4 Chương 3: Mô hình Tuyến tính Tổng quát (Generalized Linear Models - GLMs) – Nền tảng
Lời mở đầu
Trong các học phần kinh tế lượng cơ bản, chúng ta đã quen thuộc với một công cụ mạnh mẽ: Mô hình Hồi quy Tuyến tính Cổ điển (OLS - Ordinary Least Squares). OLS hoạt động hiệu quả khi biến phụ thuộc (biến phản hồi) là một biến liên tục, tuân theo phân phối chuẩn, và có mối quan hệ tuyến tính với các biến độc lập. Tuy nhiên, trong thực tế kinh doanh và tài chính, rất nhiều biến mà chúng ta muốn dự đoán lại không phải là biến liên tục. Chúng có thể là: * Một quyết định nhị phân: Khách hàng có mua sản phẩm không (Có/Không)? Khoản vay có bị vỡ nợ không (Vỡ nợ/Không vỡ nợ)? * Một lựa chọn đa phạm trù: Người tiêu dùng chọn thương hiệu nào (A, B, hay C)? Doanh nghiệp xếp hạng tín dụng ở mức nào (AAA, AA, A,…)? * Một biến đếm: Một khách hàng thực hiện bao nhiêu giao dịch trong một tháng? Một website có bao nhiêu lượt truy cập trong một giờ?
Việc áp dụng máy móc mô hình OLS cho các loại biến này sẽ dẫn đến những kết luận sai lệch và dự báo không đáng tin cậy. Chính từ nhu cầu mô hình hóa các loại biến phản hồi đa dạng này, Mô hình Tuyến tính Tổng quát (Generalized Linear Models - GLMs) đã ra đời. GLMs, được phát triển bởi Nelder và Wedderburn vào năm 1972, là một sự mở rộng linh hoạt và mạnh mẽ của mô hình hồi quy tuyến tính cổ điển. Nó cung cấp một khung lý thuyết thống nhất để xử lý các loại biến phản hồi khác nhau, bao gồm cả biến định tính và biến đếm.
Chương này sẽ trang bị cho các bạn những kiến thức nền tảng vững chắc về GLMs. Chúng ta sẽ cùng nhau “giải phẫu” cấu trúc của một GLM, tìm hiểu các thành phần cốt lõi của nó, và nắm vững nguyên lý ước lượng cũng như các phương pháp suy diễn thống kê. Hiểu rõ GLMs không chỉ giúp bạn sử dụng đúng các mô hình như Logistic, Probit, hay Poisson Regression trong các chương sau, mà còn mang lại một tư duy mô hình hóa linh hoạt, cho phép bạn tiếp cận nhiều vấn đề phân tích dữ liệu phức tạp trong thực tế.
Mục tiêu chương
Sau khi hoàn thành chương này, người học sẽ có khả năng:
- Hiểu rõ sự cần thiết và ưu điểm của GLM so với mô hình tuyến tính cổ điển khi phân tích biến phụ thuộc định tính.
- Nắm vững ba thành phần cốt lõi của GLM: thành phần ngẫu nhiên, thành phần hệ thống, và hàm liên kết.
- Hiểu rõ các họ phân phối xác suất và các hàm liên kết thường dùng trong GLM, đặc biệt cho biến định tính và biến đếm.
- Nắm vững nguyên lý ước lượng hợp lý tối đa (MLE) và các phương pháp suy diễn thống kê trong GLM.
- Biết cách đánh giá mức độ phù hợp của mô hình GLM và diễn giải phần dư.
- Thực hành xây dựng và diễn giải GLM cơ bản bằng R.
4.1 Tại sao cần Mô hình Tuyến tính Tổng quát? Những hạn chế của Mô hình Tuyến tính Cổ điển (OLS) đối với biến phụ thuộc định tính
Mô hình hồi quy tuyến tính cổ điển (OLS) có dạng: \(Y = \beta_0 + \beta_1 X_1 + ... + \beta_k X_k + \epsilon\) với giả định quan trọng là phần dư \(\epsilon\) tuân theo phân phối chuẩn với kỳ vọng bằng 0 và phương sai không đổi (\(\epsilon \sim N(0, \sigma^2)\)). Điều này ngụ ý rằng biến phụ thuộc \(Y\) cũng tuân theo phân phối chuẩn.
