# install.packages("nnet") # Cho mô hình multinomial logit (hàm multinom)
Lưu ý: Cần kết nối internet để cài đặt gói.
Tải (load) gói vào phiên làm việc:
Sau khi cài đặt, mỗi khi muốn sử dụng các hàm trong một gói, bạn cần tải nó vào phiên làm việc hiện tại của R.
Dùng hàm library(ten_goi).
library(tidyverse) # Tải bộ tidyverse (bao gồm ggplot2, dplyr, tidyr, readr, ...)library(gmodels)library(vcd)
Nếu một gói được tải thành công, sẽ không có thông báo lỗi. Một số gói có thể hiển thị thông điệp khởi tạo.
Một số gói quan trọng cho phân tích dữ liệu (định tính và nói chung):
tidyverse: Một “siêu gói” bao gồm:
ggplot2: Hệ thống vẽ đồ thị mạnh mẽ và linh hoạt.
dplyr: Các hàm thao tác dữ liệu (filter, arrange, select, mutate, summarize, group_by).
tidyr: Công cụ để “dọn dẹp” và định dạng lại dữ liệu (pivot_wider, pivot_longer).
readr: Đọc file văn bản (CSV, TSV) nhanh hơn.
gmodels: Chứa hàm CrossTable() rất hữu ích để tạo bảng chéo với nhiều thống kê.
vcd: (Visualizing Categorical Data) Chuyên về trực quan hóa dữ liệu định tính, ví dụ biểu đồ mosaic.
MASS: (Support Functions and Datasets for Venables and Ripley’s MASS) Cung cấp nhiều hàm và bộ dữ liệu, bao gồm loglm() cho mô hình log-linear, polr() cho hồi quy thứ bậc.
nnet: Cho các hàm liên quan đến mạng neuron, nhưng cũng chứa multinom() cho mô hình multinomial logistic.
descr: Cung cấp các hàm thống kê mô tả, bao gồm freq() cho bảng tần số.
epitools: Các công cụ cho dịch tễ học, nhưng cũng hữu ích cho việc tính toán odds ratio, relative risk.
pROC: Tính toán và vẽ đường cong ROC.
ResourceSelection: Chứa kiểm định Hosmer-Lemeshow.
brant: Kiểm định giả định proportional odds trong mô hình thứ bậc.
Việc làm quen và sử dụng thành thạo R và RStudio, cùng với các gói bổ trợ, sẽ là chìa khóa để bạn thực hành và ứng dụng hiệu quả các kiến thức trong giáo trình này. Hãy coi R như một phòng thí nghiệm, nơi bạn có thể thử nghiệm, khám phá và tạo ra những hiểu biết giá trị từ dữ liệu.
2.5 Nguồn dữ liệu và các gói R thường dùng trong phân tích dữ liệu định tính
Phân tích dữ liệu đòi hỏi phải có dữ liệu! May mắn thay, có rất nhiều nguồn dữ liệu sẵn có, cả trong R và trực tuyến, mà chúng ta có thể sử dụng để học tập và nghiên cứu.
2.5.1 Các bộ dữ liệu có sẵn trong R
R đi kèm với một số bộ dữ liệu tích hợp sẵn, chủ yếu nằm trong gói datasets (được tải tự động khi R khởi động). Các bộ dữ liệu này rất tiện lợi cho việc thực hành và minh họa các hàm.
Để xem danh sách tất cả các bộ dữ liệu có sẵn trong các gói đã tải: R data()
Để tải một bộ dữ liệu cụ thể vào môi trường làm việc (sau khi tải, tên của bộ dữ liệu sẽ xuất hiện trong khung Environment): R data(HairEyeColor) # Một bộ dữ liệu định tính kinh điển data(UCBAdmissions) # Dữ liệu tuyển sinh của UC Berkeley, ví dụ về nghịch lý Simpson data( Titanic ) # Dữ liệu về hành khách trên tàu Titanic (thường là table hoặc array) # Mặc dù iris và mtcars chủ yếu là định lượng, chúng có thể dùng để minh họa tạo biến định tính data(iris) data(mtcars)
Sau khi tải, bạn có thể xem cấu trúc và nội dung của chúng:
str(HairEyeColor)print(HairEyeColor)head(UCBAdmissions) # Đây là dạng arrayclass(UCBAdmissions) # "table"# Chuyển đổi UCBAdmissions từ dạng table sang data frame để dễ thao tác hơn nếu cầnif (is.table(UCBAdmissions)) { ucb_df <-as.data.frame.table(UCBAdmissions, responseName ="Freq")head(ucb_df)}str(iris) # iris có biến Species là factor (định tính)summary(iris)
Bộ dữ liệu HairEyeColor là một mảng 3 chiều (Hair x Eye x Sex) với các tần số, rất thích hợp để minh họa phân tích bảng chéo và mô hình log-linear. UCBAdmissions cũng tương tự. Titanic cũng là một ví dụ hay.
