Sau khi hoàn thành chương này, người học sẽ có khả năng:
Hiểu cấu trúc xác suất của bảng ngẫu nhiên hai chiều và nhiều chiều.
Biết cách tính toán và diễn giải các thống kê mô tả mối liên hệ giữa hai biến định tính.
Thực hiện các kiểm định giả thuyết về tính độc lập và mối liên hệ trong bảng ngẫu nhiên.
Phân biệt và áp dụng các thang đo liên hợp phù hợp với từng loại dữ liệu.
Hiểu và xử lý các vấn đề trong phân tích bảng phân tầng, nhận diện nghịch lý Simpson.
Thành thạo việc sử dụng R để tạo, trực quan hóa và phân tích bảng ngẫu nhiên.
3.1 Giới thiệu bảng ngẫu nhiên hai chiều
Khi chúng ta muốn nghiên cứu mối quan hệ giữa hai biến định tính, công cụ cơ bản và trực quan nhất là bảng ngẫu nhiên hai chiều (two-way contingency table). Bảng này trình bày tần suất đồng thời xuất hiện của các phạm trù của hai biến.
3.1.1 Cấu trúc bảng ngẫu nhiên
Một bảng ngẫu (Contingency Table) nhiên hai chiều được tạo ra bằng cách phân loại các đối tượng trong mẫu (hoặc tổng thể) theo hai biến định tính, gọi là biến dòng (row variable) và biến cột (column variable).
Giả sử biến dòng \(X\) có \(I\) phạm trù (levels) và biến cột \(Y\) có \(J\) phạm trù. Bảng ngẫu nhiên \(I \times J\) (đọc là “I nhân J”) sẽ có dạng:
Biến X Biến Y
Phạm trù 1 của Y (\(y_1\))
Phạm trù 2 của Y (\(Yy_2\))
…
Phạm trù J của Y (\(y_J\))
Tổng dòng
Phạm trù 1 của X (\(x_1\))
\(n_{11}\)
\(n_{12}\)
…
\(n_{1J}\)
\(n_{1.}\)
Phạm trù 2 của X (\(x_2\))
\(n_{21}\)
\(n_{22}\)
…
\(n_{2J}\)
\(n_{2.}\)
…
…
…
…
…
…
Phạm trù I của X (\(x_I\))
\(n_{I1}\)
\(n_{I2}\)
…
\(n_{IJ}\)
\(n_{I.}\)
Tổng cột
\(n_{.1}\)
\(n_{.2}\)
…
\(n_{.J}\)
\(n\)
Trong đó:
\(n_{ij}\): là tần số quan sát (observed frequency) trong ô \((i,j)\), tức là số lượng đối tượng đồng thời thuộc phạm trù thứ \(i\) của biến \(X\) và phạm trù thứ \(j\) của biến \(Y\).
\(n_{i.} = \sum_{j=1}^{J} n_{ij}\): là tổng tần số của dòng thứ \(i\) (row marginal frequency), tức là tổng số đối tượng thuộc phạm trù \(X_i\).
\(n_{.j} = \sum_{i=1}^{I} n_{ij}\): là tổng tần số của cột thứ \(j\) (column marginal frequency), tức là tổng số đối tượng thuộc phạm trù \(Y_j\).
Ví dụ: Một ngân hàng khảo sát 200 khách hàng (\(N=200\)) về việc sử dụng dịch vụ Mobile Banking (biến \(X\): Có, Không) và nhóm tuổi của họ (biến \(Y\): Trẻ <30, Trung niên 30-50, Cao tuổi >50). Kết quả có thể được trình bày trong bảng \(2 \times 3\) như sau:
Sử dụng Mobile Banking Nhóm tuổi
Trẻ (<30)
Trung niên (30-50)
Cao tuổi (>50)
Tổng dòng
Có
60
50
10
120
Không
15
25
40
80
Tổng cột
75
75
50
200
Từ bảng này, chúng ta thấy:
Có 60 khách hàng trẻ sử dụng Mobile Banking (\(n_{11}=60\)).
Tổng cộng có 120 khách hàng sử dụng Mobile Banking (\(n_{1.}=120\)).
Tổng cộng có 75 khách hàng thuộc nhóm tuổi trẻ (\(n_{.1}=75\)).
3.1.2 Các loại tần số và tỷ lệ
Trong bảng ngẫu nhiên, các tần số quan sát \(n_{ij}\) cung cấp thông tin về mối liên hệ giữa hai biến. Tuy nhiên, để hiểu rõ hơn về mối liên hệ này, chúng ta cần tính toán các loại tần số và tỷ lệ khác nhau để mô tả dữ liệu.
Tần số tương đối (Relative Frequencies) hay Tỷ lệ chung (Joint Proportions):\[p_{ij} = \frac{n_{ij}}{n}\] Đây là tỷ lệ của các quan sát rơi vào ô \((i,j)\) so với mẫu. \[\sum_{i}\sum_{j} p_{ij} = 1\]. Ví dụ: Tỷ lệ khách hàng trẻ sử dụng Mobile Banking là \(p_{11} = 60/200 = 0.3\) (hay 30%).
Phân phối biên (Marginal Distributions):
Tỷ lệ tổng biên của dòng (Row Marginal Proportions):\[p_{i.} = \frac{n_{i.}}{N} = \sum_{j} p_{ij}\] Đây chính là phân phối xác suất của biến \(X\). Ví dụ: Tỷ lệ khách hàng sử dụng Mobile Banking (bất kể tuổi) là \(p_{1.} = 120/200 = 0.6\).
Tỷ lệ của tổng cột (Column Marginal Proportions):\[p_{.j} = \frac{n_{.j}}{N} = \sum_{i} p_{ij}\] Đây chính là phân phối xác suất của biến \(Y\). Ví dụ: Tỷ lệ khách hàng thuộc nhóm tuổi trẻ là \(p_{.1} = 75/200 = 0.375\).
Phân phối có điều kiện (Conditional Distributions): Đây là các phân phối quan trọng nhất để nghiên cứu mối liên hệ giữa hai biến.
Phân phối có điều kiện của Y theo X (Conditional distribution of Y, given X):\[p_{j|i} = P(Y=Y_j | X=X_i) = \frac{n_{ij}}{n_{i.}}\] Đây là tỷ lệ các quan sát thuộc phạm trù \(Y_j\) trong số những quan sát thuộc phạm trù \(X_i\). \(\sum_{j} p_{j|i} = 1\) cho mỗi \(i\). Ví dụ: Trong số những người sử dụng Mobile Banking, tỷ lệ người trẻ là \(p_{1|1} = n_{11}/n_{1.} = 60/120 = 0.5\).
Phân phối có điều kiện của X theo Y (Conditional distribution of X, given Y):\[p_{i|j} = P(X=X_i | Y=Y_j) = \frac{n_{ij}}{n_{.j}}\] Đây là tỷ lệ các quan sát thuộc phạm trù \(X_i\) trong số những quan sát thuộc phạm trù \(Y_j\). \(\sum_{i} p_{i|j} = 1\) cho mỗi \(j\). Ví dụ: Trong số những người trẻ, tỷ lệ người sử dụng Mobile Banking là \(p_{1|1} = n_{11}/n_{.1} = 60/75 = 0.8\).
Nếu hai biến \(X\) và \(Y\) là độc lập thống kê (statistically independent), thì phân phối có điều kiện của \(Y\) theo \(X\) sẽ giống nhau với mọi phạm trù của \(X\) (tức là \(p_{j|i} = p_{.j}\) cho mọi \(i\)), và tương tự, phân phối có điều kiện của \(X\) theo \(Y\) sẽ giống nhau với mọi phạm trù của \(Y\) (tức là \(p_{i|j} = p_{i.}\) cho mọi \(j\)). Sự khác biệt trong các phân phối có điều kiện là dấu hiệu của mối liên hệ giữa hai biến.
Tần số kỳ vọng (Expected Frequencies): Nếu giả thuyết về tính độc lập giữa \(X\) và \(Y\) là đúng, thì tần số kỳ vọng (hay tần số lý thuyết) cho ô \((i,j)\), ký hiệu là \(m_{ij}\) hoặc \(E_{ij}\), được tính bằng: \[m_{ij} = N \times p_{i.} \times p_{.j} = N \times \frac{n_{i.}}{N} \times \frac{n_{.j}}{N} = \frac{n_{i.} \times n_{.j}}{N}\] Tần số kỳ vọng này đại diện cho số lượng quan sát mà chúng ta kỳ vọng sẽ thấy trong ô \((i,j)\) nếu hai biến là độc lập. Nó được tính dựa trên tổng số quan sát và phân phối biên của hai biến.
Tần số kỳ vọng đóng vai trò quan trọng trong kiểm định Chi-bình phương (sẽ trình bày sau).
Ví dụ: Tần số kỳ vọng cho ô (Sử dụng Mobile Banking = Có, Nhóm tuổi = Trẻ) nếu hai biến độc lập là: \(m_{11} = (120 \times 75) / 200 = 9000 / 200 = 45\). So sánh \(n_{11}=60\) với \(m_{11}=45\) cho thấy có nhiều người trẻ sử dụng Mobile Banking hơn so với kỳ vọng nếu tuổi và việc sử dụng là độc lập.
3.1.3 Các phân phối xác suất liên quan đến bảng ngẫu nhiên
Việc lựa chọn mô hình xác suất phù hợp cho các tần số ô \(n_{ij}\) phụ thuộc vào cách dữ liệu được thu thập.
Trong phân tích bảng ngẫu nhiên, chúng ta thường sử dụng các mô hình xác suất sau:
Phân phối Poisson: Nếu tổng hàng và cột không được xác định trước (cả \(n\), \(n_{i.}\), \(n_{.j}\) đều là ngẫu nhiên), và các \(n_{ij}\) là các biến ngẫu nhiên Poisson độc lập với tham số (kỳ vọng) \(\mu_{ij}\), thì \(n = \sum n_{ij}\) cũng tuân theo phân phối Poisson. Đây là cơ sở để xây dựng mô hình Log-linear. Ví dụ: Một trung tâm thương mại lớn muốn phân tích các sự cố an ninh xảy ra trong khuôn viên của họ trong quý vừa qua theo khu vực và loại sự cố.
Phân phối Multinomial (Đa thức): Nếu cở mẫu \(n\) được cố định trước, và các đối tượng được phân loại ngẫu nhiên vào \(I \times J\) ô với xác suất \(p_{ij}\) cho mỗi ô (với \(\sum p_{ij}=1\)), thì vector các tần số ô \((n_{11}, n_{12}, ..., n_{IJ})\) tuân theo phân phối Multinomial với tham số \(n\) và vector xác suất \((p_{11}, ..., p_{IJ})\). Ví dụ: Khảo sát \(n=200\) khách hàng và phân loại họ theo 2 biến.
Phân phối Product Multinomial (Tích các phân phối Đa thức):
Nếu tổng các dòng \(n_{i.}\) được cố định trước (Row marginals fixed): Điều này xảy ra khi chúng ta lấy các mẫu độc lập từ mỗi phạm trù của biến \(X\), và sau đó phân loại các đối tượng trong mỗi mẫu đó theo biến \(Y\). Khi đó, mỗi dòng \(i\) của bảng ngẫu nhiên \((n_{i1}, n_{i2}, ..., n_{iJ})\) sẽ tuân theo một phân phối Multinomial với kích thước \(n_{i.}\) và vector xác suất có điều kiện \((p_{1|i}, p_{2|i}, ..., p_{J|i})\). Toàn bộ bảng là tích của \(I\) phân phối Multinomial độc lập này. Ví dụ: Chọn 120 người sử dụng Mobile Banking và 80 người không sử dụng, sau đó hỏi tuổi của họ.
Nếu tổng các cột \(n_{.j}\) được cố định trước (Column marginals fixed): Tương tự, mỗi cột \(j\) của bảng \((n_{1j}, n_{2j}, ..., n_{Ij})\) sẽ tuân theo một phân phối Multinomial với kích thước \(n_{.j}\) và vector xác suất có điều kiện \((p_{1|j}, p_{2|j}, ..., p_{I|j})\). Toàn bộ bảng là tích của \(J\) phân phối Multinomial độc lập. Ví dụ: Chọn 75 người trẻ, 75 người trung niên, 50 người cao tuổi, sau đó hỏi họ có dùng Mobile Banking không.
May mắn thay, nhiều phương pháp suy diễn cho bảng ngẫu nhiên (như kiểm định Chi-bình phương, ước lượng tỷ số chênh) đều cho kết quả tương tự nhau bất kể mô hình lấy mẫu nào trong ba mô hình trên được giả định (Poisson, Multinomial, Product Multinomial), miễn là kích thước mẫu đủ lớn.
3.2 Bảng ngẫu nhiên 2x2
Bảng \(2 \times 2\) là trường hợp đơn giản nhất nhưng rất quan trọng của bảng ngẫu nhiên 2 chiều. Nó được sử dụng để so sánh hai nhóm (ví dụ: nhóm điều trị và nhóm đối chứng) trên một kết quả nhị phân (ví dụ: thành công/thất bại, có bệnh/không bệnh).
Giả sử bảng \(2 \times 2\) có dạng:
Biến X (Nhóm) Biến Y (Kết quả)
Thành công (\(y_1\))
Thất bại (\(y_2\))
Tổng dòng
Nhóm 1 (\(x_1\))
\(n_{11}\)
\(n_{12}\)
\(n_{1.}\)
Nhóm 2 (\(x_2\))
\(n_{21}\)
\(n_{22}\)
\(n_{2.}\)
Tổng cột
\(n_{.1}\)
\(n_{.2}\)
\(n\)
Trong nhiều ứng dụng, chúng ta quan tâm đến việc so sánh tỷ lệ “thành công” giữa hai nhóm.
