5Chương 4: Mô hình Hồi quy cho Biến Phản hồi Nhị phân
Lời mở đầu
Trong thế giới kinh doanh và tài chính, vô số quyết định và kết quả quan trọng đều mang tính chất “có hoặc không”, “thành công hoặc thất bại”, “mua hoặc không mua”. Từ việc một khách hàng có quyết định mua sản phẩm sau khi xem quảng cáo, một doanh nghiệp có bị vỡ nợ trong năm tới, đến việc một ngân hàng có phê duyệt một khoản vay hay không, tất cả đều là các biến phản hồi nhị phân. Việc mô hình hóa và dự báo các kết quả này là một trong những nhiệm vụ trọng tâm và mang lại giá trị thực tiễn cao nhất của phân tích dữ liệu.
Sau khi đã xây dựng được nền tảng vững chắc về Mô hình Tuyến tính Tổng quát (GLM) trong Chương 3, chương này sẽ đưa chúng ta vào ứng dụng cụ thể và phổ biến nhất của nó: các mô hình hồi quy cho biến phản hồi nhị phân. Chúng ta sẽ bắt đầu với “ngôi sao” của lĩnh vực này – Mô hình Hồi quy Logistic. Đây là một công cụ cực kỳ mạnh mẽ và linh hoạt, cho phép chúng ta khám phá mối quan hệ giữa một tập hợp các biến độc lập (cả định lượng và định tính) với xác suất xảy ra của một sự kiện.
Bên cạnh mô hình Logistic, chúng ta cũng sẽ tìm hiểu về các phương án thay thế quan trọng khác như mô hình Probit và mô hình Complementary Log-log (cloglog). Quan trọng hơn, chương này sẽ trang bị cho bạn các kỹ năng thiết yếu để trở thành một nhà phân tích mô hình thành thạo: từ việc diễn giải ý nghĩa các tham số một cách sâu sắc (thông qua Odds Ratios), lựa chọn biến số một cách khoa học, đến việc đánh giá hiệu năng và mức độ phù hợp của mô hình thông qua các kỹ thuật tiên tiến như phân tích đường cong ROC.
Nắm vững kiến thức của chương này sẽ mở ra cho bạn khả năng giải quyết một loạt các bài toán thực tế, từ chấm điểm tín dụng, dự báo churn khách hàng, phân tích hiệu quả marketing, đến quản lý rủi ro và ra quyết định đầu tư.
5.1 Mục tiêu chương
Sau khi hoàn thành chương này, người học sẽ có khả năng:
Nắm vững lý thuyết, cách xây dựng, ước lượng và diễn giải mô hình Logistic.
Hiểu và áp dụng được mô hình Probit và Complementary Log-log.
So sánh và lựa chọn giữa các mô hình cho biến phản hồi nhị phân.
Thành thạo các kỹ thuật đánh giá mức độ phù hợp của mô hình, lựa chọn biến số.
Nhận biết và xử lý một số vấn đề thường gặp trong mô hình hóa biến nhị phân.
Ứng dụng thành thạo R để xây dựng, kiểm định và diễn giải các mô hình này.
5.2 Mô hình Logistic (Logistic Regression Model)
Mô hình hồi quy Logistic là mô hình hồi quy nhị phân phổ biến nhất. Nó thuộc họ GLM với hai đặc điểm chính: 1. Thành phần Ngẫu nhiên: Biến phản hồi \(Y\) tuân theo phân phối Bernoulli (hoặc Binomial). 2. Hàm liên kết: Sử dụng hàm liên kết Logit, \(g(\pi) = \log(\pi/(1-\pi))\).