Nhiều gói R khác cũng đi kèm với các bộ dữ liệu riêng. Khi bạn library(ten_goi), các bộ dữ liệu của gói đó (nếu có) cũng trở nên khả dụng.
2.5.2 Các nguồn dữ liệu trực tuyến uy tín
Internet là một kho tàng dữ liệu khổng lồ. Dưới đây là một số nguồn uy tín thường được sử dụng trong nghiên cứu kinh tế, tài chính và xã hội:
Tổ chức quốc tế:
World Bank (Ngân hàng Thế giới):https://databank.worldbank.org/ - Rất nhiều chỉ số kinh tế, xã hội, phát triển cho các quốc gia. Gói R WDI có thể dùng để truy cập trực tiếp.
Tổng cục Thống kê Việt Nam (GSO):https://www.gso.gov.vn/ - Nguồn dữ liệu chính thức về kinh tế - xã hội Việt Nam.
Cục Dự trữ Liên bang Mỹ (FRED):https://fred.stlouisfed.org/ - Kho dữ liệu kinh tế và tài chính khổng lồ, chủ yếu của Mỹ nhưng có cả quốc tế. Gói R quantmod và fredr giúp truy cập dễ dàng.
Kaggle:https://www.kaggle.com/datasets - Cộng đồng khoa học dữ liệu lớn với nhiều bộ dữ liệu đa dạng, thường được dùng cho các cuộc thi và thực hành.
UCI Machine Learning Repository:https://archive.ics.uci.edu/ml/index.php - Một trong những kho dữ liệu lâu đời và phổ biến nhất cho máy học, chứa nhiều bộ dữ liệu cổ điển.
Dataverse:https://dataverse.org/ - Nền tảng lưu trữ và chia sẻ dữ liệu nghiên cứu, được nhiều trường đại học sử dụng.
Dữ liệu tài chính thị trường:
Yahoo Finance:https://finance.yahoo.com/ - Dữ liệu giá cổ phiếu, chỉ số thị trường (có thể tải thủ công hoặc dùng gói R như quantmod).
Google Finance: (Tương tự Yahoo Finance, mặc dù việc truy cập tự động có thể khó khăn hơn).
Nhiều nhà cung cấp dữ liệu tài chính thương mại như Bloomberg, Refinitiv Eikon (thường yêu cầu thuê bao trả phí).
Khi sử dụng dữ liệu từ bất kỳ nguồn nào, điều quan trọng là phải hiểu rõ về nguồn gốc, cách thu thập, các định nghĩa biến số và những hạn chế tiềm ẩn của bộ dữ liệu đó. Luôn trích dẫn nguồn dữ liệu một cách hợp lệ.
2.5.3 Tổng quan về các gói R chuyên dụng (đã đề cập một phần)
Như đã giới thiệu ở mục 1.4.5, R có hàng ngàn gói phục vụ các mục đích phân tích khác nhau. Đối với phân tích dữ liệu định tính, một số gói bạn sẽ thường xuyên gặp và sử dụng trong giáo trình này bao gồm:
stats (có sẵn, không cần library() riêng): Chứa các hàm cơ bản như glm() (Generalized Linear Models - nền tảng cho logistic, Poisson regression), chisq.test(), fisher.test(), binom.test(), prop.test(), table(), ftable().
MASS: Như đã nói, chứa loglm() (mô hình log-linear cho bảng chéo), polr() (proportional odds logistic regression cho biến thứ bậc), stepAIC() (lựa chọn mô hình). Đi kèm nhiều bộ dữ liệu hữu ích.
nnet: Chứa multinom() để ước lượng mô hình multinomial logistic (cho biến phản hồi danh nghĩa có nhiều hơn 2 phạm trù).
vcd (Visualizing Categorical Data): Rất mạnh cho trực quan hóa dữ liệu định tính. Cung cấp các hàm vẽ biểu đồ mosaic (mosaic()), biểu đồ liên hợp (assoc()), sieve plots, agreement charts. Cũng chứa các hàm tính toán thước đo liên hợp và kiểm định cho bảng chéo.
gmodels: Hàm CrossTable() là một cải tiến của table() và xtabs(), cung cấp output bảng chéo chi tiết hơn với các tỷ lệ phần trăm (hàng, cột, tổng), tần số kỳ vọng, phần dư Chi-bình phương, và các kiểm định liên quan (Chi-bình phương, Fisher, McNemar).
dplyr (thuộc tidyverse): Mặc dù không chuyên về thống kê định tính, nhưng cực kỳ hữu ích cho việc chuẩn bị và thao tác dữ liệu trước khi phân tích: lọc (filter()), chọn biến (select()), tạo biến mới (mutate()), sắp xếp (arrange()), nhóm và tóm tắt (group_by(), summarise()).
ggplot2 (thuộc tidyverse): Hệ thống đồ họa mạnh mẽ để tạo biểu đồ thanh (geom_bar()), biểu đồ điểm (geom_point()), v.v., tùy biến cao, giúp trực quan hóa dữ liệu định tính một cách hiệu quả.
epitools: Cung cấp các hàm như oddsratio(), riskratio() để tính toán và hiển thị odds ratio, risk ratio cùng khoảng tin cậy, hữu ích khi phân tích bảng 2x2.