Tỷ lệ thành công trong Nhóm 1: \(\hat{p}_1 = P(Y=y_1 | X=x_1) = \frac{n_{11}}{n_{1.}}\)
Tỷ lệ thành công trong Nhóm 2: \(\hat{p}_2 = P(Y= y_1 | X=x_2) = \frac{n_{21}}{n_{2.}}\)
Có ba cách phổ biến để so sánh \(\hat{p}_1\) và \(\hat{p}_2\):
3.2.1 Hiệu số hai tỷ lệ (Difference in Proportions)
Định nghĩa: \(D = p_1 - p_2\).
Ước lượng điểm: \[\hat{D} = \hat{p}_1 - \hat{p}_2 = \frac{n_{11}}{n_{1.}} - \frac{n_{21}}{n_{2.}}\] Giá trị \(D\) nằm trong khoảng \([-1, 1]\).
Nếu \(D > 0\), Nhóm 1 có tỷ lệ thành công cao hơn Nhóm 2.
Nếu \(D < 0\), Nhóm 1 có tỷ lệ thành công thấp hơn Nhóm 2.
Nếu \(D = 0\), không có sự khác biệt về tỷ lệ thành công giữa hai nhóm (hai biến độc lập).
Sai số chuẩn (Standard Error - SE) của \(\hat{D}\) được ước lượng là: \[SE(\hat{D}) = \sqrt{\frac{\hat{p}_1(1-\hat{p}_1)}{n_{1.}} + \frac{\hat{p}_2(1-\hat{p}_2)}{n_{2.}}}\]
Khoảng tin cậy (95%) cho \(D\) là:
\[\hat{D} \pm z_{\alpha/2} \times SE(\hat{D})\] trong đó \(z_{\alpha/2}\) là giá trị tới hạn từ phân phối chuẩn (\(z_{\alpha/2} \approx 1.96\) cho KTC 95%).
3.2.2 Tỷ số nguy cơ (Relative Risk - RR)
Còn gọi là Tỷ số rủi ro, Tỷ số tỷ lệ (Risk Ratio, Rate Ratio).
Định nghĩa: \[RR = \frac{p_1}{p_2}\]. Ước lượng điểm: \[\widehat{RR} = \frac{\hat{p}_1}{\hat{p}_2} = \frac{n_{11}/n_{1.}}{n_{21}/n_{2.}}\] Giá trị \(RR\) nằm trong khoảng \([0, \infty)\).
Nếu \(RR > 1\), Nhóm 1 có tỷ lệ thành công cao hơn (nguy cơ cao hơn nếu “thành công” là một sự kiện bất lợi) so với Nhóm 2. Cụ thể, tỷ lệ thành công ở Nhóm 1 cao gấp \(RR\) lần Nhóm 2.
Nếu \(RR < 1\), Nhóm 1 có tỷ lệ thành công thấp hơn Nhóm 2.
Nếu \(RR = 1\), không có sự khác biệt về tỷ lệ thành công (hai biến độc lập).
Vì phân phối của \(\widehat{RR}\) thường bị lệch, người ta thường làm việc với \(\log(\widehat{RR})\). Sai số chuẩn của \(\log(\widehat{RR})\) được ước lượng là: \[SE(\log(\widehat{RR})) = \sqrt{\frac{1-\hat{p}_1}{n_{11}} + \frac{1-\hat{p}_2}{n_{21}}} = \sqrt{\frac{n_{12}}{n_{11}n_{1.}} + \frac{n_{22}}{n_{21}n_{2.}}}\]Lưu ý: công thức này yêu cầu \(n_{11}>0\) và \(n_{21}>0\). Nếu có ô bằng 0, cần có điều chỉnh, ví dụ cộng 0.5 vào tất cả các ô.
Khoảng tin cậy (ví dụ 95%) cho \(\log(RR)\) là: \[\log(\widehat{RR}) \pm z_{\alpha/2} \times SE(\log(\widehat{RR}))\]
3.2.3 Tỷ số chênh (Odds Ratio - OR)
Odds của một sự kiện là tỷ số giữa xác suất xảy ra sự kiện đó và xác suất không xảy ra sự kiện đó. Odds thành công trong Nhóm 1: \[Odds_1 = \frac{p_1}{1-p_1} = \frac{n_{11}/n_{1.}}{n_{12}/n_{1.}} = \frac{n_{11}}{n_{12}}\] Odds thành công trong Nhóm 2: \[Odds_2 = \frac{p_2}{1-p_2} = \frac{n_{21}/n_{2.}}{n_{22}/n_{2.}} = \frac{n_{21}}{n_{22}}\]
Định nghĩa Tỷ số chênh: \[OR = \frac{Odds_1}{Odds_2}\] Ước lượng điểm: \[\widehat{OR} = \frac{\hat{p}_1 / (1-\hat{p}_1)}{\hat{p}_2 / (1-\hat{p}_2)} = \frac{n_{11}/n_{12}}{n_{21}/n_{22}} = \frac{n_{11}n_{22}}{n_{12}n_{21}}\] Đây là tỷ số của các tích chéo (cross-product ratio) trong bảng \(2 \times 2\).
Giá trị \(OR\) nằm trong khoảng \([0, \infty)\).
Nếu \(OR > 1\), odds của thành công ở Nhóm 1 cao hơn Nhóm 2.
Nếu \(OR < 1\), odds của thành công ở Nhóm 1 thấp hơn Nhóm 2.
Nếu \(OR = 1\), hai biến độc lập.
Ý nghĩa quan trọng của Odds Ratio:
Đối xứng (Symmetry): Giá trị của OR không thay đổi nếu chúng ta đổi vai trò của “thành công” và “thất bại”, hoặc đổi vai trò của Nhóm 1 và Nhóm 2 (chỉ là giá trị OR sẽ là \(1/OR_{cũ}\)). Ví dụ, OR cho “thành công” khi so sánh Nhóm 1 với Nhóm 2 bằng OR cho “Nhóm 1” khi so sánh “thành công” với “thất bại”. Điều này không đúng với RR.
Không đổi khi nhân các hàng hoặc cột với một hằng số: Điều này làm cho OR trở thành một thước đo liên hệ cơ bản, không phụ thuộc vào các tổng biên (marginals) khi mô hình là đúng.
Xấp xỉ Relative Risk khi sự kiện hiếm: Khi xác suất “thành công” \(p_1\) và \(p_2\) đều rất nhỏ (sự kiện hiếm), thì \(1-p_1 \approx 1\) và \(1-p_2 \approx 1\). Khi đó \(Odds_1 \approx p_1\), \(Odds_2 \approx p_2\), và \(OR \approx RR\). Đây là lý do OR thường được sử dụng trong các nghiên cứu bệnh chứng (case-control studies) để ước lượng RR.
Nền tảng cho mô hình hồi quy logistic: Logit của xác suất, \(\log(p/(1-p))\), chính là log-odds, và mô hình hồi quy logistic mô hình hóa logit này. OR là một cách tự nhiên để diễn giải các tham số trong mô hình logistic.
Giống như RR, phân phối của \(\widehat{OR}\) thường bị lệch, nên ta làm việc với \(\log(\widehat{OR})\).
Sai số chuẩn của \(\log(\widehat{OR})\) (theo Woolf, 1955): \[SE(\log(\widehat{OR})) = \sqrt{\frac{1}{n_{11}} + \frac{1}{n_{12}} + \frac{1}{n_{21}} + \frac{1}{n_{22}}}\] *Lưu ý: Công thức này yêu cầu tất cả các ô \(n_{ij} > 0\). Nếu có ô bằng 0, cần cộng 0.5 vào tất cả các ô - gọi là phương pháp Haldane-Anscombe.
Khoảng tin cậy (95%) cho \(\log(OR)\) là: \[\log(\widehat{OR}) \pm z_{\alpha/2} \times SE(\log(\widehat{OR}))\]
Các trường hợp sử dụng
Hiệu số tỷ lệ (\(D\)): Dễ hiểu, trực tiếp đo lường sự khác biệt tuyệt đối. Tuy nhiên, giá trị của nó phụ thuộc vào mức cơ sở của tỷ lệ (ví dụ, khác biệt giữa 0.5 và 0.7 có thể khác với giữa 0.01 và 0.21 về mặt tương đối).
Tỷ số nguy cơ (\(RR\)): Dễ diễn giải trong các nghiên cứu mà các quan sát là đồng nhất (thuần tập - cohort studies) hoặc thử nghiệm lâm sàng ngẫu nhiên có đối chứng (RCTs) khi chúng ta muốn biết “nguy cơ” của một kết quả trong nhóm này gấp bao nhiêu lần nhóm kia.
Tỷ số chênh (\(OR\)): Rất hữu ích trong nghiên cứu bệnh chứng, có các thuộc tính toán học tốt, và là thước đo cơ bản trong các mô hình GLM cho dữ liệu nhị phân (như hồi quy logistic). Khi sự kiện là phổ biến, \(OR\) có thể khác biệt đáng kể so với \(RR\) và diễn giải của \(OR\) cần cẩn thận (là tỷ số của odds, không phải tỷ số của xác suất).
Ví dụ với dữ liệu Mobile Banking (bảng 2x2 được rút gọn): Giả sử chúng ta chỉ so sánh nhóm “Trẻ” và “Cao tuổi” về việc sử dụng Mobile Banking.
Diễn giải: Tỷ lệ người trẻ dùng Mobile Banking cao hơn người cao tuổi khoảng 60 điểm phần trăm. Chúng ta tin tưởng 95% rằng sự khác biệt thực sự nằm trong khoảng (45.7%, 74.3%).
Diễn giải: Người trẻ có khả năng sử dụng Mobile Banking cao gấp 4 lần so với người cao tuổi. Chúng ta tin tưởng 95% rằng tỷ số này nằm trong khoảng (2.27, 7.04).
KTC 95% cho \(OR\): \((\exp(1.8780), \exp(3.6672)) \Rightarrow (6.539, 39.140)\).
Diễn giải: Odds của việc sử dụng Mobile Banking ở người trẻ cao gấp 16 lần odds của việc sử dụng Mobile Banking ở người cao tuổi. Chúng ta tin tưởng 95% rằng tỷ số chênh này nằm trong khoảng (6.54, 39.14).
Thực hiện bằng R: Chúng ta có thể sử dụng gói như epitools hoặc tự tính toán.
# Tạo ma trận dữ liệu cho ví dụ# Trẻ CaoTuoi# CóMB 60 10# KoMB 15 40table_2x2_mb <-matrix(c(60, 15, 10, 40), nrow =2, byrow =FALSE) # Nhập theo cộtdimnames(table_2x2_mb) <-list(SD_MB =c("Có", "Không"),NhomTuoi =c("Trẻ", "CaoTuổi"))# print("Bảng 2x2 rút gọn:")# print(table_2x2_mb)# Các giá trị n_ijn11 <- table_2x2_mb[1,1] # Có MB, Trẻn12 <- table_2x2_mb[2,1] # Không MB, Trẻn21 <- table_2x2_mb[1,2] # Có MB, CaoTuổin22 <- table_2x2_mb[2,2] # Không MB, CaoTuổi# Tính p1_hat và p2_hat (tỷ lệ dùng MB ở nhóm Trẻ và nhóm CaoTuổi)n1_dot <-sum(table_2x2_mb[,1]) # Tổng nhóm Trẻn2_dot <-sum(table_2x2_mb[,2]) # Tổng nhóm CaoTuổip1_hat <- n11 / n1_dotp2_hat <- n21 / n2_dot# 1. Hiệu số hai tỷ lệD_hat <- p1_hat - p2_hatSE_D_hat <-sqrt( (p1_hat*(1-p1_hat)/n1_dot) + (p2_hat*(1-p2_hat)/n2_dot) )D_ci_lower <- D_hat -1.96* SE_D_hatD_ci_upper <- D_hat +1.96* SE_D_hat# 2. Tỷ số nguy cơ (RR)RR_hat <- p1_hat / p2_hatlog_RR_hat <-log(RR_hat)SE_log_RR_hat <-sqrt( ((1-p1_hat)/n11) + ((1-p2_hat)/n21) ) log_RR_ci_lower <- log_RR_hat -1.96* SE_log_RR_hatlog_RR_ci_upper <- log_RR_hat +1.96* SE_log_RR_hatRR_ci_lower <-exp(log_RR_ci_lower)RR_ci_upper <-exp(log_RR_ci_upper)# 3. Tỷ số chênh (OR)OR_hat <- (n11 * n22) / (n12 * n21)log_OR_hat <-log(OR_hat)SE_log_OR_hat <-sqrt( (1/n11) + (1/n12) + (1/n21) + (1/n22) )log_OR_ci_lower <- log_OR_hat -1.96* SE_log_OR_hatlog_OR_ci_upper <- log_OR_hat +1.96* SE_log_OR_hatOR_ci_lower <-exp(log_OR_ci_lower)OR_ci_upper <-exp(log_OR_ci_upper)# Sử dụng gói epitoolslibrary(epitools)# Bảng cần nhập cho oddsratio() hoặc riskratio() của epitools thường là:# disease_yes | disease_no# exposed a | b# unexposed c | depitools_input_table <-matrix(c(60, 10, 15, 40), nrow=2, byrow =TRUE)dimnames(epitools_input_table) <-list(NhomTuoi =c("Trẻ", "CaoTuổi"),SD_MB =c("Có", "Không"))# rr_epitools <- riskratio.wald(epitools_input_table)# cat("\nSử dụng epitools::riskratio.wald:\n")# print(rr_epitools$measure) # or_epitools <- oddsratio.wald(epitools_input_table)# cat("\nSử dụng epitools::oddsratio.wald:\n")# print(or_epitools$measure)
3.3 Kiểm định tính độc lập trong bảng hai chiều
Một câu hỏi cơ bản khi phân tích bảng ngẫu nhiên hai chiều là: “Liệu có mối liên hệ nào giữa hai biến định tính \(X\) và \(Y\) không?” Điều này tương đương với việc kiểm định giả thuyết về tính độc lập thống kê giữa \(X\) và \(Y\).