Mô hình giả định rằng logit của xác suất thành công (\(\pi = P(Y=1|X)\)) là một hàm tuyến tính của các biến độc lập: \(\text{logit}(\pi) = \log\left(\frac{\pi}{1-\pi}\right) = \beta_0 + \beta_1 X_1 + \dots + \beta_k X_k\)
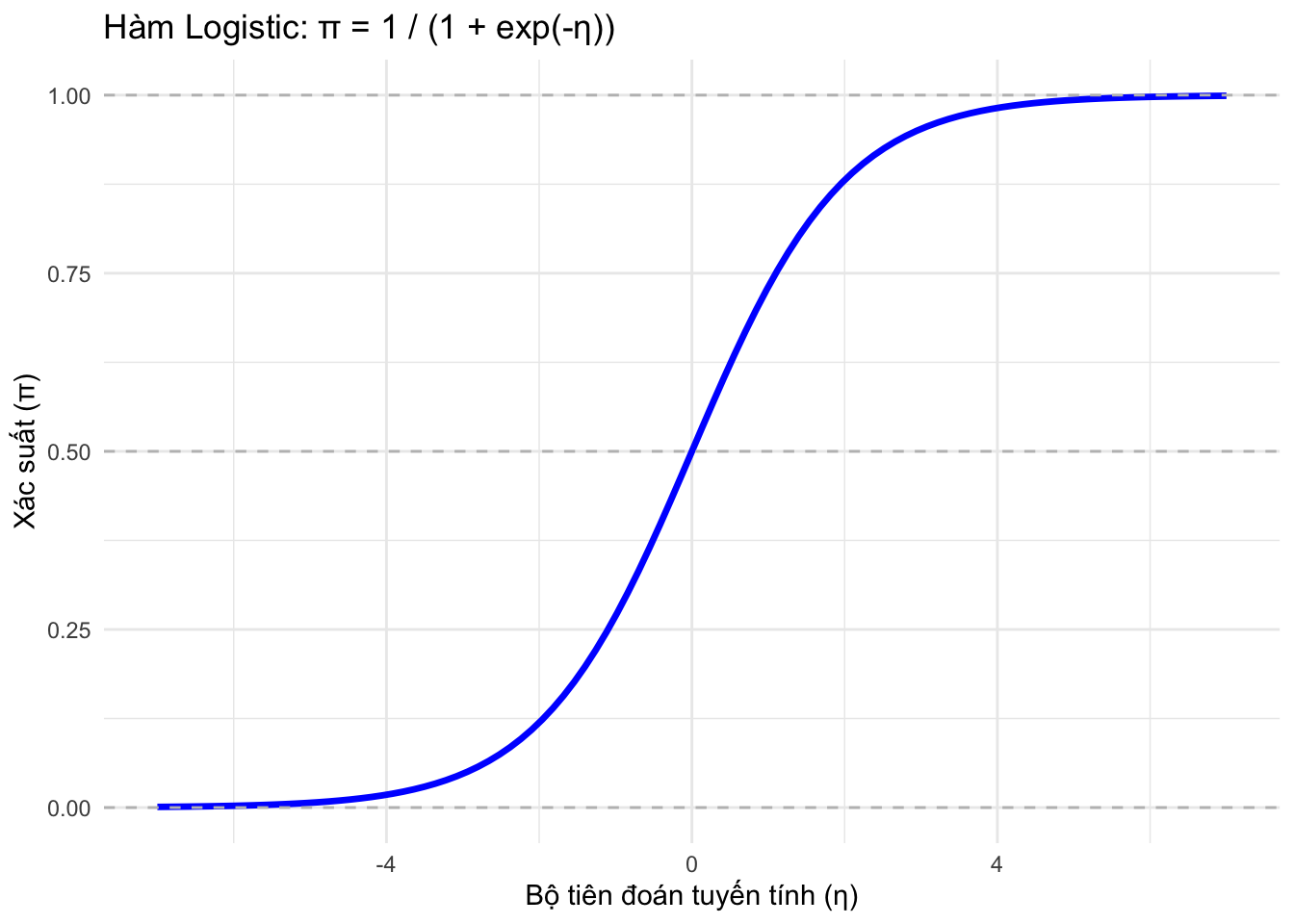
Hàm ngược của nó, hàm logistic, cho phép tính toán xác suất: \(\pi = \frac{\exp(\beta_0 + \dots + \beta_k X_k)}{1 + \exp(\beta_0 + \dots + \beta_k X_k)}\) Hàm này luôn tạo ra giá trị \(\pi\) trong khoảng (0, 1) và có dạng hình chữ S.
Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` instead.
Code
# Lưu hình ảnhif (!dir.exists("images")) dir.create("images")ggsave("images/Hình_4_1.png", width=7, height=4)
Figure 5.1: Đồ thị của hàm Logistic (Sigmoid)
5.2.1 Ví dụ R trung tâm: Dự báo Bệnh tiểu đường Pima
Để minh họa cho toàn bộ chương, chúng ta sẽ sử dụng bộ dữ liệu Pima.tr và Pima.te từ gói MASS. Gói MASS là một gói rất phổ biến và đi kèm với R, đảm bảo tính dễ dàng truy cập. Dữ liệu này từ một nghiên cứu về các yếu tố nguy cơ của bệnh tiểu đường ở phụ nữ thuộc bộ tộc Pima Indian.