Khi biến phụ thuộc \(Y\) là một biến định tính (ví dụ, nhị phân 0/1), việc áp dụng mô hình trên, thường được gọi là Mô hình Xác suất Tuyến tính (Linear Probability Model - LPM), sẽ gặp phải nhiều vấn đề nghiêm trọng:
- Giá trị dự báo vô lý (Nonsensical Predictions): Vì \(E(Y|X) = \beta_0 + \beta_1 X_1 + ...\), mô hình LPM diễn giải giá trị dự báo \(\hat{Y}\) là xác suất \(P(Y=1|X)\). Tuy nhiên, vế phải của phương trình là một tổ hợp tuyến tính không bị giới hạn, nó có thể tạo ra các giá trị dự báo nhỏ hơn 0 hoặc lớn hơn 1, điều này là vô nghĩa đối với một xác suất.
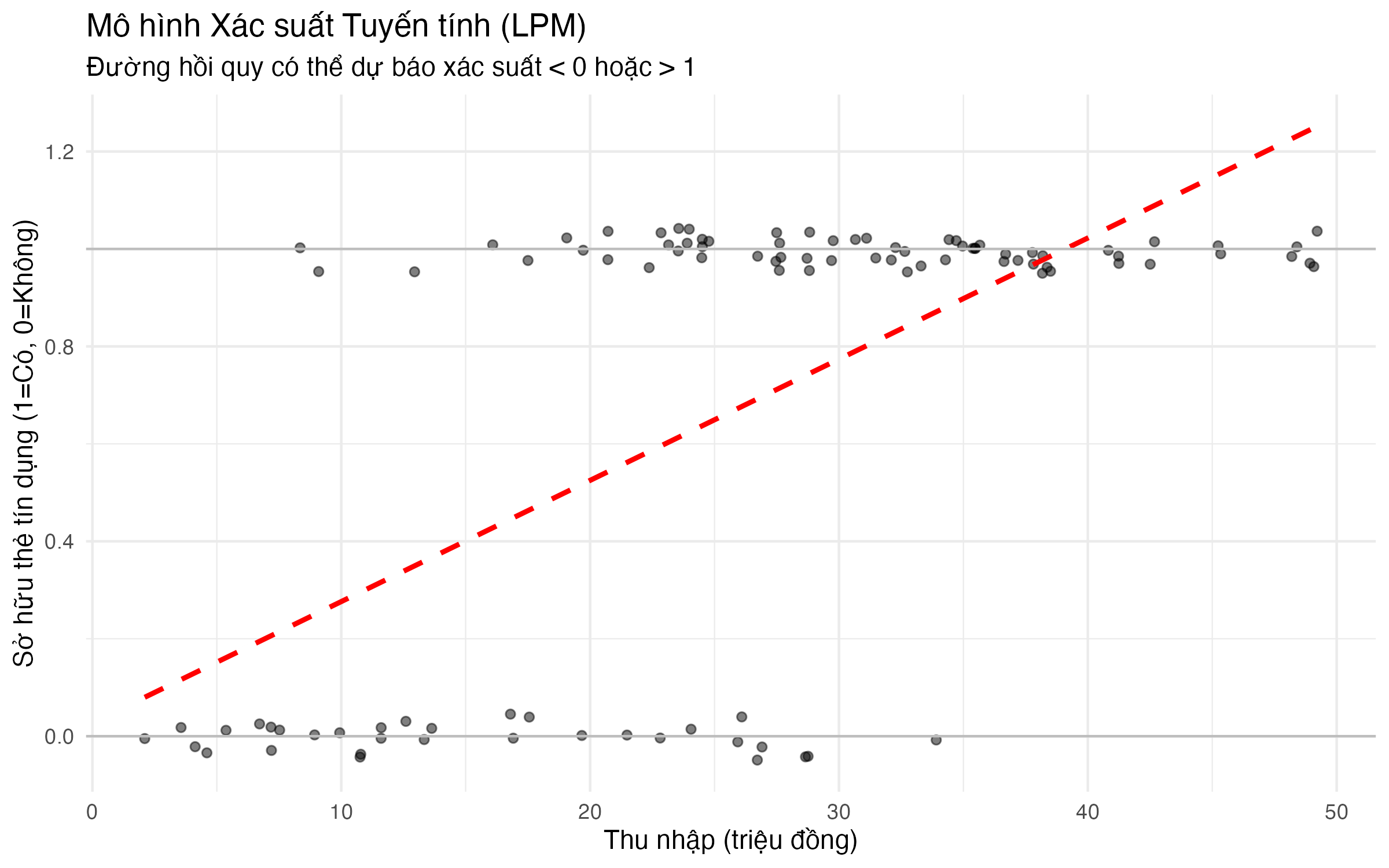
Đồ thị (Hình 3.1) cho thấy đường hồi quy LPM (đường nét đứt màu đỏ) có thể dễ dàng vượt ra ngoài khoảng [0, 1] khi giá trị của biến thu_nhap ở mức thấp hoặc cao.