ResourceSelection: Chứa hàm hoslem.test() cho kiểm định Hosmer-Lemeshow (đánh giá độ phù hợp của mô hình logistic).
pROC: Chuyên về phân tích đường cong ROC (Receiver Operating Characteristic) và tính AUC (Area Under Curve) để đánh giá khả năng phân loại của mô hình nhị phân.
ordinal: Cung cấp các mô hình hồi quy phức tạp hơn cho biến phản hồi thứ bậc, ví dụ hàm clm() (cumulative link models).
brant: Chứa hàm brant() để kiểm định giả định proportional odds (hay parallel lines) trong mô hình hồi quy thứ bậc (ví dụ, sau khi dùng polr() từ gói MASS).
effects: Giúp tính toán và trực quan hóa các hiệu ứng (effects) của các biến dự báo trong mô hình GLM và các mô hình khác.
margins: Tính toán ảnh hưởng biên (marginal effects) trong các mô hình hồi quy, giúp diễn giải tham số dễ dàng hơn.
Nắm vững cách tìm kiếm, cài đặt và sử dụng các gói này sẽ mở rộng đáng kể khả năng phân tích của bạn. Khi gặp một vấn đề phân tích cụ thể, một trong những kỹ năng quan trọng là tìm ra gói R phù hợp để giải quyết nó. Trang web CRAN Task Views (https://cran.r-project.org/web/views/) là một nguồn tài liệu tốt để khám phá các gói theo lĩnh vực.
2.6 Tóm tắt chương
Chương 1 đã cung cấp những kiến thức nền tảng và công cụ thiết yếu cho hành trình phân tích dữ liệu định tính. Chúng ta đã:
Định nghĩa dữ liệu định tính: Hiểu rõ bản chất của dữ liệu định tính là mô tả thuộc tính, đặc điểm hoặc phân loại, khác biệt với dữ liệu định lượng vốn đo lường số lượng. Tầm quan trọng của nó trong các quyết định kinh tế, kinh doanh và tài chính cũng được nhấn mạnh.
Tìm hiểu các thang đo lường: Phân biệt rõ ràng giữa thang đo danh nghĩa (chỉ phân loại) và thang đo thứ bậc (phân loại có thứ tự). Đồng thời, ôn tập lại thang đo khoảng và tỷ lệ của dữ liệu định lượng để có cái nhìn toàn diện. Việc xác định đúng thang đo là tiền đề cho lựa chọn phương pháp phân tích phù hợp.
Nắm vững các phân phối xác suất cơ bản: Giới thiệu ba phân phối quan trọng cho biến định tính đơn lẻ:
Phân phối Bernoulli: Cho một thử nghiệm với hai kết quả.
Phân phối Nhị thức: Cho số lần thành công trong \(n\) thử nghiệm Bernoulli độc lập.
Phân phối Đa thức: Mở rộng của Nhị thức cho các thử nghiệm có nhiều hơn hai kết quả.
Giới thiệu ngôn ngữ R và RStudio: Cung cấp hướng dẫn cài đặt, làm quen với giao diện RStudio, các kiểu dữ liệu cơ bản (vector, matrix, data frame, list, factor), cách nhập - xuất dữ liệu, và quy trình cài đặt - sử dụng các gói (packages). R được xác định là công cụ thực hành chính xuyên suốt giáo trình.
Khám phá nguồn dữ liệu và các gói R chuyên dụng: Giới thiệu các bộ dữ liệu có sẵn trong R, các nguồn dữ liệu trực tuyến uy tín, và tổng quan về các gói R quan trọng sẽ được sử dụng trong phân tích dữ liệu định tính như stats, MASS, nnet, vcd, gmodels, tidyverse, v.v.
Với những kiến thức và kỹ năng từ chương này, người học đã được trang bị để bước vào các nội dung phân tích chuyên sâu hơn về bảng ngẫu nhiên và các mô hình hồi quy cho dữ liệu định tính trong các chương tiếp theo. Việc thực hành thường xuyên với R và tìm tòi các nguồn dữ liệu thực tế sẽ củng cố vững chắc nền tảng này.
2.7 Case studies
Dưới đây là một số tình huống (case study) minh họa cho các khái niệm đã học trong chương, tập trung vào các vấn đề kinh tế, kinh doanh, hoặc tài chính.