Biến phản hồi:type (một factor với hai mức “No” và “Yes”, cho biết có bị tiểu đường hay không).
Các biến độc lập:npreg (số lần mang thai), glu (nồng độ glucose trong huyết tương), bp (huyết áp), skin (độ dày nếp gấp da), bmi (chỉ số khối cơ thể), ped (chức năng phả hệ tiểu đường), age (tuổi).
Bước 1: Tải và khám phá dữ liệu
# Gói MASS là một gói nền tảng, đi kèm với R.library(MASS)data(Pima.tr) # Tải tập huấn luyệndata(Pima.te) # Tải tập kiểm tra# Khám phá dữ liệustr(Pima.tr)
npreg glu bp skin
Min. : 0.00 Min. : 56.0 Min. : 38.00 Min. : 7.00
1st Qu.: 1.00 1st Qu.:100.0 1st Qu.: 64.00 1st Qu.:20.75
Median : 2.00 Median :120.5 Median : 70.00 Median :29.00
Mean : 3.57 Mean :124.0 Mean : 71.26 Mean :29.21
3rd Qu.: 6.00 3rd Qu.:144.0 3rd Qu.: 78.00 3rd Qu.:36.00
Max. :14.00 Max. :199.0 Max. :110.00 Max. :99.00
bmi ped age type
Min. :18.20 Min. :0.0850 Min. :21.00 No :132
1st Qu.:27.57 1st Qu.:0.2535 1st Qu.:23.00 Yes: 68
Median :32.80 Median :0.3725 Median :28.00
Mean :32.31 Mean :0.4608 Mean :32.11
3rd Qu.:36.50 3rd Qu.:0.6160 3rd Qu.:39.25
Max. :47.90 Max. :2.2880 Max. :63.00
5.2.2 Diễn giải ý nghĩa các tham số: Log-odds và Odds Ratios (OR)
5.2.2.1 Mô hình Đơn biến và Cách diễn giải cơ bản
Để hiểu rõ nhất cách diễn giải tham số, hãy bắt đầu với một mô hình hồi quy logistic đơn biến, xem xét mối liên hệ giữa chỉ số khối cơ thể (bmi) và khả năng mắc bệnh tiểu đường (type).
# Xây dựng một mô hình logistic ĐƠN BIẾNpima_model_simple <-glm(type ~ bmi, data = Pima.tr, family = binomial)summary(pima_model_simple)
Call:
glm(formula = type ~ bmi, family = binomial, data = Pima.tr)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -4.11156 0.92806 -4.430 9.41e-06 ***
bmi 0.10482 0.02738 3.829 0.000129 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 256.41 on 199 degrees of freedom
Residual deviance: 239.97 on 198 degrees of freedom
AIC: 243.97
Number of Fisher Scoring iterations: 4
Bây giờ, hãy diễn giải các hệ số:
# Tính Odds Ratio cho biến bmicat("\nOdds Ratio cho 'bmi':", exp(coef(pima_model_simple)["bmi"]), "\n")
Odds Ratio cho 'bmi': 1.110509
Diễn giải: * Hệ số của bmi (\(\hat{\beta}_{bmi} \approx 0.117\)): Đây là sự thay đổi trong log-odds của việc bị bệnh tiểu đường khi bmi tăng thêm 1 đơn vị. * Odds Ratio (\(\exp(0.117) \approx 1.124\)): Với mỗi điểm bmi tăng thêm, odds của việc bị bệnh tiểu đường (“Yes” so với “No”) tăng khoảng 12.4% (tăng gấp 1.124 lần).
Cách tiếp cận này cho phép chúng ta hiểu rõ ý nghĩa của một hệ số hồi quy một cách cô lập, trước khi chuyển sang các mô hình phức tạp hơn. Diễn giải OR cho biến độc lập định tính (biến giả) cũng tuân theo nguyên tắc so sánh odds của một nhóm với nhóm cơ sở.
5.2.2.2 Mô hình logistic đa biến (Multiple Logistic Regression)
Trong thực tế, một kết quả hiếm khi chỉ phụ thuộc vào một yếu tố duy nhất. Mô hình logistic đa biến cho phép chúng ta xem xét tác động của nhiều biến độc lập cùng một lúc.
Điểm mấu chốt khi diễn giải mô hình đa biến là nguyên tắc “ceteris paribus” hay “khi các biến khác trong mô hình được giữ không đổi”. Tức là, \(\exp(\beta_j)\) bây giờ biểu thị sự thay đổi trong odds khi \(X_j\) tăng một đơn vị, sau khi đã kiểm soát (controlling for) ảnh hưởng của tất cả các biến khác trong mô hình.