Phương sai của phần dư thay đổi (Heteroscedasticity): Với biến phụ thuộc nhị phân \(Y\), phần dư \(\epsilon = Y - E(Y|X)\) chỉ có thể nhận hai giá trị: \(1-p\) (khi \(Y=1\)) và \(-p\) (khi \(Y=0\)), trong đó \(p = E(Y|X)\). Phương sai của phần dư là \(Var(\epsilon|X) = p(1-p)\). Vì \(p\) phụ thuộc vào \(X\), nên phương sai của phần dư cũng phụ thuộc vào \(X\). Đây là sự vi phạm giả định quan trọng về phương sai không đổi (homoscedasticity) của OLS, làm cho các ước lượng sai số chuẩn (standard error) bị chệch và không đáng tin cậy, dẫn đến các kiểm định giả thuyết (t-test, F-test) không còn hợp lệ.
Phần dư không tuân theo phân phối chuẩn: Rõ ràng phần dư chỉ nhận hai giá trị nên không thể tuân theo phân phối chuẩn. Với mẫu lớn, điều này có thể không quá nghiêm trọng, nhưng nó vẫn là một sự vi phạm giả định cơ bản.
Mối quan hệ phi tuyến: Trong nhiều trường hợp, mối quan hệ giữa biến độc lập và xác suất của một sự kiện thường có dạng phi tuyến, điển hình là dạng chữ S (S-shaped). Xác suất thay đổi chậm ở các giá trị rất thấp hoặc rất cao của biến độc lập, và thay đổi nhanh ở các giá trị trung bình. LPM không thể nắm bắt được mối quan hệ phi tuyến này.
Do những hạn chế trên, chúng ta cần một phương pháp tổng quát hơn. GLMs giải quyết tất cả các vấn đề này bằng cách giới thiệu một kiến trúc mô hình linh hoạt hơn.
4.2 Ba thành phần của GLM
Một Mô hình Tuyến tính Tổng quát (GLM) được định nghĩa bởi ba thành phần:
Thành phần Ngẫu nhiên (Random Component): Chỉ định phân phối xác suất cho biến phụ thuộc \(Y\), với điều kiện các biến độc lập. Phân phối này phải thuộc họ phân phối mũ (exponential family), bao gồm nhiều phân phối quen thuộc như Normal, Binomial, Poisson, Gamma, v.v. Thành phần này xác định cấu trúc phương sai của \(Y\).
Thành phần Hệ thống (Systematic Component): Là một tổ hợp tuyến tính của các biến độc lập, được gọi là bộ tiên đoán tuyến tính (linear predictor), ký hiệu là \(\eta\) (eta). \(\eta = \beta_0 + \beta_1 X_1 + ... + \beta_k X_k\) Thành phần này giống hệt như vế phải của mô hình OLS.
Hàm liên kết (Link Function): Là một hàm \(g(\cdot)\) kết nối giá trị kỳ vọng của biến phụ thuộc, \(\mu = E(Y)\), với thành phần hệ thống \(\eta\). \(g(\mu) = \eta = \beta_0 + \beta_1 X_1 + ... + \beta_k X_k\) Hàm liên kết phải là hàm đơn điệu và khả vi. Nó cho phép giá trị kỳ vọng \(\mu\) bị giới hạn trong một khoảng nhất định (ví dụ xác suất trong khoảng [0, 1]) trong khi thành phần hệ thống \(\eta\) có thể nhận bất kỳ giá trị thực nào \((-\infty, +\infty)\). Hàm ngược của hàm liên kết, \(g^{-1}(\cdot)\), cho phép chúng ta chuyển từ bộ tiên đoán tuyến tính \(\eta\) trở lại giá trị kỳ vọng \(\mu\): \(\mu = g^{-1}(\eta) = g^{-1}(\beta_0 + \beta_1 X_1 + ...)\)
Bằng cách lựa chọn các kết hợp khác nhau của Phân phối và Hàm liên kết, chúng ta có thể tạo ra nhiều loại mô hình khác nhau.