Giả thuyết không (\(H_0\)): \(X\) và \(Y\) là độc lập.
Giả thuyết đối (\(H_1\)): \(X\) và \(Y\) không độc lập (có liên hệ).
Nếu \(H_0\) đúng, thì xác suất một quan sát rơi vào ô \((i,j)\) là \(P(X=X_i \text{ and } Y=Y_j) = P(X=X_i) \times P(Y=Y_j) = p_{i.} \times p_{.j}\). Do đó, tần số kỳ vọng (expected frequency) trong ô \((i,j)\) với giả thuyết độc lập là \(m_{ij} = n \times p_{i.} \times p_{.j}\). Ước lượng \(m_{ij}\) bằng \(\hat{m}_{ij} = \frac{n_{i.} n_{.j}}{n}\).
Ba kiểm định phổ biến cho tính độc lập là:
3.3.1 Kiểm định Chi-bình phương Pearson (\(\chi^2\))
Kiểm định Chi-bình phương Pearson là một trong những kiểm định phổ biến nhất để kiểm tra tính độc lập giữa hai biến định tính trong bảng hai chiều. kiểm định này so sánh tần số quan sát \(n_{ij}\) với tần số kỳ vọng \(\hat{m}_{ij}\) dưới giả thuyết độc lập. Thống kê kiểm định Pearson được tính bằng công thức:
Với giả thuyết \(H_0\) (tính độc lập) và khi cở mẫu \(n\) đủ lớn, thống kê \(\chi^2\) xấp xỉ tuân theo phân phối Chi-bình phương (\(\chi^2\)) với số bậc tự do (degrees of freedom - df) là: \(df = (I-1)(J-1)\)
Quy tắc quyết định:
Tính giá trị \(X^2\) từ dữ liệu.
So sánh \(\chi^2\) với giá trị tới hạn \(\chi^2_{\alpha, df}\) từ bảng phân phối Chi-bình phương ở mức ý nghĩa \(\alpha\) cho trước (ví dụ \(\alpha=0.05\)). Nếu \(\chi^2 > \chi^2_{\alpha, df}\), bác bỏ \(H_0\).
Điều kiện áp dụng: Kiểm định Chi-bình phương Pearson cho kết quả xấp xỉ tốt khi:
Tất cả tần số kỳ vọng \(\hat{m}_{ij} \ge 1\).
Không quá 20% số ô có tần số kỳ vọng \(\hat{m}_{ij} < 5\). Nếu điều kiện này không được thỏa mãn, đặc biệt với các bảng có nhiều ô hoặc cở mẫu nhỏ, nên xem xét Kiểm định chính xác Fisher.
3.3.2 Kiểm định Chi-bình phương tỷ số hợp lý
Kiểm định Chi-bình phương tỷ số hợp lý(Likelihood Ratio Chi-squared Test - \(G^2\)) là một biến thể của kiểm định Chi-bình phương Pearson, thường được sử dụng trong các mô hình phức tạp hơn và còn được gọi là kiểm định G (G-test). Kiểm định này dựa trên so sánh likelihood của mô hình bão hòa (saturated model - mô hình mô tả dữ liệu hoàn hảo, \(\hat{m}_{ij} = n_{ij}\)) với likelihood của mô hình dưới giả thuyết độc lập (fitted model - \(\hat{m}_{ij} = \frac{n_{i.}n_{.j}}{N}\)). \[G^2 = 2 \sum_{i=1}^{I} \sum_{j=1}^{J} n_{ij} \log\left(\frac{n_{ij}}{\hat{m}_{ij}}\right)\] (trong đó \(\log\) là logarit tự nhiên, và nếu \(n_{ij}=0\) thì số hạng \(n_{ij} \log(n_{ij}/\hat{m}_{ij})\) được coi là 0).
Với giả thuyết \(H_0\) và với mẫu lớn, \(G^2\) cũng xấp xỉ tuân theo phân phối \(\chi^2\) với \(df = (I-1)(J-1)\). \(G^2\) thường được ưa chuộng hơn \(X^2\) trong các mô hình phức tạp hơn (như mô hình log-linear) vì nó có thể được phân tách thành các thành phần một cách dễ dàng hơn. Đối với mẫu lớn, \(X^2\) và \(G^2\) thường cho kết quả rất giống nhau.
3.3.3 Kiểm định chính xác Fisher
Kiểm định chính xác Fisher (Fisher’s Exact Test) là một phương pháp kiểm định tính độc lập trong bảng \(2 \times 2\) khi các bảng ngẫu nhiên có cở mẫu nhỏ, hoặc khi các điều kiện về tần số kỳ vọng của kiểm định Chi-bình phương không được đáp ứng (đặc biệt là các bảng \(2 \times 2\) có ô tần số nhỏ). Kiểm định này không dựa trên xấp xỉ phân phối Chi-bình phương mà tính toán xác suất chính xác của việc quan sát được bảng dữ liệu hiện tại (hoặc các bảng “cực đoan” hơn), với điều kiện các tổng hàng và cột được giữ cố định.
Cơ sở của kiểm định này là phân phối siêu bội (hypergeometric distribution) cho tần số ô \(n_{11}\) trong bảng \(2 \times 2\), khi các tổng hàng và tổng cột \(n_{1.}, n_{2.}, n_{.1}, n_{.2}\) là cố định: \(P(n_{11} = k) = \frac{\binom{n_{1.}}{k} \binom{n_{2.}}{n_{.1}-k}}{\binom{N}{n_{.1}}}\) Giá trị \(k\) có thể nằm trong khoảng \(\max(0, n_{1.} + n_{.1} - N)\) đến \(\min(n_{1.}, n_{.1})\).
P-value của kiểm định Fisher được tính bằng cách cộng xác suất của tất cả các bảng có thể có (với cùng tổng hàng và tổng cột) mà có mối liên hệ mạnh mẽ bằng hoặc hơn bảng đã quan sát.
P-value một phía (one-tailed): Tổng xác suất của các bảng có tần số ô \(n_{11}\) bằng hoặc “cực đoan hơn” theo một hướng nhất định.
P-value hai phía (two-tailed): Có nhiều cách định nghĩa, một cách phổ biến là cộng xác suất của tất cả các bảng có xác suất nhỏ hơn hoặc bằng xác suất của bảng quan sát được (phương pháp của Freeman-Halton), hoặc nhân đôi p-value một phía nhỏ hơn (nếu phân phối đối xứng).
Kiểm định chính xác Fisher có thể được mở rộng cho bảng \(I \times J\) tổng quát, nhưng việc tính toán trở nên phức tạp hơn nhiều.
Ví dụ kiểm định tính độc lập (dùng lại ví dụ Mobile Banking ban đầu \(2 \times 3\)):
Sử dụng Mobile Banking Nhóm tuổi
Trẻ (<30)
Trung niên (30-50)
Cao tuổi (>50)
Tổng dòng
Có
60
50
10
120
Không
15
25
40
80
Tổng cột
75
75
50
200
Thực hiện bằng R:
# Tạo ma trận dữ liệumobile_banking_data <-matrix(c(60, 15, 50, 25, 10, 40),nrow =2, byrow =FALSE)dimnames(mobile_banking_data) <-list(SD_MB =c("Có", "Không"),NhomTuoi =c("Trẻ", "TrungNiên","CaoTuổi"))print("Bảng dữ liệu Mobile Banking:")print(mobile_banking_data)# 1. Kiểm định Chi-bình phương Pearsonchi_sq_test_pearson <-chisq.test(mobile_banking_data) print(chi_sq_test_pearson)print("Tần số kỳ vọng:")print(round(chi_sq_test_pearson$expected, 2))# 2. Kiểm định Chi-bình phương tỷ số hợp lý (G-test)library(DescTools) # Cần cài đặt: install.packages("DescTools")g_test_result <-GTest(mobile_banking_data)print(g_test_result)# 3. Kiểm định chính xác Fisher (cho bảng IxJ)fisher_test_result <-fisher.test(mobile_banking_data) print(fisher_test_result)# Tạo thư mục images nếu chưa cóif (!dir.exists("images")) {dir.create("images")}
Code
library(vcd)gg <-mosaic(mobile_banking_data, shade =TRUE, labeling = labeling_residuals, main ="Mối liên hệ giữa Nhóm tuổi và Sử dụng Mobile Banking",xlab ="Nhóm tuổi", ylab ="Sử dụng Mobile Banking",gp =gpar(fill =c("skyblue", "salmon"))) # Thêm màu cho đẹp
Các kiểm định đều trả về giá trị của p - value rất nhỏ, điều này khẳng định mạnh mẽ rằng có mối liên hệ có ý nghĩa thống kê giữa nhóm tuổi và việc sử dụng dịch vụ Mobile Banking. Biểu đồ ?fig-mosaic-mb trực quan hóa điều này, cho thấy sự khác biệt đáng kể giữa tần số quan sát và kỳ vọng.
3.4 Đo mức độ phụ thuộc trong bảng hai chiều
Sau khi kiểm định Chi-bình phương (hoặc tương đương) cho thấy có mối liên hệ giữa hai biến (tức bác bỏ \(H_0\)), câu hỏi tiếp theo là: “Mối liên hệ đó mạnh đến mức nào?”. Các thước đo mức độ liên hợp (measures of association) được sử dụng để trả lời câu hỏi này. Việc lựa chọn thước đo phù hợp phụ thuộc vào:
Thang đo của các biến (cả hai đều danh nghĩa, một danh nghĩa một thứ bậc, hay cả hai đều thứ bậc).
Mục đích diễn giải (ví dụ, đối xứng hay bất đối xứng).
3.4.1 Cho biến định danh
Khi cả hai biến \(X\) và \(Y\) đều là định danh (Nominal Variables), chúng ta muốn biết mức độ mà việc biết giá trị của một biến giúp dự đoán giá trị của biến kia, hoặc mức độ chúng “đi cùng nhau”.
Hệ số Phi (\(\phi\)) Cho bảng \(2 \times 2\)\[\phi = \sqrt{\frac{\chi^2}{n}}\] Trong đó \(\chi^2\) là thống kê Chi-bình phương Pearson, \(n\) là cở mẫu.
Giá trị: \(0 \le |\phi| \le 1\). (Giá trị \(\phi\) có thể âm hoặc dương, tùy thuộc vào cách sắp xếp bảng, nhưng thường lấy giá trị tuyệt đối hoặc bình phương nó).
\(\phi = 0\) nghĩa là không có liên hệ.
\(|\phi| = 1\) nghĩa là có liên hệ hoàn hảo (nếu biết một biến thì suy ra hoàn toàn biến kia).
Đối với bảng \(2 \times 2\), \(\phi = \frac{n_{11}n_{22} - n_{12}n_{21}}{\sqrt{n_{1.}n_{2.}n_{.1}n_{.2}}}\).
Nhược điểm: Giá trị tối đa của \(\phi\) có thể nhỏ hơn 1 đối với các bảng lớn hơn \(2 \times 2\) nếu các tổng hàng và tổng cột không bằng nhau.
Hệ số Contingency của Pearson (C):\[C = \sqrt{\frac{X^2}{X^2 + n}}\]
Giá trị: \(0 \le C < 1\). \(C=0\) khi độc lập.
Ưu điểm: Luôn dương.
Nhược điểm: Giá trị tối đa của \(C\) phụ thuộc vào kích thước bảng (số dòng và cột), ví dụ với bảng \(k \times k\), \(C_{max} = \sqrt{(k-1)/k}\). Do đó, khó so sánh \(C\) giữa các bảng có kích thước khác nhau.
Hệ số Cramer’s V:\[V = \sqrt{\frac{X^2}{n \times \min(I-1, J-1)}}\] Trong đó \(I\) là số dòng, \(J\) là số cột.
Giá trị: \(0 \le V \le 1\).
\(V=0\) khi độc lập. \(V=1\) khi có liên hệ hoàn hảo (hoặc gần hoàn hảo).
Ưu điểm: \(V\) được chuẩn hóa để nằm trong khoảng [0,1] bất kể kích thước bảng. Đây là thước đo dựa trên \(\chi^2\) phổ biến nhất cho bảng \(I \times J\) với các biến danh nghĩa.
Đối với bảng \(2 \times 2\), \(V = |\phi|\).
Lambda (\(\lambda\)) - Goodman and Kruskal’s Lambda: Lambda đo lường mức độ cải thiện tương đối trong việc dự đoán biến phụ thuộc (dependent variable) khi biết biến độc lập (independent variable), so với khi không biết. Lambda có thể là đối xứng hoặc bất đối xứng.
Lambda bất đối xứng, \(\lambda_{Y|X}\) (dự đoán Y từ X): \[\lambda_{Y|X} = \frac{\sum_i \max_j(n_{ij}) - \max_j(n_{.j})}{N - \max_j(n_{.j})}\] Trong đó \(\max_j(n_{ij})\) là tần số lớn nhất trong dòng \(i\), \(\max_j(n_{.j})\) là tần số cột lớn nhất trong tổng hàng và tổng cột.
Giá trị: \(0 \le \lambda \le 1\).
\(\lambda = 0\) nghĩa là biết \(X\) không giúp cải thiện việc dự đoán \(Y\).
\(\lambda = 1\) nghĩa là biết \(X\) giúp dự đoán \(Y\) một cách hoàn hảo.
Lambda thường có giá trị nhỏ hơn các thước đo dựa trên \(\chi^2\).