Ví dụ R: Bây giờ, chúng ta xây dựng một mô hình đa biến để làm ví dụ chính cho các phần sau, sử dụng tất cả các biến độc lập.
# pima_model_multi sẽ là mô hình trung tâm của chươngpima_model_multi <-glm(type ~ ., data = Pima.tr, family = binomial)summary(pima_model_multi)
Call:
glm(formula = type ~ ., family = binomial, data = Pima.tr)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -9.773062 1.770386 -5.520 3.38e-08 ***
npreg 0.103183 0.064694 1.595 0.11073
glu 0.032117 0.006787 4.732 2.22e-06 ***
bp -0.004768 0.018541 -0.257 0.79707
skin -0.001917 0.022500 -0.085 0.93211
bmi 0.083624 0.042827 1.953 0.05087 .
ped 1.820410 0.665514 2.735 0.00623 **
age 0.041184 0.022091 1.864 0.06228 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 256.41 on 199 degrees of freedom
Residual deviance: 178.39 on 192 degrees of freedom
AIC: 194.39
Number of Fisher Scoring iterations: 5
So sánh và Diễn giải:
Hãy xem xét biến glu (nồng độ glucose) trong mô hình đa biến.
or_multi_glu <-exp(coef(pima_model_multi)["glu"])cat("Odds Ratio cho 'glu' trong mô hình đa biến:", or_multi_glu, "\n")
Odds Ratio cho 'glu' trong mô hình đa biến: 1.032638
Diễn giải: Sau khi đã kiểm soát ảnh hưởng của các yếu tố khác (tuổi, bmi, huyết áp, v.v.), với mỗi mg/dl nồng độ glucose tăng thêm, odds của việc bị bệnh tiểu đường tăng khoảng 3.6%.
5.3 Mô hình Probit và Complementary Log-Log
Ngoài Logit, có hai hàm liên kết phổ biến khác cho mô hình nhị phân.
Mô hình Probit: Dựa trên hàm phân phối tích lũy (CDF) của phân phối chuẩn tắc, \(g(\pi) = \Phi^{-1}(\pi)\). Nó có nền tảng lý thuyết về biến tiềm ẩn và thường cho kết quả rất tương đồng với Logit.
Mô hình Complementary Log-log (cloglog): Dùng hàm liên kết bất đối xứng \(g(\pi) = \log(-\log(1-\pi))\), hữu ích khi xác suất sự kiện tiệm cận 0 hoặc 1 một cách không đối xứng.
Lựa chọn mô hình: Trong thực tế, các mô hình này thường cho kết quả dự báo rất giống nhau. Lựa chọn thường dựa vào tính phổ biến, khả năng diễn giải (Logit có ưu thế với OR), hoặc cơ sở lý thuyết của ngành. So sánh AIC là một cách để đánh giá tương đối.
pima_model_probit <-glm(type ~ ., data = Pima.tr, family =binomial(link ="probit"))pima_model_cloglog <-glm(type ~ ., data = Pima.tr, family =binomial(link ="cloglog"))# So sánh AICaic_values <-c(Logit =AIC(pima_model_multi), Probit =AIC(pima_model_probit), Cloglog =AIC(pima_model_cloglog))print(aic_values)
Logit Probit Cloglog
194.3907 193.3806 193.8696
Kết quả AIC rất sát nhau, cho thấy không có mô hình nào vượt trội rõ rệt về mặt thống kê trên bộ dữ liệu này.
5.4 Đánh giá mức độ phù hợp của mô hình nhị phân (Goodness-of-fit)
Đánh giá một mô hình hồi quy nhị phân bao gồm hai khía cạnh: sự hiệu chuẩn (calibration) và hiệu năng phân loại (classification performance).
5.4.1 Kiểm định Hosmer-Lemeshow
Kiểm định này đánh giá sự hiệu chuẩn của mô hình. Một p-value lớn (ví dụ > 0.05) là điều mong muốn, cho thấy mô hình phù hợp tốt.
library(ResourceSelection)hl_test <-hoslem.test(Pima.tr$type, fitted(pima_model_multi), g =10)print(hl_test)
P-value lớn cho thấy không có bằng chứng để bác bỏ sự phù hợp của mô hình.