| Tên mô hình | Biến phụ thuộc (Y) | Phân phối (Random Component) | Hàm liên kết \(g(\mu)\) (Link Function) | \(\mu = E(Y)\) |
|---|---|---|---|---|
| Hồi quy tuyến tính (OLS) | Liên tục, không giới hạn | Normal (Gaussian) | Identity: \(g(\mu) = \mu\) | \(\mu = \eta\) |
| Hồi quy Logistic | Nhị phân (0/1) | Binomial | Logit: \(g(\mu) = \log(\frac{\mu}{1-\mu})\) | \(\mu = \frac{\exp(\eta)}{1+\exp(\eta)}\) |
| Hồi quy Probit | Nhị phân (0/1) | Binomial | Probit: \(g(\mu) = \Phi^{-1}(\mu)\) | \(\mu = \Phi(\eta)\) |
| Hồi quy Poisson | Dạng đếm (0, 1, 2,…) | Poisson | Log: \(g(\mu) = \log(\mu)\) | \(\mu = \exp(\eta)\) |
| Hồi quy Log-linear | Dạng đếm (tần số ô) | Poisson | Log: \(g(\mu) = \log(\mu)\) | \(\mu = \exp(\eta)\) |
| Hồi quy Gamma | Liên tục, dương, lệch phải | Gamma | Inverse: \(g(\mu) = 1/\mu\) | \(\mu = 1/\eta\) |
Sơ đồ dưới đây minh họa cấu trúc của một GLM:
?fig-glm-structure (Hình 3.2) tóm tắt luồng hoạt động của GLM. Các biến độc lập được kết hợp tuyến tính để tạo ra \(\eta\). Hàm liên kết \(g(\cdot)\) kết nối \(\eta\) với giá trị kỳ vọng \(\mu\) của biến phụ thuộc. Cuối cùng, biến phụ thuộc \(Y\) được giả định là một hiện thực hóa (realization) từ một phân phối xác suất có tham số là \(\mu\).
4.3 Các họ phân phối trong gia đình hàm mũ (Exponential Family)
Thành phần ngẫu nhiên của một GLM yêu cầu phân phối của biến phụ thuộc phải thuộc họ phân phối mũ. Một phân phối được gọi là thuộc họ này nếu hàm khối xác suất (PMF) hoặc hàm mật độ xác suất (PDF) của nó có thể được viết dưới dạng: \(f(y; \theta, \phi) = \exp\left( \frac{y\theta - b(\theta)}{a(\phi)} + c(y, \phi) \right)\)
Trong đó:
- \(\theta\): là tham số tự nhiên (natural parameter) của phân phối.
- \(\phi\): là tham số phân tán (dispersion parameter), thường liên quan đến phương sai.
- \(a(\cdot), b(\cdot), c(\cdot)\): là các hàm cụ thể xác định từng phân phối riêng lẻ.
Lý do họ phân phối mũ quan trọng là vì nó có các thuộc tính toán học rất đẹp, giúp cho việc xây dựng lý thuyết và thuật toán ước lượng cho GLM trở nên thống nhất và hiệu quả. Một số kết quả quan trọng đối với một phân phối thuộc họ này là: * Kỳ vọng: \(E(Y) = \mu = b'(\theta)\) * Phương sai: \(Var(Y) = b''(\theta) a(\phi)\)
\(Var(Y)\) có thể được viết thành \(V(\mu) \times \phi\), trong đó \(V(\mu)\) được gọi là hàm phương sai (variance function), mô tả mối quan hệ giữa phương sai và giá trị trung bình của \(Y\).
Bảng dưới đây cho thấy các thành phần này đối với một số phân phối phổ biến:
| Phân phối | \(E(Y)=\mu\) | Hàm phương sai \(V(\mu)\) | Tham số phân tán \(\phi\) |
|---|---|---|---|
| Normal | \(\mu\) | \(1\) | \(\sigma^2\) (phương sai) |
| Poisson | \(\mu\) | \(\mu\) | \(1\) (cố định) |
| Binomial | \(np\) | \(n p (1-p) = \mu(1-\mu/n)\) | \(1\) (cố định) |
| Gamma | \(\mu\) | \(\mu^2\) | \(1/\nu\) (\(\nu\) là tham số hình dạng) |
Ghi chú quan trọng: * Đối với phân phối Poisson, \(Var(Y) = E(Y) = \mu\). Nếu trong thực tế, phương sai lớn hơn kỳ vọng (\(Var(Y) > E(Y)\)), chúng ta có hiện tượng quá phân tán (overdispersion). * Đối với phân phối Binomial, phương sai phụ thuộc vào \(n\) và \(p\).