Hệ số Bất định (Uncertainty Coefficient - \(U\)) - Theil’s U: Tương tự Lambda, \(U\) đo lường mức độ giảm bất định (uncertainty) của một biến khi biết biến kia, dựa trên khái niệm entropy trong lý thuyết thông tin. Có thể đối xứng hoặc bất đối xứng.
\(U_{Y|X}\) (mức độ bất định của Y giảm khi biết X).
Giá trị: \(0 \le U \le 1\).
\(U=0\) khi độc lập, \(U=1\) khi có liên hệ hoàn hảo.
3.4.2 Cho biến thứ bậc (Ordinal Variables)
Khi ít nhất một trong hai biến (hoặc cả hai) là thứ bậc, việc sử dụng các thang đo không chỉ cho biết mức độ liên hệ mà còn cả hướng của mối liên hệ (đồng biến hay nghịch biến). Các thước đo này dựa trên việc so sánh các cặp quan sát.
Cho một cặp quan sát \((x_a, y_a)\) và \((x_b, y_b)\):
Cặp đồng thuận (Concordant pair): Nếu \(x_a < x_b\) và \(y_a < y_b\) (hoặc \(x_a > x_b\) và \(y_a > y_b\)). Tức là thứ hạng của hai biến đi cùng chiều. Số cặp đồng thuận ký hiệu là \(N_C\).
Cặp nghịch đảo (Discordant pair): Nếu \(x_a < x_b\) và \(y_a > y_b\) (hoặc \(x_a > x_b\) và \(y_a < y_b\)). Tức là thứ hạng của hai biến đi ngược chiều. Số cặp nghịch đảo ký hiệu là \(N_D\).
Cặp bằng nhau trên X (Tied on X only):\(x_a = x_b\) nhưng \(y_a \ne y_b\). Ký hiệu \(T_X\).
Cặp bằng nhau trên Y (Tied on Y only):\(x_a \ne x_b\) nhưng \(y_a = y_b\). Ký hiệu \(T_Y\).
Cặp bằng nhau trên cả X và Y (Tied on X and Y):\(x_a = x_b\) và \(y_a = y_b\). Ký hiệu \(T_{XY}\).
\(|\gamma|\) càng gần 1, mối liên hệ càng mạnh. \(\gamma = 0\) khi số cặp đồng thuận bằng nghịch đảo.
Diễn giải: Cho một cặp được chọn ngẫu nhiên không có ties, \(|\gamma|\) là xác suất dự đoán đúng thứ tự của \(Y\) khi biết thứ tự của \(X\), trừ đi xác suất dự đoán sai.
Đây là một thước đo bất đối xứng, đo lường mối liên hệ khi \(Y\) được coi là biến phụ thuộc và \(X\) là biến độc lập.
Điều chỉnh cho các cặp có giá trị bằng nhau trên \(Y\) (biến phụ thuộc).
\(D_{XY}\) sẽ có \(T_X\) ở mẫu số nếu \(X\) là biến phụ thuộc.
Giá trị: \(-1 \le D_{YX} \le 1\).
3.4.3 Diễn giải và lựa chọn thước đo phù hợp
Nếu cả hai biến là danh nghĩa: Cramer’s V thường là lựa chọn tốt. Lambda và Uncertainty Coefficient cung cấp diễn giải về khả năng dự đoán.
Nếu ít nhất một biến là thứ bậc (và bạn muốn biết hướng liên hệ): Gamma, Kendall’s tau-b/tau-c, Somers’ D là phù hợp.
Gamma thường lớn nhất về giá trị tuyệt đối vì nó bỏ qua tất cả các ties.
Kendall’s tau-b phù hợp khi có nhiều ties và bảng gần vuông.
Somers’ D hữu ích khi có một biến phụ thuộc rõ ràng.
Quy ước về độ mạnh của liên hệ (ví dụ cho |V|, |Gamma|, |tau|):
0.0 - 0.1: Không đáng kể hoặc rất yếu.
0.1 - 0.3: Yếu.
0.3 - 0.5: Trung bình.
0.5: Mạnh. (Đây chỉ là hướng dẫn, cần xem xét ngữ cảnh cụ thể của bài toán).
Luôn đi kèm với p-value của kiểm định tính độc lập. Một thước đo liên hợp có thể lớn nhưng không có ý nghĩa thống kê nếu mẫu quá nhỏ. Ngược lại, với mẫu rất lớn, một mối liên hệ rất yếu cũng có thể có ý nghĩa thống kê.
Ví dụ với R (sử dụng dữ liệu Mobile Banking và dữ liệu có thứ bậc giả lập):
# Dữ liệu Mobile Banking (2x3, coi là danh nghĩa x danh nghĩa)# mobile_banking_data đã có từ phần trước# chi_sq_test_pearson <- chisq.test(mobile_banking_data)# Cramer's V# install.packages("DescTools") # Nếu chưa cólibrary(DescTools)cramer_v_mb <-CramerV(mobile_banking_data)# Lambda và Uncertainty Coefficientlambda_mb <-Lambda(mobile_banking_data, direction ="symmetric")# Hoặc "row", "col"uncertainty_mb <-UncertCoef(mobile_banking_data, direction ="symmetric")cat("Lambda (đối xứng):", round(lambda_mb, 4), "\n")cat("Uncertainty Coefficient (đối xứng):", round(uncertainty_mb, 4), "\n\n")# Ví dụ với dữ liệu thứ bậc giả lập# Mối liên hệ giữa Mức độ hài lòng (1-5) và Mức độ gắn kết (1-5)set.seed(201)hai_long_ord <-factor(sample(1:5, 100, replace =TRUE,prob =c(0.1,0.2,0.3,0.2,0.2)), ordered =TRUE)gan_ket_ord <-factor(sample(1:5, 100, replace =TRUE,prob =c(0.1,0.2,0.3,0.2,0.2)), ordered =TRUE)# Tạo một chút liên hệgan_ket_ord[hai_long_ord ==5&runif(sum(hai_long_ord==5)) <0.7] <-5gan_ket_ord[hai_long_ord ==4&runif(sum(hai_long_ord==4)) <0.6] <-sample(4:5, sum(hai_long_ord==4&runif(sum(hai_long_ord==4)) <0.6), replace=TRUE)table_ordinal <-table(hai_long_ord, gan_ket_ord)dimnames(table_ordinal) <-list(HaiLong =paste0("M",1:5), GanKet =paste0("M",1:5))print("Bảng dữ liệu thứ bậc (Hài lòng vs Gắn kết):")print(table_ordinal)# Tính các thước đo thứ bậcgamma_val <-GoodmanKruskalGamma(table_ordinal)kendall_taub <-KendallTauB(table_ordinal)somers_d_ganket_by_hailong <-SomersDelta(table_ordinal, direction ="column")# Y là cột (gan_ket)cat("Gamma:", round(gamma_val, 4), "\n")cat("Kendall's tau-b:", round(kendall_taub, 4), "\n")cat("Somers' D (dự đoán Gắn kết từ Hài lòng):", round(somers_d_ganket_by_hailong, 4), "\n")# Sử dụng hàm `assocstats` từ gói `vcd` để có nhiều thước đolibrary(vcd)assoc_stats_nominal <-assocstats(mobile_banking_data)print(assoc_stats_nominal) # Cho cả Phi, Contingency Coeff, Cramer's Vassoc_stats_ordinal <-assocstats(table_ordinal)# Sẽ báo các thước đo này không phù hợp cho thứ bậc# Với vcd, để có thước đo thứ bậc, ta có thể dùng các hàm chuyên biệt hoặc xem các gói khác# Gói `DescTools` có nhiều hàm
Các kết quả từ R sẽ cho thấy Cramer’s V cho ví dụ Mobile Banking, và Gamma, Kendall’s tau-b, Somers’ D cho ví dụ dữ liệu thứ bậc.
3.5 Bảng ngẫu nhiên nhiều chiều
Khi chúng ta có ba (hoặc nhiều hơn) biến định tính, chúng ta có thể tạo ra bảng ngẫu nhiên nhiều chiều. Ví dụ, với ba biến \(X, Y, Z\), chúng ta có thể có một bảng \(I \times J \times K\). Bảng này thực chất là một tập hợp \(K\) bảng hai chiều \(I \times J\), mỗi bảng tương ứng với một phạm trù của biến \(Z\). Biến \(Z\) được gọi là biến phân tầng (stratification variable).
Bảng ba chiều cho phép chúng ta phân tích mối liên hệ giữa hai biến \(X\) và \(Y\) trong bối cảnh của biến thứ ba \(Z\). Điều này rất hữu ích trong các nghiên cứu y tế, xã hội học, và các lĩnh vực khác, nơi mà các yếu tố bổ sung có thể ảnh hưởng đến mối liên hệ giữa hai biến chính.
3.5.1 Giới thiệu bảng ba chiều
Mục đích chính khi phân tích bảng ba chiều là để hiểu mối liên hệ giữa hai biến (ví dụ \(X\) và \(Y\)) có thay đổi hay không khi xét đến các mức độ khác nhau của biến thứ ba \(Z\).
Liên hợp biên (Marginal Association): Mối liên hệ giữa \(X\) và \(Y\) khi bỏ qua \(Z\) (tức là cộng gộp (collapsing) bảng qua các mức của \(Z\) để tạo thành một bảng \(X \times Y\) biên).
Liên hợp có điều kiện (Conditional Association): Mối liên hệ giữa \(X\) và \(Y\) tại mỗi mức cụ thể của \(Z\). Ký hiệu là \((X, Y | Z=z_k)\).
3.5.2 Khái niệm độc lập có điều kiện, liên hợp có điều kiện
Trong phân tích bảng ba chiều, chúng ta cần hiểu rõ các khái niệm về độc lập có điều kiện và phụ thuộc có điều kiện:
\(X\) và \(Y\) độc lập có điều kiện (Conditional Independence of X and Y): Nếu biết giá trị của \(Z\), thì việc biết giá trị của \(X\) không cung cấp thêm thông tin gì về \(Y\), và ngược lại. Tức là, trong mỗi bảng \((X, Y | Z=z_k)\), \(X\) và \(Y\) là độc lập.
\(X\) và \(Y\) phụ thuộc đồng nhất (Homogeneous Association): Nếu mối liên hệ giữa \(X\) và \(Y\) là như nhau ở tất cả các mức của \(Z\). Tức là, nếu dùng một thước đo phụ thuộc (ví dụ OR), thì \(OR_{XY|Z=z_1} = OR_{XY|Z=z_2} = ... = OR_{XY|Z=z_K}\). Đây là trường hợp không có tương tác bậc ba (three-way interaction) giữa \(X, Y, Z\). Nếu mối liên hệ thay đổi đáng kể qua các mức của \(Z\), thì có tương tác bậc ba.
3.5.3 Kiểm định Cochran-Mantel-Haenszel cho bảng 2x2xK
Kiểm định CMH là một công cụ mạnh mẽ để phân tích các bảng \(2 \times 2 \times K\), tức là một chuỗi \(K\) bảng \(2 \times 2\), mỗi bảng tương ứng với một tầng (stratum) của biến \(Z\). Giả sử mỗi bảng \(2 \times 2\) thứ \(k\) (tại \(Z=z_k\)) có dạng:
\(Y_1\)
\(Y_2\)
Tổng
\(X_1\)
\(n_{11k}\)
\(n_{12k}\)
\(n_{1.k}\)
\(X_2\)
\(n_{21k}\)
\(n_{22k}\)
\(n_{2.k}\)
Tổng
\(n_{.1k}\)
\(n_{.2k}\)
\(N_k\)
Kiểm định CMH kiểm tra các giả thuyết sau:
Kiểm định tính độc lập có điều kiện trung bình (Test of Conditional Independence on Average):
\(H_0\): \(X\) và \(Y\) là độc lập có điều kiện, cho trước \(Z\), và giả định \(OR_{XY|Z=z_k} = 1\) cho tất cả \(k\). Hoặc, một cách yếu hơn, \(H_0\): không có liên hệ trung bình giữa \(X\) và \(Y\) qua các tầng.
\(H_a\): Có một liên hệ trung bình giữa \(X\) và \(Y\) (ví dụ, common odds ratio \(\ne 1\)).
Thống kê kiểm định CMH (ký hiệu \(M^2_{CMH}\)) được tính bằng cách so sánh \(n_{11k}\) quan sát với kỳ vọng \(E(n_{11k}) = \frac{n_{1.k} n_{.1k}}{N_k}\) (với giả thuyết \(H_0\) đúng và với các tổng hàng và tổng cột cố định trong mỗi tầng), và tổng hợp sự khác biệt này qua \(K\) tầng. \[M^2_{CMH} = \frac{\left[ \sum_k (n_{11k} - E(n_{11k})) \right]^2}{\sum_k Var(n_{11k})}\] (Trong đó \(Var(n_{11k}) = \frac{n_{1.k} n_{2.k} n_{.1k} n_{.2k}}{N_k^2 (N_k-1)}\) có phân phối siêu bội). Giả thuyết \(H_0\) đúng và \(M^2_{CMH}\) xấp xỉ phân phối \(\chi^2\) với \(df=1\).
Ước lượng Tỷ số chênh chung (Common Odds Ratio Estimator - Mantel-Haenszel OR): Nếu giả định rằng \(OR_{XY|Z=z_k}\) là đồng nhất qua các tầng (\(OR_{common}\)), thì ước lượng Mantel-Haenszel cho \(OR_{common}\) là: \[\widehat{OR}_{MH} = \frac{\sum_k (n_{11k} n_{22k} / N_k)}{\sum_k (n_{12k} n_{21k} / N_k)}\]
Kiểm định tính đồng nhất của Odds Ratio (Test of Homogeneity of Odds Ratios - Breslow-Day Test):
\(H_0\): \(OR_{XY|Z=z_1} = OR_{XY|Z=z_2} = ... = OR_{XY|Z=z_K}\) (các OR có điều kiện là đồng nhất).