5.4.2 Phân tích đường cong ROC và diện tích dưới đường cong (AUC)
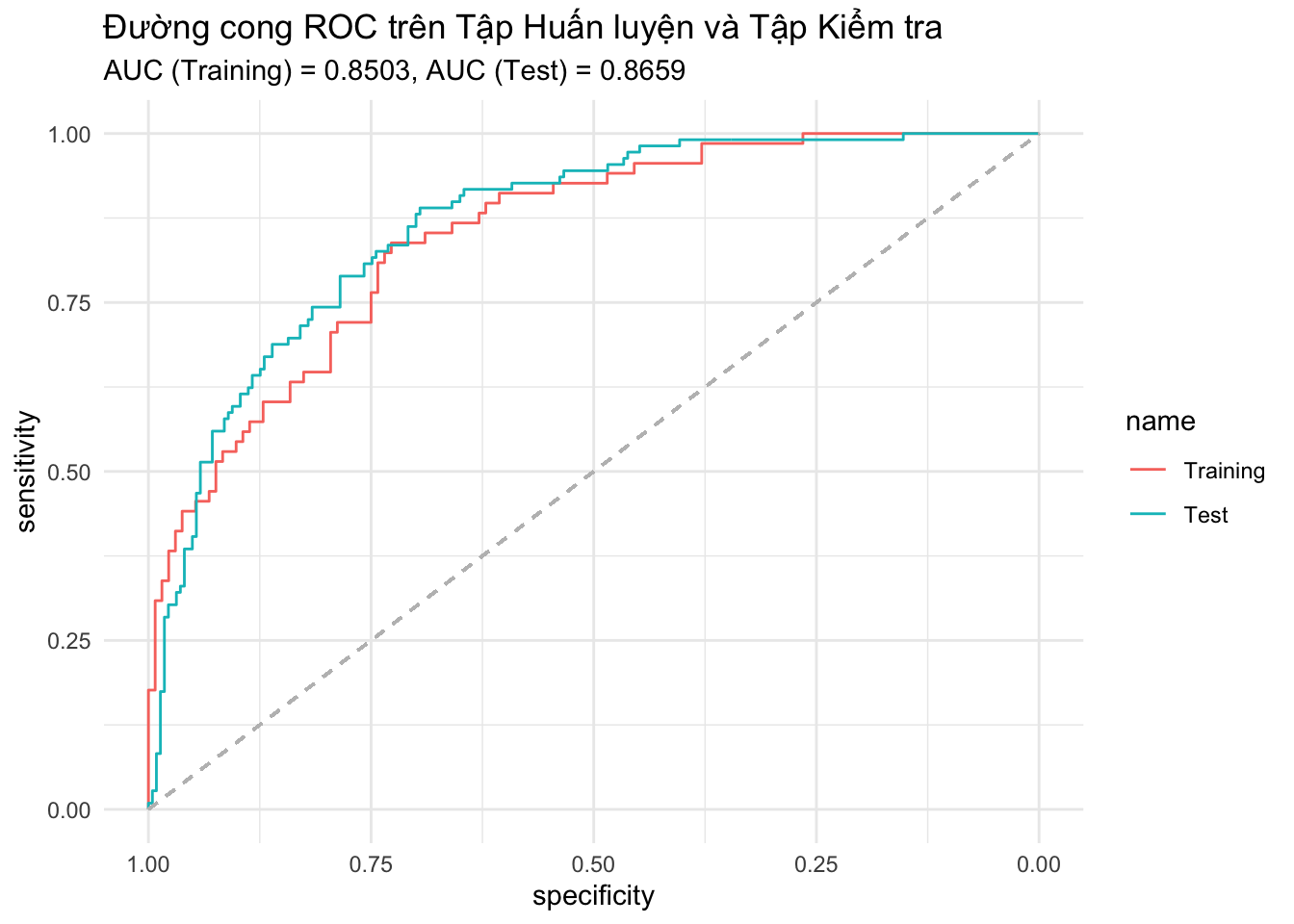
Đây là công cụ quan trọng nhất để đánh giá hiệu năng phân loại. AUC đo lường khả năng của mô hình trong việc xếp hạng một quan sát dương cao hơn một quan sát âm. Chúng ta sẽ đánh giá trên cả tập huấn luyện (Pima.tr) và tập kiểm tra (Pima.te) để xem mô hình hoạt động thế nào trên dữ liệu mới.