Case Study 1.1: Phân loại khách hàng theo nhóm tuổi cho chiến dịch Marketing
Bối cảnh: Một công ty bán lẻ thời trang muốn triển khai chiến dịch marketing nhắm vào các nhóm khách hàng khác nhau. Họ thu thập dữ liệu tuổi của 100 khách hàng.
Dữ liệu định tính: Công ty quyết định phân loại khách hàng thành các nhóm tuổi: “Thanh thiếu niên” (dưới 18), “Thanh niên” (18-25), “Trung niên trẻ” (26-35), “Trung niên” (36-55), “Cao niên” (trên 55). Biến “Nhóm tuổi” này là một biến định tính thứ bậc.
Câu hỏi:
Loại thang đo nào được sử dụng cho biến “Nhóm tuổi” ban đầu (trước khi nhóm) và “Nhóm tuổi” (sau khi nhóm)?
Làm thế nào để biểu diễn tỷ lệ khách hàng trong mỗi nhóm tuổi bằng R?
Vận dụng kiến thức chương 1:
Tuổi (số nguyên) là dữ liệu định lượng, thang đo tỷ lệ.
Nhóm tuổi là dữ liệu định tính, thang đo thứ bậc.
Có thể sử dụng R để tạo biến factor cho “Nhóm tuổi”, sau đó dùng table() và prop.table() để tính tần suất và tỷ lệ.
# Giả lập dữ liệu tuổi của 100 khách hàngset.seed(101)tuoi_khach_hang <-sample(15:70, 100, replace =TRUE)# Tạo biến nhóm tuổi (factor thứ bậc)nhom_tuoi <-cut(tuoi_khach_hang, breaks =c(0, 17, 25, 35, 55, Inf),labels =c("Thanh thiếu niên", "Thanh niên", "Trung niên trẻ", "Trung niên", "Cao niên"),right =TRUE, # Khoảng (a,b]ordered_result =TRUE)# Xem tần suấtbang_tan_suat_nhom_tuoi <-table(nhom_tuoi)print("Bảng tần suất nhóm tuổi:")print(bang_tan_suat_nhom_tuoi)# Xem tỷ lệbang_ty_le_nhom_tuoi <-prop.table(bang_tan_suat_nhom_tuoi)print("Bảng tỷ lệ nhóm tuổi:")print(round(bang_ty_le_nhom_tuoi *100, 2)) # In ra dạng phần trăm# Trực quan hóa bằng biểu đồ thanhbarplot(bang_ty_le_nhom_tuoi, main ="Tỷ lệ khách hàng theo nhóm tuổi", ylab ="Tỷ lệ", col = RColorBrewer::brewer.pal(length(levels(nhom_tuoi)), "Set2"))
Case Study 1.2: Khảo sát mức độ hài lòng của nhân viên
Bối cảnh: Phòng Nhân sự một công ty công nghệ thực hiện khảo sát hàng năm về mức độ hài lòng của nhân viên. Một câu hỏi quan trọng là: “Nhìn chung, bạn hài lòng với công việc hiện tại ở mức độ nào?” với các lựa chọn: “Rất không hài lòng”, “Không hài lòng”, “Bình thường”, “Hài lòng”, “Rất hài lòng”.
Dữ liệu định tính: Biến “Mức độ hài lòng” là một biến định tính thứ bậc.
Câu hỏi:
Làm thế nào để mã hóa và lưu trữ dữ liệu này trong R một cách hợp lý?
Tính toán số lượng nhân viên và tỷ lệ phần trăm cho mỗi mức độ hài lòng.
Vận dụng kiến thức chương 1:
Sử dụng factor() với tham số ordered = TRUE và levels được xác định đúng thứ tự.
# Giả lập dữ liệu khảo sát từ 50 nhân viênset.seed(102)muc_do_lua_chon =c("Rất không hài lòng", "Không hài lòng", "Bình thường", "Hài lòng", "Rất hài lòng")data_hai_long_nv <-sample(muc_do_lua_chon, 50, replace =TRUE, prob =c(0.05, 0.1, 0.25, 0.4, 0.2))# Tạo factor thứ bậchai_long_factor_nv <-factor(data_hai_long_nv,levels = muc_do_lua_chon,ordered =TRUE)# Xem cấu trúcstr(hai_long_factor_nv)# Tính tần suất và tỷ lệtan_suat_hai_long_nv <-table(hai_long_factor_nv)ty_le_hai_long_nv <-prop.table(tan_suat_hai_long_nv) *100print("Tần suất mức độ hài lòng của nhân viên:")print(tan_suat_hai_long_nv)print("Tỷ lệ (%) mức độ hài lòng của nhân viên:")print(round(ty_le_hai_long_nv, 2))# Biểu đồbarplot(tan_suat_hai_long_nv, main="Mức độ hài lòng của nhân viên", ylab="Số lượng", col="lightblue")
Case Study 1.3: Tỷ lệ sản phẩm lỗi trong một lô hàng
Bối cảnh: Một nhà máy sản xuất linh kiện điện tử kiểm tra 200 sản phẩm từ một lô hàng (\(n=200\)). Họ muốn ước tính tỷ lệ sản phẩm lỗi trong lô hàng này. Giả sử qua kinh nghiệm, tỷ lệ lỗi trung bình của nhà máy là 3% (\(p=0.03\)).