\(H_a\): Ít nhất một \(OR_{XY|Z=z_k}\) khác với các OR khác.
Thống kê Breslow-Day (hoặc các biến thể như Tarone’s adjustment) so sánh OR quan sát ở mỗi tầng với \(\widehat{OR}_{MH}\). Với với điều kiện giả thuyết \(H_0\) đúng, nó xấp xỉ phân phối \(\chi^2\) với \(df = K-1\).
Nếu p-value của kiểm định này lớn (ví dụ > 0.05), chúng ta không bác bỏ \(H_0\) và có thể chấp nhận giả định về OR đồng nhất. Khi đó, \(\widehat{OR}_{MH}\) là một ước lượng tốt cho mối liên hệ chung.
Nếu p-value nhỏ, giả định về OR đồng nhất bị vi phạm. Điều này có nghĩa là có tương tác giữa \(Z\) và mối liên hệ \(XY\). Lúc này, việc báo cáo một OR chung có thể gây hiểu lầm, và nên xem xét các OR riêng lẻ cho từng tầng.
Ví dụ R: Sử dụng bộ dữ liệu UCBAdmissions (tuyển sinh Đại học California, Berkeley). Chúng ta muốn xem xét mối liên hệ giữa Gender (Giới tính) và Admit (Trúng tuyển), có phân tầng theo Dept (Khoa). Đây là một ví dụ kinh điển của Nghịch lý Simpson.
data(UCBAdmissions)ucb_table <- UCBAdmissions# str(ucb_table) # Là một mảng 3 chiều: Admit x Gender x Dept# Kiểm định CMH# Thường biến phân tầng (Z) là biến cuối cùng trong mảng 3 chiều cho hàm mantelhaen.test# Hiện tại: Admit (X), Gender (Y), Dept (Z - có 6 khoa A-F)# Chúng ta muốn xem liên hệ Admit-Gender, kiểm soát bởi Dept.# Vậy Y là Admit, X là Gender (hoặc ngược lại, OR sẽ là nghịch đảo).# mantelhaen.test(x, y = NULL, z = NULL, ...)# x là mảng k x r x c (tầng x dòng x cột)# hoặc x là biến dòng, y là biến cột, z là biến tầng# Để sử dụng trực tiếp với UCBAdmissions, ta cần permute (hoán vị) các chiều của mảng# nếu thứ tự mặc định không phải là Tầng x Dòng x Cột# UCBAdmissions là 2 (Admit) x 2 (Gender) x 6 (Dept)# Nếu coi Dept là tầng, Admit là Dòng, Gender là Cột:ucb_permuted <-aperm(ucb_table, c(3, 1, 2)) # Dept x Admit x Gender# str(ucb_permuted)cmh_test_ucb <-mantelhaen.test(ucb_permuted)print(cmh_test_ucb)# Kết quả thường bao gồm:# - Mantel-Haenszel X-squared (kiểm định độc lập có điều kiện trung bình)# - Common Odds Ratio (ước lượng OR chung)# - Khoảng tin cậy cho Common Odds Ratio# - Kiểm định Breslow-Day cho tính đồng nhất (thường cần gói khác hoặc tính riêng)# Để có Breslow-Day test, gói `DescTools` là một lựa chọn:library(DescTools)# BreslowDayTest yêu cầu một list các bảng 2x2 hoặc một mảng 3 chiều (2x2xK)# UCBAdmissions là 2 (Admit) x 2 (Gender) x 6 (Dept).# Nếu coi Admit, Gender là hai biến quan tâm, Dept là biến phân tầng.# Input cho BreslowDayTest có thể là mảng UCBAdmissions (Admit x Gender x Dept)# BreslowDayTest(x, OR = NA, correct = FALSE) # x là một array 2x2xK.bd_test_ucb <-BreslowDayTest(ucb_table) print(bd_test_ucb)# Nếu Breslow-Day Test cho p-value nhỏ (ví dụ < 0.05), # có nghĩa là các ORs không đồng nhất qua các khoa.# Trong trường hợp UCBAdmissions, ORs thường không đồng nhất.
Đối với UCBAdmissions, mantelhaen.test có thể cho common OR (ví dụ, nam giới có odds trúng tuyển thấp hơn nữ giới một chút khi kiểm soát khoa), nhưng BreslowDayTest thường cho thấy các OR là không đồng nhất (p-value nhỏ), nghĩa là mối liên hệ giữa giới tính và trúng tuyển thay đổi tùy theo khoa. Đây là điểm mấu chốt của nghịch lý Simpson trong bộ dữ liệu này.
3.6 Phân tích bảng phân tầng và nghịch lý Simpson
3.6.1 Ý nghĩa của việc phân tầng
Phân tầng (stratification) là quá trình chia mẫu thành các nhóm con (tầng - strata) dựa trên một hoặc nhiều biến nhiễu tiềm ẩn (confounding variables). Mục đích là để:
Kiểm soát biến nhiễu: Biến nhiễu là biến liên quan đến cả biến độc lập và biến phụ thuộc, có thể làm sai lệch hoặc che giấu mối liên hệ thực sự giữa chúng. Bằng cách phân tích trong từng tầng, chúng ta loại bỏ ảnh hưởng của biến nhiễu đó.
Đánh giá tính đồng nhất của liên hệ: Xem xét liệu mối liên hệ giữa hai biến chính có giống nhau hay khác nhau qua các tầng. Nếu khác nhau, có sự tương tác (interaction effect).
Thu được ước lượng chính xác hơn: Nếu mối liên hệ là đồng nhất, việc kết hợp thông tin từ các tầng (ví dụ, dùng \(\widehat{OR}_{MH}\)) có thể cho ước lượng tổng hợp chính xác và hiệu quả hơn.
3.6.2 Nghịch lý Simpson
Nghịch lý Simpson (Simpson’s Paradox) là một hiện tượng thống kê trong đó một xu hướng hoặc mối liên hệ xuất hiện trong nhiều nhóm dữ liệu khác nhau (các tầng) nhưng biến mất hoặc thậm chí đảo ngược khi các nhóm này được gộp lại.
Điều này xảy ra khi có một biến nhiễu (lurking variable) hoặc biến phân tầng không được tính đến, và biến này có liên quan đến cả hai biến đang được nghiên cứu.
Ví dụ UCBAdmissions:
Khi gộp tất cả các khoa lại (bảng biên):
ucb_marginal <-margin.table(ucb_table, margin =c(1,2))# Bảng Admit x Genderprint(ucb_marginal)# prop.table(ucb_marginal, margin = 2)# Tỷ lệ trúng tuyển theo giới tính# chisq.test(ucb_marginal)
Kết quả gộp thường cho thấy tỷ lệ trúng tuyển của nam giới cao hơn nữ giới một cách có ý nghĩa. Điều này có vẻ như có sự thiên vị giới tính đối với nam.
Khi xét từng khoa riêng lẻ (các bảng có điều kiện): Trong nhiều khoa (đặc biệt là các khoa có tỷ lệ nộp đơn của nữ cao nhưng tỷ lệ trúng tuyển chung lại thấp hơn), tỷ lệ trúng tuyển của nữ lại bằng hoặc thậm chí cao hơn nam.
Giải thích: Nghịch lý xảy ra vì “Khoa” là một biến nhiễu. Nữ giới có xu hướng nộp đơn vào các khoa khó trúng tuyển hơn (tỷ lệ trúng tuyển chung thấp hơn), trong khi nam giới có xu hướng nộp đơn vào các khoa dễ trúng tuyển hơn (tỷ lệ trúng tuyển chung cao hơn). Khi gộp lại, ảnh hưởng của việc lựa chọn khoa này đã làm sai lệch mối quan hệ giữa giới tính và việc trúng tuyển. Mối liên hệ thực sự giữa giới tính và trúng tuyển cần được đánh giá trong từng khoa hoặc bằng cách sử dụng các phương pháp thống kê kiểm soát biến khoa (như kiểm định CMH hoặc mô hình hồi quy).
Cách nhận diện và xử lý Nghịch lý Simpson:
Luôn cảnh giác khi phân tích dữ liệu gộp, đặc biệt nếu có các yếu tố nhóm tiềm ẩn.
Nếu có thể, hãy thực hiện phân tích phân tầng dựa trên các biến nghi ngờ là nhiễu.
So sánh kết quả từ phân tích gộp với kết quả từ phân tích phân tầng. Nếu chúng khác biệt đáng kể hoặc trái ngược nhau, đó có thể là dấu hiệu của nghịch lý Simpson.
Trong trường hợp này, kết quả từ phân tích phân tầng (hoặc các mô hình kiểm soát biến nhiễu) thường phản ánh đúng hơn mối quan hệ thực sự.
Trực quan hóa dữ liệu (ví dụ, biểu đồ tỷ lệ có điều kiện) có thể giúp phát hiện.
Code
# Tạo data frame từ UCBAdmissions để dễ vẽ với ggplot2ucb_df <-as.data.frame.table(UCBAdmissions)# Tính tỷ lệ trúng tuyển theo khoa và giới tínhlibrary(dplyr)ucb_summary <- ucb_df %>%group_by(Dept, Gender, Admit) %>%summarise(Count =sum(Freq)) %>%group_by(Dept, Gender) %>%mutate(Proportion = Count /sum(Count)) %>%filter(Admit =="Admitted")# Tính tỷ lệ trúng tuyển gộp (marginal)ucb_marginal_summary <- ucb_df %>%group_by(Gender, Admit) %>%summarise(Count =sum(Freq)) %>%group_by(Gender) %>%mutate(Proportion = Count /sum(Count)) %>%filter(Admit =="Admitted") %>%mutate(Dept ="Overall") # Thêm cột Dept để gộp vào biểu đồ# Kết hợp dữ liệuplot_data <-bind_rows(ucb_summary, ucb_marginal_summary)plot_data$Dept <-factor(plot_data$Dept, levels=c(LETTERS[1:6], "Overall"))library(ggplot2)ggplot(plot_data, aes(x = Dept, y = Proportion, fill = Gender)) +geom_bar(stat ="identity", position ="dodge") +labs(title ="Tỷ lệ trúng tuyển theo Giới tính và Khoa (và Tổng thể)",x ="Khoa / Tổng thể",y ="Tỷ lệ trúng tuyển",fill ="Giới tính") +scale_y_continuous(labels = scales::percent_format()) +theme_minimal() +theme(axis.text.x =element_text(angle =45, hjust =1))# Lưu hình ảnhif (!dir.exists("images")) dir.create("images")ggsave("images/Hình_2_2.png", width=10, height=6)
(Hình 2.2) cho thấy rõ nghịch lý. Cột “Overall” (Tổng thể) cho thấy Nam có tỷ lệ trúng tuyển cao hơn. Tuy nhiên, khi nhìn vào từng Khoa (A-F), trong nhiều khoa (A, B, D, F), tỷ lệ trúng tuyển của Nữ gần bằng hoặc cao hơn Nam. Sự khác biệt lớn ở Khoa C và E, nơi Nam có tỷ lệ cao hơn, nhưng các khoa này lại có tỷ lệ nộp đơn của Nữ thấp. Điều này minh họa tầm quan trọng của việc phân tích phân tầng.
3.7 Ứng dụng R trong phân tích bảng ngẫu nhiên
R cung cấp nhiều công cụ mạnh mẽ để làm việc với bảng ngẫu nhiên.
3.7.1 Tạo và trình bày bảng ngẫu nhiên
Hàm table(): Cách cơ bản nhất để tạo bảng từ các vector factor.
Hàm xtabs() (cross-tabulation): Linh hoạt hơn, cho phép dùng công thức kiểu mô hình.
# Giả sử có data frame `df_survey` chứa các cột gioi_tinh, muc_do_hl, khu_vucdf_survey <-data.frame(gioi_tinh, muc_do_hl, khu_vuc)bang_xtabs_2d <-xtabs(~ gioi_tinh + muc_do_hl, data = df_survey)print("Bảng 2 chiều (xtabs):")print(bang_xtabs_2d)bang_xtabs_3d <-xtabs(~ gioi_tinh + muc_do_hl + khu_vuc, data = df_survey)print("Bảng 3 chiều (xtabs):")print(bang_xtabs_3d)# Nếu dữ liệu đã được tổng hợp sẵn (có cột tần số, ví dụ 'Freq')# bang_xtabs_freq <- xtabs(Freq ~ gioi_tinh + muc_do_hl, data = df_aggregated)
Hàm ftable() (flat table): Trình bày bảng nhiều chiều dưới dạng “phẳng” dễ nhìn hơn.
print("Bảng 3 chiều (ftable):")print(ftable(bang_3d)) # hoặc ftable(bang_xtabs_3d)# ftable(khu_vuc ~ gioi_tinh + muc_do_hl, data=df_survey) # Đưa khu_vuc ra làm biến dòng chính
Hàm CrossTable() từ gói gmodels: Cung cấp output rất chi tiết, bao gồm các tỷ lệ (dòng, cột, tổng), tần số kỳ vọng, phần dư, các kiểm định.
library(gmodels)print("Bảng CrossTable (gmodels):")CrossTable(df_survey$gioi_tinh, df_survey$muc_do_hl, expected =TRUE, # Hiển thị tần số kỳ vọngprop.r =TRUE, # Tỷ lệ theo dòngprop.c =TRUE, # Tỷ lệ theo cộtprop.t =TRUE, # Tỷ lệ theo tổngprop.chisq =TRUE, # Đóng góp vào Chi-squarechisq =TRUE, # Thực hiện kiểm định Chi-squarefisher =TRUE, # Thực hiện Fisher's test nếu bảng 2x2dnn =c("Giới tính", "Mức độ hài lòng")) # Tên cho các chiều
3.7.2 Trực quan hóa bảng ngẫu nhiên
Biểu đồ thanh (Bar plots):
Biểu đồ thanh nhóm (Grouped bar plot):
Biểu đồ thanh chồng (Stacked bar plot): Sử dụng barplot() (base R) hoặc geom_bar() (ggplot2).