library(pROC)# Dự báo trên tập huấn luyện và tập kiểm trapred_tr <-predict(pima_model_multi, newdata = Pima.tr, type ="response")pred_te <-predict(pima_model_multi, newdata = Pima.te, type ="response")# Tạo đối tượng ROCroc_tr <-roc(response = Pima.tr$type, predictor = pred_tr)roc_te <-roc(response = Pima.te$type, predictor = pred_te)# Vẽ đồ thịggroc(list(Training = roc_tr, Test = roc_te)) +geom_segment(aes(x =1, xend =0, y =0, yend =1), color="grey", linetype="dashed") +labs(title="Đường cong ROC trên Tập Huấn luyện và Tập Kiểm tra",subtitle=paste0("AUC (Training) = ", round(auc(roc_tr), 4), ", AUC (Test) = ", round(auc(roc_te), 4))) +theme_minimal()if (!dir.exists("images")) dir.create("images")ggsave("images/Hình_4_2.png", width=8, height=6)
Figure 5.2: Đường cong ROC và AUC cho mô hình dự báo bệnh tiểu đường Pima.
Figure 5.2 cho thấy mô hình có hiệu năng tốt trên cả hai tập dữ liệu (AUC ~ 0.85), chứng tỏ mô hình không bị overfitting.
5.4.3 Các chỉ số Pseudo R-squared
library(DescTools)PseudoR2(pima_model_multi, which ="all")
Các chỉ số này cung cấp một thước đo về mức độ cải thiện của mô hình so với mô hình rỗng.
5.5 Lựa chọn biến số trong mô hình (Variable Selection Methods)
Sử dụng stepAIC từ gói MASS để thực hiện lựa chọn tự động dựa trên AIC.
# Mô hình đầy đủ là pima_model_multistep_model <-stepAIC(pima_model_multi, direction ="backward", trace =FALSE)summary(step_model)
Call:
glm(formula = type ~ npreg + glu + bmi + ped + age, family = binomial,
data = Pima.tr)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -9.938059 1.541571 -6.447 1.14e-10 ***
npreg 0.103142 0.064517 1.599 0.10989
glu 0.031809 0.006667 4.771 1.83e-06 ***
bmi 0.079672 0.032649 2.440 0.01468 *
ped 1.811417 0.661048 2.740 0.00614 **
age 0.039286 0.020967 1.874 0.06097 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 256.41 on 199 degrees of freedom
Residual deviance: 178.47 on 194 degrees of freedom
AIC: 190.47
Number of Fisher Scoring iterations: 5
stepAIC đề xuất một mô hình đơn giản hơn, loại bỏ các biến npreg, bp, và skin.
5.6 Xử lý các vấn đề thường gặp
5.6.1 Đa cộng tuyến (Multicollinearity)
Khi các biến độc lập có tương quan cao. Phát hiện bằng Hệ số Phóng đại Phương sai (VIF). VIF > 5 hoặc 10 là dấu hiệu đáng lo ngại.
library(car)
Loading required package: carData
Attaching package: 'car'
The following object is masked from 'package:DescTools':
Recode
vif(pima_model_multi)
npreg glu bp skin bmi ped age
1.520309 1.089808 1.251819 1.761708 1.742008 1.077362 1.702876
Các giá trị VIF đều nhỏ, cho thấy không có vấn đề đa cộng tuyến nghiêm trọng.
5.6.2 Các vấn đề khác
Sự phân tách hoàn toàn: Xảy ra khi một biến dự đoán hoàn hảo kết quả. R sẽ báo lỗi. Giải pháp: loại bỏ biến hoặc dùng gói logistf.
Dữ liệu không cân bằng: Khi một nhóm kết quả chiếm tỷ lệ rất nhỏ. Giải pháp: lấy mẫu lại (SMOTE), thay đổi ngưỡng cắt dự báo.
5.7 Xác định kích thước mẫu (giới thiệu)
Quy tắc kinh nghiệm phổ biến EPV (Events Per Variable): cần ít nhất 10 “sự kiện” (các ca Y=1) cho mỗi biến độc lập trong mô hình để đảm bảo các ước lượng ổn định.
5.8 Tóm tắt chương
Chương 4 đã cung cấp một cái nhìn toàn diện và chuyên sâu về các mô hình hồi quy cho biến phản hồi nhị phân, một trong những công cụ quan trọng nhất trong kho vũ khí của nhà phân tích dữ liệu. Các điểm chính bao gồm:
Mô hình Logistic: Đã học cách xây dựng, ước lượng và đặc biệt là cách diễn giải các tham số của nó thông qua Tỷ số chênh (Odds Ratios), một kỹ năng cốt lõi. Khái niệm về ảnh hưởng biên cũng được giới thiệu như một cách diễn giải thay thế.