4.4 Các hàm liên kết phổ biến
Hàm liên kết \(g(\mu)\) là thành phần kết nối \(\mu\) và \(\eta\). Mỗi họ phân phối có một hàm liên kết kinh điển (canonical link), là hàm liên kết làm cho tham số tự nhiên \(\theta\) bằng với bộ tiên đoán tuyến tính \(\eta\) (\(\theta = \eta\)). Sử dụng hàm liên kết kinh điển thường giúp đơn giản hóa việc tính toán và suy diễn thống kê. Tuy nhiên, chúng ta vẫn có thể sử dụng các hàm liên kết khác nếu chúng phù hợp hơn về mặt lý thuyết.
- Hàm Identity: \(g(\mu) = \mu\).
- \(\eta = \mu\).
- Dùng cho mô hình hồi quy tuyến tính (phân phối Normal).
- Hàm liên kết kinh điển cho phân phối Normal.
- Hàm Logit: \(g(\mu) = \log\left(\frac{\mu}{1-\mu}\right)\).
- \(\eta = \text{logit}(\mu)\).
- \(\mu\) là xác suất, nên \(\mu \in (0,1)\). Hàm logit biến đổi một giá trị trong khoảng (0,1) thành một giá trị trong khoảng \((-\infty, +\infty)\).
- Hàm ngược: \(\mu = \frac{\exp(\eta)}{1+\exp(\eta)}\) (hàm logistic).
- Dùng cho mô hình hồi quy logistic (phân phối Binomial).
- Hàm liên kết kinh điển cho phân phối Binomial.
- Hàm Probit: \(g(\mu) = \Phi^{-1}(\mu)\).
- \(\Phi^{-1}(\cdot)\) là hàm ngược của hàm phân phối tích lũy (CDF) của phân phối chuẩn tắc \(N(0,1)\).
- Tương tự logit, nó biến đổi \(\mu \in (0,1)\) thành \(\eta \in (-\infty, +\infty)\).
- Dùng cho mô hình hồi quy probit (phân phối Binomial).
- Hàm Log: \(g(\mu) = \log(\mu)\).
- \(\eta = \log(\mu)\). \(\mu\) phải dương.
- Hàm ngược: \(\mu = \exp(\eta)\).
- Dùng cho mô hình hồi quy Poisson, mô hình Log-linear.
- Hàm liên kết kinh điển cho phân phối Poisson.
- Hàm Complementary log-log (cloglog): \(g(\mu) = \log(-\log(1-\mu))\).
- Hàm này cũng biến đổi \(\mu \in (0,1)\) thành \(\eta \in (-\infty, +\infty)\) nhưng nó bất đối xứng.
- Thường được sử dụng khi xác suất của một sự kiện tăng rất nhanh từ 0 và sau đó tiệm cận 1 một cách chậm chạp (hoặc ngược lại).
4.5 Phương pháp ước lượng hợp lý tối đa (Maximum Likelihood Estimation - MLE)
Không giống OLS tối thiểu hóa tổng bình phương phần dư, GLMs được ước lượng bằng phương pháp Hợp lý Tối đa (MLE).
4.5.1 Nguyên lý MLE
Ý tưởng của MLE là: Tìm các giá trị tham số (các \(\beta\)) sao cho hàm hợp lý (likelihood function) của dữ liệu quan sát được là lớn nhất. Nói cách khác, chúng ta tìm bộ tham số làm cho dữ liệu mà chúng ta đã quan sát được có “khả năng xảy ra cao nhất”.
Hàm hợp lý (Likelihood function): Giả sử chúng ta có một mẫu gồm \(N\) quan sát độc lập \((y_1, y_2, ..., y_N)\). Hàm hợp lý, ký hiệu là \(L(\beta | y)\), là tích của các hàm mật độ/khối xác suất của từng quan sát: \(L(\beta | y) = \prod_{i=1}^{N} f(y_i; \beta)\) trong đó \(f(y_i; \beta)\) là PMF/PDF của \(y_i\) với bộ tham số \(\beta\) cần ước lượng.