Dữ liệu định tính: Mỗi sản phẩm được kiểm tra có kết quả là “Lỗi” hoặc “Không lỗi” (biến Bernoulli). Số sản phẩm lỗi trong 200 sản phẩm tuân theo phân phối Nhị thức.
Câu hỏi:
Nếu tỷ lệ lỗi thực sự là 3%, xác suất tìm thấy đúng 5 sản phẩm lỗi trong 200 sản phẩm là bao nhiêu?
Xác suất tìm thấy nhiều hơn 10 sản phẩm lỗi là bao nhiêu?
Vận dụng kiến thức chương 1:
Sử dụng các hàm dbinom() và pbinom() trong R.
n_kiemtra <-200p_loi_thuc <-0.03# 1. Xác suất tìm thấy đúng 5 sản phẩm lỗiprob_5_loi <-dbinom(x =5, size = n_kiemtra, prob = p_loi_thuc)print(paste("Xác suất tìm thấy đúng 5 sản phẩm lỗi:", round(prob_5_loi, 4)))# 2. Xác suất tìm thấy nhiều hơn 10 sản phẩm lỗi P(X > 10) = 1 - P(X <= 10)prob_hon_10_loi <-1-pbinom(q =10, size = n_kiemtra, prob = p_loi_thuc)print(paste("Xác suất tìm thấy nhiều hơn 10 sản phẩm lỗi:", round(prob_hon_10_loi, 4)))# Kỳ vọng số sản phẩm lỗi:ky_vong_loi <- n_kiemtra * p_loi_thucprint(paste("Kỳ vọng số sản phẩm lỗi trong 200 sản phẩm:", ky_vong_loi))
Case Study 1.4: Lựa chọn nhà cung cấp dựa trên tiêu chí
Bối cảnh: Một công ty cần lựa chọn một trong ba nhà cung cấp (A, B, C) cho một loại nguyên vật liệu. Họ đánh giá các nhà cung cấp dựa trên 3 tiêu chí: “Giá cả” (Rẻ, Trung bình, Đắt), “Chất lượng” (Kém, Tốt, Rất tốt), và “Thời gian giao hàng” (Nhanh, Trung bình, Chậm). Đây đều là các biến định tính.
Dữ liệu định tính: Các biến “Giá cả”, “Chất lượng”, “Thời gian giao hàng” có thể được coi là thang đo thứ bậc. Biến “Nhà cung cấp” là danh nghĩa.
Câu hỏi:
Làm thế nào để tạo một data frame trong R lưu trữ thông tin đánh giá này?
Nếu công ty có một mẫu đánh giá từ nhiều bộ phận khác nhau, làm thế nào để tóm tắt lựa chọn nhà cung cấp ưu tiên?
Vận dụng kiến thức chương 1:
Tạo data frame, sử dụng factor cho các biến đánh giá.
# Giả lập dữ liệu đánh giá cho 3 nhà cung cấpnha_cung_cap <-c("A", "B", "C")gia_ca_danh_gia <-factor(c("Rẻ", "Trung bình", "Đắt"), levels =c("Rẻ", "Trung bình", "Đắt"), ordered =TRUE)chat_luong_danh_gia <-factor(c("Tốt", "Rất tốt", "Tốt"), levels =c("Kém", "Tốt", "Rất tốt"), ordered =TRUE)thoi_gian_giao_hang_danh_gia <-factor(c("Trung bình", "Nhanh", "Chậm"), levels =c("Nhanh", "Trung bình", "Chậm"), ordered =TRUE)danh_gia_ncc_df <-data.frame(NhaCungCap = nha_cung_cap,GiaCa = gia_ca_danh_gia,ChatLuong = chat_luong_danh_gia,ThoiGianGiaoHang = thoi_gian_giao_hang_danh_gia)print("Bảng đánh giá nhà cung cấp:")print(danh_gia_ncc_df)str(danh_gia_ncc_df)# Giả sử có dữ liệu lựa chọn từ 10 bộ phận (mỗi bộ phận chọn 1 NCC)set.seed(104)lua_chon_tu_bo_phan <-sample(c("A", "B", "C"), 10, replace =TRUE, prob =c(0.4, 0.4, 0.2))lua_chon_factor <-factor(lua_chon_tu_bo_phan)print("Lựa chọn nhà cung cấp ưu tiên từ các bộ phận:")print(table(lua_chon_factor))barplot(table(lua_chon_factor), main="Lựa chọn NCC ưu tiên", col="lightgreen")
Case Study 1.5: Phân tích cơ cấu ngành nghề của các khoản đầu tư trong danh mục
Bối cảnh: Một quỹ đầu tư có danh mục gồm 1000 khoản đầu tư. Họ muốn phân tích cơ cấu ngành nghề của các khoản đầu tư này. Các ngành nghề chính bao gồm: “Công nghệ”, “Tài chính”, “Y tế”, “Tiêu dùng thiết yếu”, “Năng lượng”, “Công nghiệp”, “Bất động sản”.