# Base R# barplot(bang_2d, beside = TRUE, legend.text = TRUE, # main = "Hài lòng theo Giới tính (Nhóm)", xlab = "Mức độ hài lòng", ylab = "Tần số")# barplot(prop.table(bang_2d, margin = 2), legend.text = TRUE, # main = "Hài lòng theo Giới tính (Chồng, chuẩn hóa theo cột)", xlab = "Mức độ hài lòng", ylab = "Tỷ lệ")# ggplot2library(ggplot2)# df_survey_for_plot <- as.data.frame(bang_2d) # Chuyển table thành data frame để ggplot dễ dùng# Hoặc dùng df_survey trực tiếp# ggplot(df_survey, aes(x = muc_do_hl, fill = gioi_tinh)) +# geom_bar(position = "dodge") +# labs(title = "Hài lòng theo Giới tính (Nhóm)", x = "Mức độ hài lòng", y = "Số lượng")# # ggplot(df_survey, aes(x = muc_do_hl, fill = gioi_tinh)) +# geom_bar(position = "fill") + # "fill" cho tỷ lệ chồng# labs(title = "Hài lòng theo Giới tính (Chồng, tỷ lệ)", x = "Mức độ hài lòng", y = "Tỷ lệ") +# scale_y_continuous(labels = scales::percent)
Biểu đồ Mosaic (Mosaic plots) - Gói vcd: Đã giới thiệu ở Hình ?fig-mosaic-mb. Rất hiệu quả cho việc hiển thị các tần số và sự sai khác so với kỳ vọng độc lập.
3.7.3 Thực hiện các kiểm định và tính toán thước đo liên hợp
Kiểm định:
chisq.test(): Pearson’s Chi-squared test.
fisher.test(): Fisher’s Exact Test.
GTest() (gói DescTools): Likelihood Ratio G-test.
mantelhaen.test(): Cochran-Mantel-Haenszel test.
BreslowDayTest() (gói DescTools): Test for homogeneity of odds ratios.
Thước đo liên hợp:
Gói vcd hàm assocstats(): Tính Phi, Contingency Coeff, Cramer’s V.
Việc thực hành thường xuyên với các hàm này trên nhiều bộ dữ liệu khác nhau sẽ giúp bạn thành thạo kỹ năng phân tích bảng ngẫu nhiên bằng R.
3.8 Tóm tắt chương
Chương 2 đã đưa chúng ta vào thế giới của phân tích bảng ngẫu nhiên, một công cụ trung tâm trong phân tích dữ liệu định tính. Các nội dung chính bao gồm:
Cấu trúc bảng ngẫu nhiên: Hiểu rõ cách xây dựng bảng hai chiều (\(I \times J\)) từ hai biến định tính, các loại tần số (quan sát, kỳ vọng, biên, có điều kiện) và các phân phối xác suất liên quan (Poisson, Multinomial, Product Multinomial).
Phân tích bảng \(2 \times 2\): Tập trung vào việc so sánh tỷ lệ giữa hai nhóm thông qua hiệu số tỷ lệ, tỷ số nguy cơ (RR) và tỷ số chênh (OR), bao gồm cách tính toán, diễn giải và xây dựng khoảng tin cậy cho chúng.
Kiểm định tính độc lập: Nắm vững các kiểm định Chi-bình phương Pearson (\(X^2\)), Chi-bình phương tỷ số hợp lý (\(G^2\)), và Kiểm định chính xác Fisher để đánh giá liệu có mối liên hệ thống kê giữa hai biến hay không.
Đo lường mức độ liên hợp: Học cách lựa chọn và tính toán các thước đo phù hợp để đánh giá độ mạnh của mối liên hệ, bao gồm các thước đo cho biến danh nghĩa (Phi, Cramer’s V, Lambda, Uncertainty Coefficient) và cho biến thứ bậc (Gamma, Kendall’s tau-b/c, Somers’ D).
Bảng nhiều chiều và phân tầng: Mở rộng sang phân tích bảng ba chiều (\(K \times I \times J\)), hiểu khái niệm độc lập có điều kiện, liên hợp có điều kiện, và kiểm định Cochran-Mantel-Haenszel (CMH) để kiểm soát biến phân tầng. Đặc biệt, đã tìm hiểu về Nghịch lý Simpson và tầm quan trọng của việc phân tích phân tầng để tránh kết luận sai lệch.
Ứng dụng R: Thực hành cách tạo, trình bày, trực quan hóa (biểu đồ thanh, mosaic) và thực hiện các kiểm định, tính toán thước đo liên hợp cho bảng ngẫu nhiên bằng các hàm và gói R phổ biến (table, xtabs, ftable, CrossTable, chisq.test, fisher.test, mantelhaen.test, vcd, DescTools, epitools, ggplot2).
Kiến thức từ chương này là nền tảng vững chắc để tiếp tục khám phá các mô hình hồi quy cho dữ liệu định tính trong các chương tiếp theo, nơi mà các khái niệm như Odds Ratio sẽ được phát triển sâu hơn.
3.9 Case studies
Case Study 2.1: Chiến dịch Email Marketing và Tỷ lệ chuyển đổi
Bối cảnh: Một công ty thương mại điện tử muốn đánh giá hiệu quả của hai mẫu email marketing (Mẫu A - tiêu đề cũ, Mẫu B - tiêu đề mới) đối với tỷ lệ khách hàng nhấp vào liên kết và thực hiện mua hàng. Họ gửi Mẫu A cho 500 khách hàng và Mẫu B cho 500 khách hàng khác (chọn ngẫu nhiên).
Kết quả:
Mẫu A: 50 người mua hàng.
Mẫu B: 75 người mua hàng.
Nhiệm vụ:
Xây dựng bảng \(2 \times 2\) cho dữ liệu này.
Tính hiệu số tỷ lệ mua hàng, tỷ số nguy cơ (RR) và tỷ số chênh (OR) giữa Mẫu B so với Mẫu A. Tính khoảng tin cậy 95% cho các thước đo này.
Sử dụng kiểm định Chi-bình phương để xem sự khác biệt có ý nghĩa thống kê không.
Phân tích bằng R:
# Dữ liệu# MuaHang_Co MuaHang_Ko Tong# Mau_A 50 450 500# Mau_B 75 425 500email_data <-matrix(c(50, 75, 450, 425), nrow =2, byrow =TRUE)dimnames(email_data) <-list(MauEmail =c("A", "B"), MuaHang =c("Có", "Không"))print(email_data)# Tính tỷ lệp_A <- email_data["A", "Có"] /sum(email_data["A",])p_B <- email_data["B", "Có"] /sum(email_data["B",])# Hiệu số tỷ lệ (B so với A)diff_prop_B_A <- p_B - p_A# SE và KTC (dùng prop.test cho chính xác hơn)prop_test_res <-prop.test(x =c(email_data["B", "Có"], email_data["A", "Có"]),n =c(sum(email_data["B",]), sum(email_data["A",])),correct =FALSE) # Không dùng Yates' correctionprint(prop_test_res)cat("Hiệu số tỷ lệ (p_B - p_A):", round(diff_prop_B_A,4), "\n")cat("KTC 95% cho hiệu số:", round(prop_test_res$conf.int,4),"\n\n")# RR và OR (sử dụng epitools cho Mẫu B là 'exposed', Mẫu A là 'unexposed')# Bảng cho epitools:# Mua_Co Mua_Ko# Mau_B 75 425 (exposed)# Mau_A 50 450 (unexposed)epitools_email_data <-matrix(c(75, 50, 425, 450), nrow =2, byrow =TRUE) # B là hàng 1dimnames(epitools_email_data) <-list(MauEmail =c("B_exposed", "A_unexposed"), MuaHang =c("Có", "Không"))library(epitools)rr_email <-riskratio.wald(epitools_email_data)or_email <-oddsratio.wald(epitools_email_data)cat("Tỷ số nguy cơ (RR) của Mẫu B so với Mẫu A:\n")print(rr_email$measure)cat("\nTỷ số chênh (OR) của Mẫu B so với Mẫu A:\n")print(or_email$measure)# Kiểm định Chi-bình phươngchi_test_email <-chisq.test(email_data)print(chi_test_email)
Case Study 2.2: Mối liên hệ giữa Loại hình công việc và Mức độ Stress
Bối cảnh: Một nghiên cứu khảo sát 300 nhân viên văn phòng về loại hình công việc của họ (Quản lý, Chuyên viên, Hỗ trợ) và mức độ stress họ cảm nhận (Thấp, Trung bình, Cao).
Dữ liệu giả định: | Loại CV Stress | Thấp | Trung bình | Cao | |—————–|——|————|—–| | Quản lý | 10 | 25 | 35 | (Tổng 70) | Chuyên viên | 30 | 60 | 50 | (Tổng 140) | Hỗ trợ | 40 | 30 | 20 | (Tổng 90)
Nhiệm vụ:
Kiểm định xem có mối liên hệ giữa loại hình công việc và mức độ stress không.
Nếu có, tính toán một thước đo liên hợp phù hợp (ví dụ, Cramer’s V) và diễn giải.
Cả hai biến đều có thể coi là thứ bậc. Hãy tính Gamma để xem hướng và độ mạnh của liên hệ.
Phân tích bằng R:
stress_data <-matrix(c(10,30,40, 25,60,30, 35,50,20), nrow=3, byrow=FALSE)dimnames(stress_data) <-list(LoaiCV =c("Quản lý", "Chuyên viên", "Hỗ trợ"),MucStress =c("Thấp", "Trung bình", "Cao"))print(stress_data)# Kiểm định Chi-bình phươngchi_test_stress <-chisq.test(stress_data)print(chi_test_stress) # Có liên hệ (p-value nhỏ)# Cramer's Vlibrary(DescTools)cramer_v_stress <-CramerV(stress_data)cat("Cramer's V:", round(cramer_v_stress, 4), "\n")# Gamma (cần đảm bảo factor là ordered nếu không DescTools sẽ báo warning)# Chuyển thành data frame với factor thứ bậc để DescTools hoạt động tốt hơn với Gammadf_stress <-as.data.frame.table(stress_data, responseName ="Freq")df_stress$LoaiCV <-factor(df_stress$LoaiCV, levels =c("Hỗ trợ", "Chuyên viên", "Quản lý"), ordered =TRUE)df_stress$MucStress <-factor(df_stress$MucStress, levels =c("Thấp", "Trung bình", "Cao"), ordered =TRUE)# Cần "bung" data frame theo Freq để dùng trực tiếp các hàm này trên cặp biến# Hoặc dùng trên table đã có:# Để tính Gamma, thứ tự các mức là quan trọng. # "Quản lý" có thể coi là cao hơn "Hỗ trợ".# Sắp xếp lại bảng nếu cần cho diễn giải Gamma dễ hơn (VD: từ thấp đến cao)# Giả sử thứ tự hiện tại là OK (Quản lý > Chuyên viên > Hỗ trợ và Cao > Trung bình > Thấp)# Để gamma dương nếu stress tăng theo cấp bậc công việc# Tính lại ma trận với các factor đã có thứ tựstress_table_ordered <-xtabs(Freq ~ LoaiCV + MucStress, data=df_stress)gamma_stress <-GoodmanKruskalGamma(stress_table_ordered)cat("Gamma:", round(gamma_stress, 4), "\n")# Nếu Gamma âm, nghĩa là LoaiCV (theo thứ tự Hỗ trợ < CV < QL) có liên hệ nghịch với Stress # (Thấp < TB < Cao). Ví dụ, nếu QL có stress cao hơn.# Để có Gamma dương, có thể đảo ngược một trong các thang đo:# df_stress$LoaiCV_rev <- factor(df_stress$LoaiCV, # levels = rev(levels(df_stress$LoaiCV)), ordered = TRUE)# stress_table_rev <- xtabs(Freq ~ LoaiCV_rev + MucStress, data=df_stress)# gamma_stress_rev <- GoodmanKruskalGamma(stress_table_rev)# cat("Gamma (LoaiCV_rev):", round(gamma_stress_rev, 4), "\n")
Gamma âm (ví dụ -0.2956) cho thấy khi LoaiCV tăng (Hỗ trợ -> Chuyên viên -> Quản lý), MucStress cũng có xu hướng tăng. Để diễn giải “mức độ công việc càng cao, stress càng cao” thì Gamma nên dương. Điều này phụ thuộc vào cách bạn định nghĩa “cao hơn” cho LoaiCV. Nếu “Quản lý” là cao nhất và “Hỗ trợ” là thấp nhất, và “Stress Cao” là cao nhất, “Stress Thấp” là thấp nhất, thì Gamma dương thể hiện mối quan hệ đồng biến.
Case Study 2.3: Đánh giá Thuốc mới - Ảnh hưởng của Độ tuổi
Bối cảnh: Một thử nghiệm lâm sàng đánh giá hiệu quả của một loại thuốc mới (Thuốc Mới) so với giả dược (Placebo) trong việc điều trị một bệnh. Kết quả là “Cải thiện” hoặc “Không cải thiện”. Các nhà nghiên cứu nghi ngờ độ tuổi của bệnh nhân có thể ảnh hưởng đến hiệu quả.
Dữ liệu được thu thập và phân tầng theo hai nhóm tuổi: “Trẻ” (<50 tuổi) và “Già” (\(\ge\) 50 tuổi).
Nhóm Trẻ: | Điều trị KQ | Cải thiện | Không CT | |—————|———–|———-| | Thuốc Mới | 40 | 10 | (Tổng 50) | Placebo | 20 | 30 | (Tổng 50)
Nhóm Già: | Điều trị KQ | Cải thiện | Không CT | |—————|———–|———-| | Thuốc Mới | 30 | 20 | (Tổng 50) | Placebo | 10 | 40 | (Tổng 50)
Nhiệm vụ:
Tính Odds Ratio (OR) cho hiệu quả của Thuốc Mới so với Placebo trong mỗi nhóm tuổi.