Hàm log-hợp lý (Log-likelihood function): Vì hàm hợp lý là một tích, việc tối đa hóa nó thường khó khăn. Thay vào đó, người ta tối đa hóa logarit của nó, gọi là hàm log-hợp lý, ký hiệu là \(\ell(\beta | y)\): \(\ell(\beta | y) = \log[L(\beta | y)] = \sum_{i=1}^{N} \log[f(y_i; \beta)]\) Vì logarit là một hàm đồng biến, việc tối đa hóa \(\ell(\beta|y)\) tương đương với việc tối đa hóa \(L(\beta|y)\), nhưng việc tính toán với tổng thường dễ hơn nhiều so với tích.
Tìm ước lượng: Các ước lượng hợp lý tối đa (MLEs) của \(\beta\), ký hiệu là \(\hat{\beta}\), là các giá trị làm tối đa hóa \(\ell(\beta|y)\). Điều này thường được thực hiện bằng cách lấy đạo hàm của \(\ell(\beta|y)\) theo từng \(\beta_j\), cho chúng bằng 0 và giải hệ phương trình. \(\frac{\partial \ell(\beta)}{\partial \beta_j} = 0\) cho \(j=0, 1, ..., k\). Trong GLMs, các phương trình này thường không có lời giải dạng đóng (closed-form solution), do đó cần sử dụng các thuật toán lặp số như Iteratively Reweighted Least Squares (IRLS) hoặc Newton-Raphson để tìm ra các ước lượng. Các phần mềm thống kê như R sẽ thực hiện việc này tự động.
4.5.2 Ưu điểm của MLE
MLE là một phương pháp ước lượng rất mạnh mẽ và có nhiều thuộc tính tốt khi kích thước mẫu lớn (thuộc tính tiệm cận): * Không chệch (Asymptotically Unbiased): Khi \(N \to \infty\), \(E(\hat{\beta}) \to \beta\). * Hiệu quả (Efficient): Trong số tất cả các ước lượng không chệch, MLE có phương sai nhỏ nhất khi \(N \to \infty\). * Tiệm cận phân phối chuẩn: Khi \(N \to \infty\), phân phối của \(\hat{\beta}\) tiến đến phân phối chuẩn: \(\hat{\beta} \sim N(\beta, I(\beta)^{-1})\) trong đó \(I(\beta)^{-1}\) là ma trận hiệp phương sai của các ước lượng. \(I(\beta)\) được gọi là ma trận thông tin Fisher.
Thuộc tính tiệm cận phân phối chuẩn này là cơ sở để thực hiện các suy diễn thống kê như xây dựng khoảng tin cậy và kiểm định giả thuyết cho các tham số \(\beta\).
4.6 Suy diễn thống kê cho tham số trong GLM
Sau khi ước lượng được các tham số \(\hat{\beta}\), chúng ta cần đánh giá ý nghĩa thống kê của chúng. Có ba loại kiểm định chính, thường được gọi là “bộ ba kiểm định của thống kê” (trinity of tests).
4.6.1 Kiểm định Wald (Wald Test)
Đây là kiểm định phổ biến nhất và thường được hiển thị trong output mặc định của các phần mềm thống kê (ví dụ, trong summary(glm_model) của R). * Giả thuyết: \(H_0: \beta_j = 0\) và \(H_a: \beta_j \ne 0\). * Ý tưởng: Dựa trên thuộc tính tiệm cận phân phối chuẩn của \(\hat{\beta}_j\). Nếu \(H_0\) đúng, thì \(\hat{\beta}_j\) nên gần 0. * Thống kê kiểm định: \(z = \frac{\hat{\beta}_j}{SE(\hat{\beta}_j)}\) hoặc \(W = \left( \frac{\hat{\beta}_j}{SE(\hat{\beta}_j)} \right)^2\) trong đó \(SE(\hat{\beta}_j)\) là sai số chuẩn của \(\hat{\beta}_j\), được lấy từ đường chéo của ma trận hiệp phương sai ước lượng. * Phân phối dưới \(H_0\): \(z\) xấp xỉ tuân theo phân phối chuẩn tắc \(N(0,1)\), và \(W\) xấp xỉ tuân theo phân phối \(\chi^2\) với \(df=1\). * Quyết định: So sánh p-value với mức ý nghĩa \(\alpha\).