Dữ liệu định tính: Biến “Ngành nghề” là một biến định tính danh nghĩa. Nếu quỹ theo dõi số lượng khoản đầu tư trong mỗi ngành, đây là ứng dụng của phân phối Đa thức (nếu lấy mẫu hoặc xem xét toàn bộ).
Câu hỏi:
Xác định loại thang đo cho biến “Ngành nghề”.
Giả sử tỷ lệ phân bổ dự kiến cho các ngành là: Công nghệ (25%), Tài chính (20%), Y tế (15%), Tiêu dùng thiết yếu (15%), Năng lượng (10%), Công nghiệp (10%), Bất động sản (5%). Trong 1000 khoản đầu tư, số lượng kỳ vọng cho mỗi ngành là bao nhiêu?
Sử dụng R để mô phỏng một danh mục đầu tư với cơ cấu như trên và hiển thị tần suất thực tế.
Vận dụng kiến thức chương 1:
Thang đo danh nghĩa. Kỳ vọng \(np_j\). Dùng rmultinom hoặc sample với prob.
nganh_nghe_cac_khoan_dau_tu <-c("Công nghệ", "Tài chính", "Y tế", "Tiêu dùng thiết yếu", "Năng lượng", "Công nghiệp", "Bất động sản")ty_le_phan_bo_ky_vong <-c(0.25, 0.20, 0.15, 0.15, 0.10, 0.10, 0.05)tong_so_khoan_dau_tu <-1000# 1. Thang đo: Danh nghĩa# 2. Số lượng kỳ vọng cho mỗi ngànhso_luong_ky_vong_nganh <- tong_so_khoan_dau_tu * ty_le_phan_bo_ky_vongnames(so_luong_ky_vong_nganh) <- nganh_nghe_cac_khoan_dau_tuprint("Số lượng khoản đầu tư kỳ vọng theo ngành:")print(so_luong_ky_vong_nganh)# 3. Mô phỏng danh mục thực tếset.seed(105)danh_muc_mo_phong <-sample(nganh_nghe_cac_khoan_dau_tu, size = tong_so_khoan_dau_tu, replace =TRUE, prob = ty_le_phan_bo_ky_vong)# Tần suất thực tếtan_suat_thuc_te_nganh <-table(factor(danh_muc_mo_phong, levels = nganh_nghe_cac_khoan_dau_tu))print("Tần suất thực tế của các khoản đầu tư theo ngành (mô phỏng):")print(tan_suat_thuc_te_nganh)# Trực quan hóabarplot(tan_suat_thuc_te_nganh, main ="Cơ cấu ngành nghề thực tế trong danh mục (mô phỏng)", las =2, # Xoay nhãn trục xcex.names =0.7, # Kích thước chữ nhãncol = RColorBrewer::brewer.pal(length(nganh_nghe_cac_khoan_dau_tu), "Spectral"))
2.8 Bài tập
Bài tập lý thuyết
Phân biệt rõ ràng giữa dữ liệu định tính và dữ liệu định lượng. Cho ví dụ minh họa trong lĩnh vực tài chính ngân hàng cho mỗi loại.
Trình bày sự khác nhau giữa thang đo danh nghĩa và thang đo thứ bậc. Mỗi loại cho 2 ví dụ về biến số thường gặp trong khảo sát thị trường.
Tại sao việc xác định đúng thang đo lường của một biến lại quan trọng trong phân tích dữ liệu?
Một biến “Xếp hạng tín dụng doanh nghiệp” (AAA, AA, A, BBB, BB, B, CCC, CC, C, D) thuộc loại thang đo nào? Giải thích.
Biến “Loại hình hợp đồng lao động” (Không xác định thời hạn, Xác định thời hạn, Thời vụ) thuộc loại thang đo nào? Nếu mã hóa “Không xác định thời hạn” = 1, “Xác định thời hạn” = 2, “Thời vụ” = 3, có thể tính giá trị trung bình của biến này không? Tại sao?
Phân phối Bernoulli là gì? Nêu một ví dụ ứng dụng trong phân tích rủi ro tín dụng.
Nêu các điều kiện để một biến ngẫu nhiên tuân theo phân phối Nhị thức. Mối quan hệ giữa phân phối Nhị thức và Bernoulli là gì?