Sử dụng kiểm định Breslow-Day để xem các OR này có đồng nhất không.
Nếu đồng nhất, tính \(\widehat{OR}_{MH}\) chung. Sử dụng kiểm định CMH để đánh giá hiệu quả trung bình của thuốc khi kiểm soát độ tuổi.
Phân tích bằng R:
# Tạo mảng 3 chiều: KQ (2) x Điều trị (2) x Nhóm tuổi (2)# Mức: Cải thiện, Không CT ; Thuốc Mới, Placebo ; Trẻ, Giàdata_tre <-matrix(c(40,20, 10,30), nrow=2, byrow=FALSE) # Cải thiện, Không CT theo cộtdimnames(data_tre) <-list(DieuTri=c("Thuốc Mới", "Placebo"), KetQua=c("Cải thiện", "Không CT"))data_gia <-matrix(c(30,10, 20,40), nrow=2, byrow=FALSE)dimnames(data_gia) <-list(DieuTri=c("Thuốc Mới", "Placebo"), KetQua=c("Cải thiện", "Không CT"))# Kết hợp thành mảng 3 chiều# Cần thứ tự (Điều trị x Kết quả x Nhóm tuổi) cho mantelhaen.test để # phân tầng theo Nhóm tuổi, dòng là Điều trị, cột là Kết quảdrug_effect_array <-array(NA, dim =c(2, 2, 2), dimnames =list(DieuTri =c("Thuốc Mới", "Placebo"),KetQua =c("Cải thiện", "Không CT"),NhomTuoi =c("Trẻ", "Già")))drug_effect_arraydrug_effect_array[,,"Trẻ"] <- data_tredrug_effect_array[,,"Già"] <- data_giaprint("Bảng cho nhóm Trẻ:")print(drug_effect_array[,,"Trẻ"])or_tre <- (drug_effect_array[1,1,"Trẻ"] * drug_effect_array[2,2,"Trẻ"]) / (drug_effect_array[1,2,"Trẻ"] * drug_effect_array[2,1,"Trẻ"])cat("OR Thuốc mới vs Placebo (Trẻ):", or_tre, "\n") # (40*30)/(10*20) = 1200/200 = 6print("Bảng cho nhóm Già:")print(drug_effect_array[,,"Già"])or_gia <- (drug_effect_array[1,1,"Già"] * drug_effect_array[2,2,"Già"]) / (drug_effect_array[1,2,"Già"] * drug_effect_array[2,1,"Già"])cat("OR Thuốc mới vs Placebo (Già):", or_gia, "\n\n") # (30*40)/(20*10) = 1200/200 = 6# Kiểm định Breslow-Daylibrary(DescTools)# Input cho BreslowDayTest là mảng 2x2xK (trong TH này KQ x DieuTri x NhomTuoi)# Hoặc chúng ta cần đưa NhomTuoi (phân tầng) ra chiều cuối cùng# drug_effect_array đã đúng dạng: Điều trị x Kết quả x Nhóm tuổi (2x2x2)# (ngầm định hàng là Exposed, cột là Disease Status)bd_test_drug <-BreslowDayTest(drug_effect_array)print(bd_test_drug) # P-value rất lớn (gần 1), không bác bỏ H0 -> ORs là đồng nhất (thực tế bằng nhau trong ví dụ này).# Kiểm định CMHcmh_test_drug <-mantelhaen.test(drug_effect_array)print(cmh_test_drug)# Common OR sẽ là 6.0. P-value của CMH test rất nhỏ.# Kết luận: Thuốc mới hiệu quả hơn giả dược (OR=6), mối liên hệ này đồng nhất qua 2 nhóm tuổi.
Case Study 2.4: Mối liên hệ giữa Tình trạng Việc làm và Sở hữu Nhà
Bối cảnh: Ngân hàng muốn xem xét liệu tình trạng việc làm của khách hàng (“Ổn định”, “Không ổn định”, “Thất nghiệp”) có liên quan đến việc họ có sở hữu nhà hay không (“Có”, “Không”).
Nhiệm vụ:
Tạo bảng \(3 \times 2\) từ dữ liệu khảo sát giả định (ví dụ 500 khách hàng).
Kiểm tra tính độc lập.
Nếu có liên hệ, tính toán một thước đo liên hợp phù hợp. Xem xét dùng Somers’ D nếu “Sở hữu nhà” là biến phụ thuộc.
Phân tích bằng R:
set.seed(204)tinh_trang_vl_levels <-c("Ổn định", "Không ổn định", "Thất nghiệp")so_huu_nha_levels <-c("Có", "Không")tinh_trang_vl_data <-sample(tinh_trang_vl_levels, 500, replace =TRUE, prob =c(0.6, 0.3, 0.1))# Tạo liên hệ: người có việc làm ổn định có khả năng sở hữu nhà cao hơnso_huu_nha_data <-character(500)so_huu_nha_data[tinh_trang_vl_data =="Ổn định"] <-sample(so_huu_nha_levels, sum(tinh_trang_vl_data =="Ổn định"), replace=TRUE, prob=c(0.7, 0.3))so_huu_nha_data[tinh_trang_vl_data =="Không ổn định"] <-sample(so_huu_nha_levels, sum(tinh_trang_vl_data =="Không ổn định"), replace=TRUE, prob=c(0.4, 0.6))so_huu_nha_data[tinh_trang_vl_data =="Thất nghiệp"] <-sample(so_huu_nha_levels, sum(tinh_trang_vl_data =="Thất nghiệp"), replace=TRUE, prob=c(0.1, 0.9))df_vl_shn <-data.frame(TinhTrangVL =factor(tinh_trang_vl_data, levels = tinh_trang_vl_levels, ordered =TRUE),SoHuuNha =factor(so_huu_nha_data, levels = so_huu_nha_levels))table_vl_shn <-xtabs(~ TinhTrangVL + SoHuuNha, data=df_vl_shn)print(table_vl_shn)# Kiểm định độc lậpchi_test_vl_shn <-chisq.test(table_vl_shn)print(chi_test_vl_shn) # Có liên hệ# Thước đo liên hợplibrary(DescTools)cramer_v_vl_shn <-CramerV(table_vl_shn)cat("Cramer's V:", round(cramer_v_vl_shn, 4), "\n")# Somers' D (Sở hữu nhà là biến phụ thuộc Y - cột, Tình trạng VL là X - dòng)# DescTools::SomersDelta(table_vl_shn, direction = "column") # Nếu SoHuuNha là "Có" < "Không" (không hợp lý)# Cần định nghĩa thứ bậc cho SoHuuNha nếu muốn Gamma/SomersD có ý nghĩa hướng# Nếu chỉ coi "Có" vs "Không" là danh nghĩa, Cramer's V là đủ# Nếu muốn coi Tình trạng VL (Thất nghiệp < Không ổn định < Ổn định) là X# và Sở hữu nhà (Không < Có) là Y.df_vl_shn$SoHuuNha_ord <-factor(df_vl_shn$SoHuuNha, levels=c("Không", "Có"), ordered =TRUE)table_vl_shn_ord <-xtabs(~ TinhTrangVL + SoHuuNha_ord, data=df_vl_shn)somers_d_shn_by_vl <-SomersDelta(table_vl_shn_ord, direction="column")cat("Somers' D (Sở hữu nhà (Cột) bởi Tình trạng VL (Dòng)):", round(somers_d_shn_by_vl, 4), "\n") # Somers' D dương cho thấy khi tình trạng việc làm "tốt hơn" (theo thứ tự đã định), # khả năng sở hữu nhà cũng "cao hơn" (Không -> Có).
Case Study 2.5: Phân tích bộ dữ liệu HairEyeColor
Bối cảnh: Bộ dữ liệu HairEyeColor có sẵn trong R ghi lại tần suất của màu tóc, màu mắt và giới tính của 592 sinh viên thống kê.
Nhiệm vụ:
Khám phá mối liên hệ giữa Màu tóc (Hair) và Màu mắt (Eye).
Kiểm tra xem mối liên hệ này có đồng nhất giữa Nam (Male) và Nữ (Female) không, sử dụng phân tích phân tầng và kiểm định CMH/Breslow-Day (nếu phù hợp - HairEyeColor là 4x4x2).
Trực quan hóa bằng biểu đồ mosaic.
Phân tích bằng R:
data(HairEyeColor)str(HairEyeColor) # Mảng 3 chiều: Hair x Eye x Sex# 1. Mối liên hệ giữa Hair và Eye (gộp qua Sex)hair_eye_marginal <-margin.table(HairEyeColor, margin =c(1,2)) # Hair x Eyeprint("Bảng Hair vs Eye (gộp):")print(hair_eye_marginal)chi_test_hair_eye <-chisq.test(hair_eye_marginal)print(chi_test_hair_eye) # Rất có ý nghĩalibrary(DescTools)cramer_v_hair_eye <-CramerV(hair_eye_marginal)cat("Cramer's V (Hair vs Eye, gộp):", round(cramer_v_hair_eye, 4), "\n\n") # ~0.27, trung bình yếu# 2. Phân tích phân tầng theo Sex# Kiểm định Breslow-Day cho tính đồng nhất của OR (không trực tiếp áp dụng cho 4x4)# Chúng ta có thể xem xét các OR cho các cặp 2x2 cụ thể nếu cần.# Hoặc kiểm tra sự khác biệt trong cấu trúc liên hệ.# Kiểm định CMH - mantelhaen.test dùng cho bảng K x R x C (Tầng x Dòng x Cột)# Nếu muốn xem liên hệ Hair-Eye, phân tầng theo Sex:# Sex (tầng), Hair (dòng), Eye (cột)# HairEyeColor là Hair (dòng) x Eye (cột) x Sex (tầng)# Chuyển Sex ra chiều đầu tiênhec_permuted <-aperm(HairEyeColor, c(3,1,2)) # Sex x Hair x Eye# mantelhaen.test thường dùng cho các biến nhị phân (R,C = 2)# Nếu các biến có nhiều hơn 2 mức, nó sẽ kiểm tra mối tương quan tuyến tính trung bình# (general association / mean score correlation) nếu scores được cung cấp, # hoặc đối với biến thứ bậc. # Đối với biến danh nghĩa thuần túy RxC (R,C > 2), CMH phức tạp hơn và# R có thể không thực hiện kiểm định này một cách trực tiếp cho tính độc lập có điều kiện chung.# Xem xét các phương pháp mô hình log-linear (Chương 5) là tốt hơn cho trường hợp này.# Tuy nhiên, chúng ta có thể minh họa bằng cách "thu gọn" bảng# Ví dụ: Tóc Nâu vs Tóc Vàng, Mắt Nâu vs Mắt Xanh, phân tầng theo giới tính# hec_subset <- HairEyeColor[c("Brown", "Blond"), c("Brown", "Blue"), ]# mantelhaen.test(hec_subset) # Hoặc chúng ta có thể tính toán và so sánh các thước đo liên hệ cho Nam và Nữ riênghair_eye_male <- HairEyeColor[,, "Male"]hair_eye_female <- HairEyeColor[,, "Female"]cat("Cramer's V (Hair vs Eye) cho Nam:", round(CramerV(hair_eye_male), 4), "\n")cat("Cramer's V (Hair vs Eye) cho Nữ:", round(CramerV(hair_eye_female), 4), "\n")# So sánh hai giá trị Cramer's V này.# 3. Trực quan hóalibrary(vcd)# Biểu đồ mosaic gộp# mosaic(hair_eye_marginal, shade=TRUE, main="Hair vs Eye (Gộp)")# Biểu đồ mosaic có điều kiện (phân tầng)# Hình 2.3: Mối liên hệ giữa Màu Tóc và Màu Mắt, phân tầng theo Giới tínhpng(filename="images/Hình_2_3.png", width=1200, height=600)mosaic(~ Hair + Eye | Sex, data = HairEyeColor, shade =TRUE,main="Mối liên hệ Màu Tóc - Màu Mắt, phân tầng theo Giới tính",labeling_args =list(abbreviate =c(Hair=TRUE, Eye=TRUE), rot_labels =c(bottom =45,left=0),just_labels =c(bottom ="right", left="center")),gp_labels =gpar(fontsize=10),legend_args =list(fontsize=10))dev.off()
Hình ?fig-mosaic-conditional (sẽ được tạo là Hình 2.3) sẽ hiển thị hai biểu đồ mosaic, một cho Nam và một cho Nữ, cho phép so sánh trực quan cấu trúc liên hệ giữa màu tóc và màu mắt trong mỗi nhóm giới tính. Cramer’s V cho Nam (~0.32) và Nữ (~0.25) có thể cho thấy mức độ liên hệ hơi khác nhau một chút.
3.10 Bài tập
3.10.1 Bài tập lý thuyết
Giải thích sự khác biệt giữa tần số quan sát, tần số kỳ vọng, tần số biên và tần số có điều kiện trong một bảng ngẫu nhiên hai chiều.
Nêu ba cách chính để so sánh hai tỷ lệ trong bảng \(2 \times 2\). Ưu và nhược điểm của mỗi cách là gì?
Trong trường hợp nào Tỷ số chênh (OR) có thể xấp xỉ Tỷ số nguy cơ (RR)? Tại sao OR lại quan trọng trong mô hình hồi quy logistic?
Nêu các điều kiện để kiểm định Chi-bình phương Pearson cho kết quả xấp xỉ tốt. Nếu các điều kiện này không được thỏa mãn, bạn sẽ sử dụng kiểm định nào thay thế cho bảng \(2 \times 2\)?