4.6.2 Kiểm định Tỷ số hợp lý (Likelihood Ratio Test - LRT)
LRT là một phương pháp rất linh hoạt và mạnh mẽ để so sánh hai mô hình lồng nhau (nested models). * Mô hình lồng nhau: Mô hình thu gọn (Reduced model, \(M_R\)) là một trường hợp đặc biệt của mô hình đầy đủ (Full model, \(M_F\)) khi một hoặc nhiều tham số trong \(M_F\) được đặt bằng 0. * Giả thuyết: \(H_0\): Mô hình thu gọn là đủ (tức là các tham số bị loại bỏ bằng 0). \(H_a\): Cần mô hình đầy đủ. * Ý tưởng: So sánh giá trị log-likelihood của hai mô hình. Nếu mô hình đầy đủ tốt hơn đáng kể, giá trị log-likelihood của nó sẽ lớn hơn nhiều so với mô hình thu gọn. * Thống kê kiểm định: \(G^2 = -2 \log \left( \frac{L_R}{L_F} \right) = -2 (\ell_R - \ell_F) = 2(\ell_F - \ell_R)\) trong đó \(\ell_R\) và \(\ell_F\) là giá trị log-likelihood tối đa của mô hình thu gọn và mô hình đầy đủ. * Phân phối dưới \(H_0\): \(G^2\) xấp xỉ tuân theo phân phối \(\chi^2\) với số bậc tự do \(df\) bằng số lượng tham số bị ràng buộc bằng 0 trong mô hình thu gọn (tức là \(df = \text{số tham số trong } M_F - \text{số tham số trong } M_R\)). * Trong R: Thường sử dụng hàm anova(model_reduced, model_full, test="LRT").
4.6.3 Kiểm định Score (Rao’s Score Test) - giới thiệu
Kiểm định Score ít phổ biến hơn trong các output tiêu chuẩn nhưng có ưu điểm là chỉ cần ước lượng mô hình thu gọn (dưới \(H_0\)). * Ý tưởng: Kiểm tra xem độ dốc (slope, hay score) của hàm log-likelihood tại giá trị tham số dưới \(H_0\) có gần 0 không. Nếu nó khác 0 đáng kể, thì giá trị tối ưu thực sự nằm ở đâu đó khác, và \(H_0\) nên bị bác bỏ. * Một ví dụ quen thuộc của kiểm định Score chính là kiểm định Chi-bình phương Pearson cho tính độc lập trong bảng ngẫu nhiên.
Với mẫu lớn, cả ba kiểm định (Wald, LRT, Score) thường cho kết quả tương tự. Với mẫu nhỏ, LRT thường được cho là đáng tin cậy hơn Wald.
4.6.4 Khoảng tin cậy cho các tham số
Dựa trên kiểm định Wald, khoảng tin cậy (ví dụ 95%) cho một tham số \(\beta_j\) được xây dựng như sau: \(\hat{\beta}_j \pm z_{\alpha/2} \times SE(\hat{\beta}_j)\) Ví dụ, KTC 95% là \(\hat{\beta}_j \pm 1.96 \times SE(\hat{\beta}_j)\). Đối với các mô hình phi tuyến (ví dụ, logistic, Poisson), việc diễn giải các hệ số thường dựa trên một phép biến đổi (ví dụ, \(\exp(\beta_j)\) để có Odds Ratio). Khi đó, người ta thường xây dựng khoảng tin cậy cho \(\beta_j\) trước, sau đó biến đổi hai cận của khoảng tin cậy. Ví dụ, KTC 95% cho \(OR_j\) là \((\exp(\hat{\beta}_j - 1.96 \times SE), \exp(\hat{\beta}_j + 1.96 \times SE))\).
4.7 Đánh giá mức độ phù hợp của mô hình (Goodness-of-fit)
Sau khi xây dựng mô hình và kiểm tra ý nghĩa của các biến, chúng ta cần đánh giá xem mô hình tổng thể có phù hợp với dữ liệu hay không.
4.7.1 Deviance và Scaled Deviance
Deviance của một mô hình (ký hiệu \(D\)) đo lường mức độ khác biệt giữa mô hình đó và mô hình bão hòa (saturated model). Mô hình bão hòa là một mô hình phức tạp nhất có thể, nó mô tả dữ liệu một cách hoàn hảo (tức là giá trị dự báo bằng giá trị quan sát, \(\hat{\mu}_i = y_i\)). \(D = 2(\ell_{sat} - \ell_{fit})\) trong đó \(\ell_{sat}\) và \(\ell_{fit}\) là log-likelihood của mô hình bão hòa và mô hình đang xét (fitted model). Deviance có vai trò tương tự như tổng bình phương phần dư (Residual Sum of Squares - RSS) trong OLS. Giá trị Deviance càng nhỏ, mô hình càng phù hợp với dữ liệu.