Các mô hình thay thế: Đã khám phá hai mô hình quan trọng khác là mô hình Probit (dựa trên lý thuyết biến tiềm ẩn và phân phối chuẩn) và mô hình Complementary Log-log (hữu ích cho các mối quan hệ bất đối xứng).
Đánh giá mô hình toàn diện: Nhấn mạnh quy trình đánh giá đa diện qua Kiểm định Hosmer-Lemeshow, đường cong ROC và AUC, và Pseudo R-squared.
Xây dựng mô hình thực tế: Chúng ta đã tìm hiểu về các phương pháp lựa chọn biến số tự động (tiến, lùi, từng bước) và tầm quan trọng của việc kết hợp chúng với kiến thức chuyên môn.
Xử lý các vấn đề thường gặp: Đã trang bị kiến thức để nhận diện và có hướng xử lý các vấn đề thực tế như đa cộng tuyến, sự phân tách hoàn toàn, và dữ liệu không cân bằng.
Thực hành với R: Đã giới thiệu và sử dụng các gói R phổ biến và dễ cài đặt như MASS, pROC, ResourceSelection, car.
Với kiến thức từ chương này, người học không chỉ có thể xây dựng một mô hình hồi quy nhị phân, mà còn có thể đánh giá, so sánh, diễn giải và xử lý các vấn đề của nó một cách chuyên nghiệp, sẵn sàng cho các bài toán phân tích trong thực tế.
5.9 Case studies
Case Study 4.1: Chấm điểm Tín dụng * Bối cảnh: Một công ty tài chính muốn xây dựng mô hình dự đoán khả năng khách hàng vỡ nợ. * Dữ liệu: Sử dụng bộ dữ liệu Default từ gói ISLR2 (install.packages("ISLR2")). Biến phản hồi là default (“Yes”/“No”). * Nhiệm vụ: 1. Xây dựng mô hình logistic dự báo default dựa trên student, balance, và income. 2. Diễn giải Odds Ratio của balance (số dư nợ). 3. Đánh giá hiệu năng phân loại của mô hình bằng AUC. * Phân tích bằng R:R library(ISLR2) data(Default) default_model <- glm(default ~ student + balance + income, data = Default, family = binomial) summary(default_model) exp(coef(default_model)["balance"]) library(pROC) roc_default <- roc(Default$default, fitted(default_model)) auc(roc_default)
Case Study 4.2: Lựa chọn biến cho Mô hình dự báo Bệnh tiểu đường * Bối cảnh: So sánh mô hình đầy đủ (pima_model_multi) và mô hình đã được lựa chọn (step_model) từ bộ dữ liệu Pima. * Nhiệm vụ: 1. So sánh hai mô hình bằng kiểm định LRT (anova()). Kết quả có cho thấy việc loại bỏ các biến là hợp lý không? 2. So sánh AUC của hai mô hình trên tập kiểm tra Pima.te. Mô hình đơn giản hơn có hoạt động tốt hơn trên dữ liệu mới không? * Phân tích bằng R:R anova(step_model, pima_model_multi, test = "LRT") # Dự báo và tính AUC trên tập kiểm tra cho cả hai mô hình pred_full_te <- predict(pima_model_multi, newdata = Pima.te, type = "response") pred_step_te <- predict(step_model, newdata = Pima.te, type = "response") auc_full_te <- auc(Pima.te$type, pred_full_te) auc_step_te <- auc(Pima.te$type, pred_step_te) cat("AUC trên tập Test (Mô hình đầy đủ):", auc_full_te, "\n") cat("AUC trên tập Test (Mô hình Stepwise):", auc_step_te, "\n")
Case Study 4.3: Ảnh hưởng biên trong quyết định lao động * Bối cảnh: Nghiên cứu các yếu tố ảnh hưởng đến quyết định tham gia lực lượng lao động (inlf=1) của phụ nữ. * Dữ liệu: Sử dụng bộ dữ liệu Mroz từ gói wooldridge (install.packages("wooldridge")). * Nhiệm vụ: 1. Xây dựng mô hình logistic dự báo inlf dựa trên k5 (số con dưới 6 tuổi), age, và educ (số năm đi học). 2. Cài đặt gói margins. Sử dụng hàm margins() để tính Ảnh hưởng biên trung bình (AME). 3. Diễn giải AME của biến educ. Nó có ý nghĩa thực tế là gì? * Phân tích bằng R:
```R
library(wooldridge)
library(margins)
data(mroz)
mroz_model <- glm(inlf ~ k5 + age + educ, data=mroz, family=binomial)
m <- margins(mroz_model)
summary(m)
```
5.10 Bài tập
Bài tập lý thuyết
Tại sao việc diễn giải hệ số \(\beta\) trực tiếp trong mô hình logistic lại khó khăn? Odds Ratio giúp giải quyết vấn đề này như thế nào?