Sự khác biệt giữa thống kê Chi-bình phương Pearson (\(X^2\)) và thống kê tỷ số hợp lý (\(G^2\)) là gì?
Cramer’s V và Goodman & Kruskal’s Gamma dùng để đo lường mối liên hệ cho loại biến nào? Giá trị của chúng nằm trong khoảng nào và diễn giải như thế nào?
Nghịch lý Simpson là gì? Cho một ví dụ (có thể tự nghĩ ra) trong lĩnh vực kinh doanh hoặc tài chính để minh họa.
Mục đích của kiểm định Cochran-Mantel-Haenszel (CMH) là gì? Kiểm định Breslow-Day được sử dụng kết hợp với CMH để kiểm tra giả định nào?
Nếu kết quả kiểm định Breslow-Day cho p-value < 0.05, bạn sẽ diễn giải kết quả phân tích bảng \(2 \times 2 \times K\) như thế nào? Việc báo cáo một Tỷ số chênh chung (common OR) có còn phù hợp không?
Tại sao việc phân tích phân tầng lại quan trọng trong nghiên cứu mối liên hệ giữa các biến?
3.10.2 Bài tập thực hành với R
(Sử dụng bộ dữ liệu có sẵn trong R hoặc tự tạo dữ liệu nếu cần)
Tạo và mô tả bảng: Sử dụng bộ dữ liệu HairEyeColor.
Tạo bảng hai chiều gộp giữa Hair (Màu tóc) và Sex (Giới tính).
Tính toán các tỷ lệ theo dòng, theo cột và tỷ lệ chung cho bảng này.
Diễn giải tỷ lệ nữ giới có tóc màu Nâu (Brown). Diễn giải tỷ lệ người tóc Vàng (Blond) là nam giới.
Phân tích bảng \(2 \times 2\): Xem xét bộ dữ liệu UCBAdmissions. Chỉ tập trung vào Khoa A (Dept == "A").
Tạo bảng \(2 \times 2\) giữa Admit (Trúng tuyển) và Gender (Giới tính) cho Khoa A.
Tính hiệu số tỷ lệ trúng tuyển, RR và OR của Nam so với Nữ. Xây dựng KTC 95% cho các thước đo này.
Thực hiện kiểm định Chi-bình phương (với và không có hiệu chỉnh Yates) và kiểm định chính xác Fisher cho bảng này. Kết luận gì về mối liên hệ giữa giới tính và trúng tuyển tại Khoa A?
Kiểm định tính độc lập và thước đo liên hợp cho bảng \(I \times J\): Sử dụng bộ dữ liệu MASS::survey (cần library(MASS)).
Tạo bảng chéo giữa Smoke (Thói quen hút thuốc) và Exer (Mức độ tập thể dục). (Lưu ý: Loại bỏ các giá trị NA nếu có trước khi tạo bảng).
Kiểm định giả thuyết về tính độc lập giữa hai biến này.
Tính Cramer’s V.
Vì cả hai biến đều có thể coi là có thứ tự, hãy tính Gamma và Kendall’s tau-b. Diễn giải kết quả.
Phân tích bảng ba chiều và CMH Test: Sử dụng lại bộ dữ liệu MASS::survey.
Tạo một bảng 3 chiều Smoke x Exer x Sex (Giới tính).
Sử dụng mantelhaen.test() để kiểm tra mối liên hệ giữa Smoke và Exer có điều kiện theo Sex. (Lưu ý: mantelhaen.test có thể cần các biến là factor nhị phân hoặc thứ bậc có scores. Bạn có thể cần thu gọn các phạm trù của Smoke và Exer thành 2 mức, ví dụ Hút (Heavy, Regul, Occas) vs. Không hút (Never), và Tập thể dục (Freq, Some) vs. Không (None)).
Hoặc, bạn có thể tính OR của việc “Hút nhiều” (ví dụ Heavy/Regul) so với “Không hút/Hút ít” (Occas/Never) đối với việc “Tập thể dục thường xuyên” (Freq) so với “Ít/Không tập” (Some/None) cho Nam và Nữ riêng biệt. Sau đó so sánh hai OR này.
Nghịch lý Simpson: Tìm một bộ dữ liệu trực tuyến (ví dụ từ Kaggle hoặc UCI) mà bạn nghi ngờ có thể chứa nghịch lý Simpson, hoặc tự tạo một bộ dữ liệu nhỏ minh họa.
Phân tích mối liên hệ giữa hai biến chính khi gộp dữ liệu.
Phân tích mối liên hệ giữa hai biến chính đó trong từng tầng của biến thứ ba.
So sánh kết quả và giải thích nếu có nghịch lý.
Trực quan hóa bảng ngẫu nhiên: Sử dụng bộ dữ liệu Titanic (có sẵn trong R, là một table).
Chuyển đổi Titanic thành một data frame (ví dụ, dùng as.data.frame.table()).
Vẽ biểu đồ thanh nhóm (grouped bar plot) thể hiện số người sống sót (Survived) theo Class (Hạng vé), phân biệt theo Sex (Giới tính).
Vẽ biểu đồ mosaic cho mối liên hệ giữa Class và Survived, phân tầng theo Sex. Diễn giải.
CrossTable() với dữ liệu tùy chỉnh: Tạo một data frame với 3 biến định tính: Region (Bắc, Trung, Nam), ProductType (A, B, C), CustomerSatisfaction (Low, Medium, High). Giả lập khoảng 200 quan sát.
Sử dụng CrossTable() từ gói gmodels để phân tích mối liên hệ giữa Region và CustomerSatisfaction. Yêu cầu hiển thị tỷ lệ dòng, cột, tổng, tần số kỳ vọng và kiểm định Chi-bình phương.
Thực hiện tương tự cho ProductType và CustomerSatisfaction.
Thước đo liên hợp thứ bậc với dữ liệu khảo sát: Giả sử bạn có dữ liệu từ một khảo sát về “Mức độ quan trọng của giá” (1=Không quan trọng đến 5=Rất quan trọng) và “Tần suất mua hàng online” (Hàng ngày, Vài lần/tuần, Vài lần/tháng, Hiếm khi).
Tạo dữ liệu giả lập cho hai biến này (100 quan sát), đảm bảo chúng là factor có thứ tự.
Tạo bảng chéo.
Tính Gamma, Kendall’s tau-b và Somers’ D (coi Tần suất mua hàng là biến phụ thuộc). Diễn giải kết quả.
Sử dụng dữ liệu arthritis từ gói vcd: Dữ liệu này từ một thử nghiệm lâm sàng về điều trị viêm khớp dạng thấp. R library(vcd) data(Arthritis) # str(Arthritis) # ?Arthritis Các biến quan tâm: Treatment (Placebo, Treated), Sex (Female, Male), Improved (None, Some, Marked).
Tạo bảng giữa Treatment và Improved. Kiểm định tính độc lập và tính OR cho “Marked Improvement” ở nhóm Treated so với Placebo (bạn có thể cần gộp “None” và “Some” thành “Not Marked”).
Phân tích mối liên hệ giữa Treatment và Improved có điều kiện theo Sex. Sử dụng mantelhaen.test() (có thể cần gộp Improved thành nhị phân) và BreslowDayTest() nếu phù hợp.
Phân tích bảng nhiều hơn 3 chiều (dùng ftable): Tạo dữ liệu giả lập với 4 biến định tính: Education (Cấp 1, Cấp 2, Cấp 3, Đại học), Income_Group (Thấp, Trung bình, Cao), Has_Internet (Có, Không), City_Type (Đô thị, Nông thôn).
Sử dụng xtabs() để tạo bảng 4 chiều.
Sử dụng ftable() để trình bày bảng này theo nhiều cách khác nhau (ví dụ: ftable(Income_Group ~ Education + Has_Internet + City_Type, data=...)).
Thực hiện một kiểm định Chi-bình phương cho bảng 2 chiều gộp giữa Education và Income_Group (bỏ qua hai biến kia).
3.11 Tài liệu tham khảo
Agresti, A. (2002). Categorical Data Analysis (2nd ed.). Wiley.
Agresti, A. (2013). Categorical Data Analysis (3rd ed.). Wiley.
Agresti, A. (2018). An Introduction to Categorical Data Analysis (3rd ed.). Wiley.
Everitt, B. S. (1992). The Analysis of Contingency Tables (2nd ed.). Chapman & Hall.
Friendly, M., & Meyer, D. (2016). Discrete Data Analysis with R: Visualization and Modeling Techniques for Categorical and Count Data. Chapman and Hall/CRC.
Powers, D. A., & Xie, Y. (2008). Statistical Methods for Categorical Data Analysis (2nd ed.). Emerald Group Publishing.
Siegel, S., & Castellan Jr., N. J. (1988). Nonparametric Statistics for the Behavioral Sciences (2nd ed.). McGraw-Hill.
Các tài liệu hướng dẫn của gói R: vcd, DescTools, epitools, gmodels.
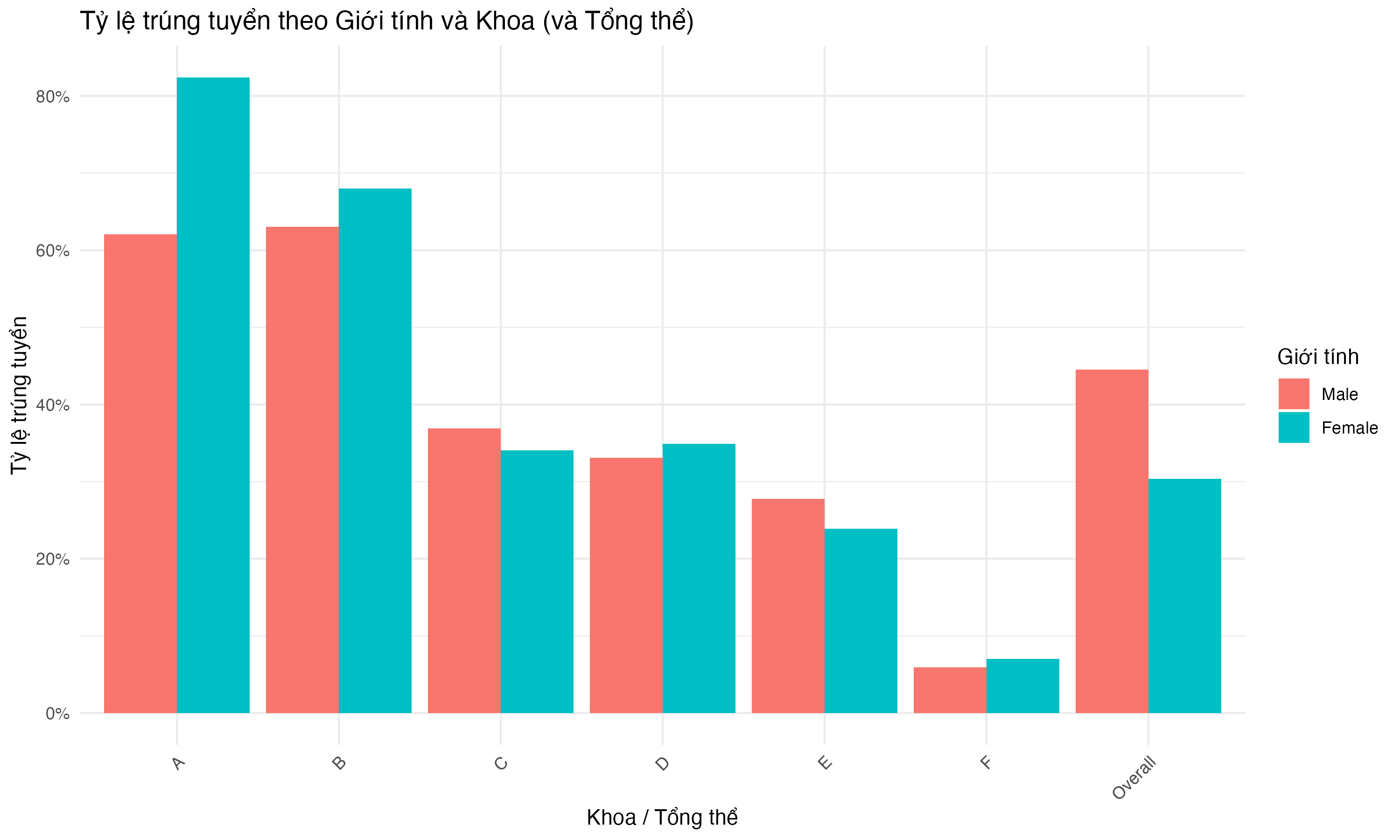 (Hình 2.2) cho thấy rõ nghịch lý. Cột “Overall” (Tổng thể) cho thấy Nam có tỷ lệ trúng tuyển cao hơn. Tuy nhiên, khi nhìn vào từng Khoa (A-F), trong nhiều khoa (A, B, D, F), tỷ lệ trúng tuyển của Nữ gần bằng hoặc cao hơn Nam. Sự khác biệt lớn ở Khoa C và E, nơi Nam có tỷ lệ cao hơn, nhưng các khoa này lại có tỷ lệ nộp đơn của Nữ thấp. Điều này minh họa tầm quan trọng của việc phân tích phân tầng.
(Hình 2.2) cho thấy rõ nghịch lý. Cột “Overall” (Tổng thể) cho thấy Nam có tỷ lệ trúng tuyển cao hơn. Tuy nhiên, khi nhìn vào từng Khoa (A-F), trong nhiều khoa (A, B, D, F), tỷ lệ trúng tuyển của Nữ gần bằng hoặc cao hơn Nam. Sự khác biệt lớn ở Khoa C và E, nơi Nam có tỷ lệ cao hơn, nhưng các khoa này lại có tỷ lệ nộp đơn của Nữ thấp. Điều này minh họa tầm quan trọng của việc phân tích phân tầng.