Một công ty bảo hiểm ghi nhận trong quá khứ có 5% hợp đồng bị hủy trong năm đầu tiên. Nếu công ty ký được 50 hợp đồng mới trong tháng này, số hợp đồng bị hủy trong năm đầu trong số 50 hợp đồng này có thể được mô tả bằng phân phối xác suất nào? Nêu các tham số của phân phối đó.
Phân phối Đa thức là gì? Cho ví dụ về một tình huống nghiên cứu marketing có thể sử dụng phân phối này.
Trong R, sự khác biệt chính giữa một vector và một list là gì?
Kiểu dữ liệu factor trong R dùng để làm gì? Tại sao nó lại quan trọng khi làm việc với dữ liệu định tính?
Nêu ít nhất 3 lợi ích của việc sử dụng R và RStudio cho phân tích dữ liệu.
“Mức độ ưu tiên của một dự án đầu tư” được đánh giá là (Thấp, Trung bình, Cao). Đây có phải là dữ liệu định tính không? Nếu có, nó thuộc thang đo nào?
Giả sử bạn có một biến “Thu nhập hàng tháng” (đơn vị: triệu đồng). Bạn có thể chuyển đổi biến này thành biến định tính như thế nào? Việc chuyển đổi này có thể mang lại lợi ích và hạn chế gì?
Tại sao không nên tính giá trị trung bình cho một biến danh nghĩa được mã hóa bằng số (ví dụ: Giới tính Nam=1, Nữ=0, Khác=2)?
Bài tập thực hành với R
Khởi tạo và thao tác vector:
Tạo một vector ten_san_pham chứa tên của 5 sản phẩm tài chính (ví dụ: “Tiết kiệm”, “Cho vay tiêu dùng”, “Thẻ tín dụng”, “Đầu tư trái phiếu”, “Bảo hiểm nhân thọ”).
Tạo một vector lai_suat_ky_vong chứa tỷ lệ lãi suất kỳ vọng (dưới dạng số thập phân) tương ứng cho 5 sản phẩm trên.
Hiển thị sản phẩm thứ 3 và lãi suất của nó.
Hiển thị tên và lãi suất của các sản phẩm từ thứ 2 đến thứ 4.
Làm việc với Data Frame:
Tạo một data frame danh_muc_cp chứa thông tin về 4 mã cổ phiếu: MaCP (ký tự), Nganh (ký tự, ví dụ: “Ngân hàng”, “Bất động sản”, “Công nghệ”), GiaDongCua (số), KhoiLuongGD (số).
In ra toàn bộ data frame.
Sử dụng hàm str() để xem cấu trúc của data frame.
Truy cập và hiển thị cột Nganh của data frame.
Hiển thị thông tin của cổ phiếu thứ 2 trong data frame.
Sử dụng Factor:
Một công ty thực hiện khảo sát về “Kênh đầu tư ưa thích” với các lựa chọn: “Cổ phiếu”, “Trái phiếu”, “Vàng”, “Bất động sản”, “Tiền gửi ngân hàng”. Giả sử thu được 20 phiếu trả lời. Hãy tạo một vector ký tự kenh_dt_data chứa dữ liệu này (có thể tự giả lập dữ liệu).
Chuyển vector kenh_dt_data thành một factor tên là kenh_dt_factor.
Sử dụng hàm table() để xem tần suất của mỗi kênh đầu tư.
Biến “Mức rủi ro của khoản đầu tư” có các cấp độ “Rất thấp”, “Thấp”, “Trung bình”, “Cao”, “Rất cao”. Tạo một factor có thứ tự muc_rui_ro_factor từ một vector dữ liệu giả lập (15 quan sát) cho biến này, đảm bảo các cấp độ được sắp xếp đúng. In ra factor và cấu trúc của nó.
Phân phối Nhị thức trong R: Một startup tin rằng xác suất một nhà đầu tư tiềm năng đồng ý rót vốn sau buổi thuyết trình là \(p=0.15\). Startup có lịch thuyết trình với 20 nhà đầu tư (\(n=20\)).
Tính xác suất có đúng 3 nhà đầu tư đồng ý rót vốn. (Dùng dbinom())
Tính xác suất có ít nhất 1 nhà đầu tư đồng ý rót vốn. (Dùng pbinom())
Tính xác suất có nhiều nhất 5 nhà đầu tư đồng ý rót vốn.
Vẽ biểu đồ hàm khối xác suất cho số nhà đầu tư đồng ý rót vốn (từ 0 đến 20).
Nhập và xem dữ liệu có sẵn:
Tải bộ dữ liệu mtcars vào môi trường làm việc.
Sử dụng head() để xem 6 dòng đầu tiên của mtcars.
Sử dụng str() để xem cấu trúc của mtcars.
Biến cyl (số xi-lanh) và am (loại hộp số: 0=tự động, 1=số sàn) trong mtcars có thể coi là biến định tính không? Nếu có, chúng là thang đo gì? Chuyển đổi chúng thành factor và kiểm tra lại bằng str().