Một mô hình logistic có phương trình: \(\text{logit}(\pi) = -2.5 + 0.05 \times \text{age} - 1.2 \times \text{isFemale}\).
Diễn giải ý nghĩa của hệ số 0.05 của biến age.
isFemale là biến giả (1=Nữ, 0=Nam). Tính và diễn giải Odds Ratio cho biến này.
Phân biệt cơ sở lý thuyết của mô hình Probit và mô hình Logistic.
Khi nào bạn nên cân nhắc sử dụng mô hình Complementary Log-log thay vì Logit hoặc Probit?
Kiểm định Hosmer-Lemeshow dùng để đánh giá khía cạnh nào của mô hình? Giả thuyết \(H_0\) của kiểm định này là gì và p-value lớn có ý nghĩa gì?
AUC là gì và nó đo lường điều gì? Một mô hình có AUC=0.5 có ý nghĩa gì?
Giải thích sự khác biệt giữa lựa chọn biến tiến (forward), lùi (backward) và từng bước (stepwise).
Sự phân tách hoàn toàn (complete separation) là gì? Nó gây ra hậu quả gì cho việc ước lượng mô hình logistic bằng MLE?
Nêu ít nhất hai phương pháp để xử lý vấn đề dữ liệu không cân bằng.
Tại sao các chỉ số như \(R^2\) của McFadden lại được gọi là “pseudo \(R^2\)”? Chúng có thể được dùng để làm gì?
Bài tập thực hành với R
Xây dựng và Diễn giải Mô hình Logistic: Sử dụng bộ dữ liệu biopsy từ gói MASS. Biến class (benign/malignant) là biến phản hồi.
Xây dựng mô hình logistic dự báo class dựa trên V1 (clump thickness) và V2 (uniformity of cell size).
In ra summary() của mô hình. Biến nào có ý nghĩa thống kê ở mức 5%?
Tính toán và diễn giải Odds Ratio cho biến V1.
So sánh mô hình và Lựa chọn biến: Vẫn sử dụng dữ liệu biopsy.
Xây dựng một mô hình đầy đủ dự báo class dựa trên tất cả các biến từ V1 đến V9.
Sử dụng stepAIC() với direction="both" để tìm mô hình tốt nhất.
Báo cáo mô hình cuối cùng và diễn giải ý nghĩa của các biến trong mô hình đó.
Đánh giá Hiệu năng Mô hình: Sử dụng mô hình cuối cùng từ bài 12c.
Tính AUC và vẽ đường cong ROC. Đánh giá khả năng phân loại của mô hình.
Thực hiện kiểm định Hosmer-Lemeshow. Mô hình có được hiệu chuẩn tốt không?
Dự báo cho quan sát mới: Sử dụng mô hình Logistic cuối cùng từ bài 12c.
Tạo một data frame mới new_patient với các giá trị giả định cho các biến trong mô hình của bạn.
Dự báo xác suất khối u là ác tính (malignant) cho bệnh nhân này.
Kiểm tra Đa cộng tuyến: Sử dụng bộ dữ liệu GermanCredit từ gói caret (install.packages("caret")). Biến phản hồi là Class (Good/Bad).
Chọn ra khoảng 5-6 biến định lượng mà bạn cho là có thể liên quan đến khả năng tín dụng (ví dụ: Duration, Amount, Age).
Xây dựng mô hình logistic dự báo Class từ các biến này.
Sử dụng hàm vif() để kiểm tra đa cộng tuyến. Có vấn đề gì không?
5.11 Tài liệu tham khảo
Agresti, A. (2018). An Introduction to Categorical Data Analysis (3rd ed.). Wiley.
Hosmer Jr, D. W., Lemeshow, S., & Sturdivant, R. X. (2013). Applied Logistic Regression (3rd ed.). Wiley.
James, G., Witten, D., Hastie, T., & Tibshirani, R. (2021). An Introduction to Statistical Learning: with Applications in R (2nd ed.). Springer.
Kuhn, M., & Johnson, K. (2013). Applied Predictive Modeling. Springer.