Sử dụng hàm table() để xem tần suất của biến cyl (sau khi đã chuyển thành factor).
Cài đặt và sử dụng gói:
Cài đặt gói gmodels (nếu chưa cài).
Tải gói gmodels vào phiên làm việc.
Tải bộ dữ liệu UCBAdmissions (nếu chưa có trong môi trường). Chuyển nó thành data frame ucb_df như đã hướng dẫn trong phần lý thuyết.
Sử dụng hàm CrossTable() từ gói gmodels để tạo bảng chéo giữa Admit (Trúng tuyển) và Gender (Giới tính) trong ucb_df. (Gợi ý: CrossTable(ucb_df$Gender, ucb_df$Admit, dnn = c("Giới tính", "Trúng tuyển"))). Quan sát output.
Tạo dữ liệu định tính từ dữ liệu định lượng: Sử dụng bộ dữ liệu faithful (có sẵn trong R, data(faithful)). Biến eruptions là thời gian phun của mạch nước phun Old Faithful.
Xem tóm tắt thống kê của biến eruptions bằng summary(faithful$eruptions).
Tạo một biến mới eruption_category bằng cách phân loại eruptions thành 3 nhóm: “Ngắn” (dưới 2 phút), “Trung bình” (từ 2 đến 4 phút), “Dài” (trên 4 phút). Sử dụng hàm cut(). Đảm bảo biến này là một factor có thứ tự.
In ra bảng tần suất của eruption_category.
Phân phối Đa thức trong R: Một công ty nghiên cứu thị trường khảo sát người tiêu dùng về loại nước giải khát họ ưa thích nhất trong 3 loại: A, B, C. Giả sử tỷ lệ ưa thích thực tế trong dân số là \(p_A=0.5, p_B=0.3, p_C=0.2\). Họ khảo sát 50 người.
Mô phỏng kết quả của cuộc khảo sát này 1 lần (tức là sinh 1 mẫu 50 người). Hiển thị số người chọn mỗi loại. (Dùng rmultinom() hoặc sample())
Kỳ vọng số người chọn mỗi loại là bao nhiêu?
Đọc file CSV (Giả lập):
Tạo một file CSV đơn giản bằng Notepad hoặc Excel tên là khach_hang_demo.csv với nội dung sau:
Sử dụng hàm read.csv() để đọc file này vào một data frame tên là kh_demo_df.
In ra data frame kh_demo_df và xem cấu trúc của nó. Chú ý kiểu dữ liệu của các cột. Biến GioiTinh và MuaHang có nên là factor không?
Quản lý thư mục làm việc và đối tượng:
Sử dụng getwd() để xem thư mục làm việc hiện tại của bạn.
Tạo một vài đối tượng (vector, data frame) với các tên tùy ý.
Sử dụng ls() để liệt kê tất cả các đối tượng trong môi trường làm việc của bạn.
Sử dụng rm() để xóa một trong các đối tượng bạn vừa tạo. Kiểm tra lại bằng ls().
2.9 Tài liệu tham khảo
Agresti, A. (2002). Categorical Data Analysis (2nd ed.). Wiley.
Agresti, A. (2013). Categorical Data Analysis (3rd ed.). Wiley.
Agresti, A. (2018). An Introduction to Categorical Data Analysis (3rd ed.). Wiley.
Friendly, M., & Meyer, D. (2016). Discrete Data Analysis with R: Visualization and Modeling Techniques for Categorical and Count Data. Chapman and Hall/CRC.
Hosmer Jr, D. W., Lemeshow, S., & Sturdivant, R. X. (2013). Applied Logistic Regression (3rd ed.). Wiley.
Kabacoff, R. I. (2015). R in Action: Data analysis and graphics with R (2nd ed.). Manning.
Wickham, H., & Grolemund, G. (2017). R for Data Science: Import, Tidy, Transform, Visualize, and Model Data. O’Reilly Media.
R Core Team (2023). R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. URL https://www.R-project.org/.
RStudio Team (2023). RStudio: Integrated Development Environment for R. Posit Software, PBC, Boston, MA. URL https://posit.co/.
 Đồ thị này được tạo ra từ đoạn mã R trên, minh họa xác suất tương ứng với số lần thành công (từ 0 đến 10) trong 10 lần thử với xác suất thành công trong từng lần thử là 0.9. Nhìn đồ thị chúng ta có thể thấy, xác suất cao nhất tập trung quanh giá trị kỳ vọng
Đồ thị này được tạo ra từ đoạn mã R trên, minh họa xác suất tương ứng với số lần thành công (từ 0 đến 10) trong 10 lần thử với xác suất thành công trong từng lần thử là 0.9. Nhìn đồ thị chúng ta có thể thấy, xác suất cao nhất tập trung quanh giá trị kỳ vọng