Thống kê \(G^2\) trong LRT chính là hiệu số Deviance giữa hai mô hình lồng nhau: \(G^2 = D_R - D_F = 2(\ell_{sat} - \ell_R) - 2(\ell_{sat} - \ell_F) = 2(\ell_F - \ell_R)\)
Kiểm định độ phù hợp bằng Deviance: Nếu mô hình là đúng và tham số phân tán \(\phi=1\) (như trong Poisson, Binomial), thì Deviance \(D\) xấp xỉ tuân theo phân phối \(\chi^2\) với \(df = N - p\), trong đó \(N\) là số quan sát (hoặc số nhóm nếu dữ liệu được nhóm) và \(p\) là số tham số trong mô hình. Một p-value lớn cho thấy mô hình phù hợp tốt. Lưu ý: Kiểm định này chỉ đáng tin cậy khi dữ liệu được nhóm và tần số kỳ vọng trong các nhóm không quá nhỏ. Nó không đáng tin cậy cho dữ liệu không được nhóm (ungrouped data), ví dụ khi có biến độc lập liên tục.
4.7.2 Pearson Chi-squared statistic
Một thống kê khác để đo độ phù hợp là thống kê Chi-bình phương Pearson: \(X^2 = \sum_i \frac{(y_i - \hat{\mu}_i)^2}{V(\hat{\mu}_i)}\) trong đó \(V(\hat{\mu}_i)\) là hàm phương sai được ước tính. Tương tự như Deviance, dưới các điều kiện nhất định, \(X^2\) cũng xấp xỉ phân phối \(\chi^2\) với \(df = N-p\).
4.7.3 Các tiêu chí lựa chọn mô hình: AIC và BIC
Khi so sánh các mô hình không lồng nhau hoặc khi muốn chọn ra mô hình “tốt nhất” từ một tập hợp các mô hình ứng viên, chúng ta không thể dùng LRT. Thay vào đó, chúng ta dùng các tiêu chí thông tin.
- Akaike Information Criterion (AIC): \(AIC = -2\ell_{fit} + 2p\)
- Thành phần đầu tiên (\(-2\ell_{fit}\)) đo lường mức độ không phù hợp của mô hình (càng nhỏ càng tốt).
- Thành phần thứ hai (\(2p\)) là một số hạng phạt cho sự phức tạp của mô hình (\(p\) là số tham số).
- AIC cân bằng giữa độ phù hợp và độ phức tạp. Mô hình có AIC nhỏ hơn được coi là tốt hơn.
- Bayesian Information Criterion (BIC): \(BIC = -2\ell_{fit} + p \log(N)\)
- Tương tự AIC, nhưng số hạng phạt cho sự phức tạp lớn hơn khi \(N \ge 8\) (\(\log(N) > 2\)).
- BIC có xu hướng chọn các mô hình đơn giản hơn so với AIC.
- Mô hình có BIC nhỏ hơn được coi là tốt hơn.
AIC và BIC không cho biết mô hình có “đúng” hay không, chúng chỉ giúp so sánh tương đối giữa các mô hình. Sự khác biệt AIC (hoặc BIC) nhỏ (ví dụ < 2) cho thấy không có sự khác biệt lớn về chất lượng giữa hai mô hình.
4.8 Phân tích phần dư (Residual Analysis) trong GLM
Phân tích phần dư trong GLM phức tạp hơn trong OLS vì phương sai không còn không đổi. Phần dư thô (raw residuals), \(r_i = y_i - \hat{\mu}_i\), không hữu ích vì phương sai của chúng phụ thuộc vào \(\hat{\mu}_i\). Do đó, người ta sử dụng các loại phần dư đã được chuẩn hóa.
Pearson residuals: \(r_{P_i} = \frac{y_i - \hat{\mu}_i}{\sqrt{V(\hat{\mu}_i)}}\) Phần dư này được chuẩn hóa bằng cách chia cho căn bậc hai của hàm phương sai ước tính. Tổng bình phương của chúng chính là thống kê Chi-bình phương Pearson \(X^2\).
Deviance residuals: \(r_{D_i} = \text{sign}(y_i - \hat{\mu}_i) \sqrt{d_i}\) trong đó \(d_i\) là đóng góp của quan sát thứ \(i\) vào tổng Deviance của mô hình. Tổng bình phương của chúng chính là Deviance \(D\).
Cả hai loại phần dư này, nếu mô hình là đúng, nên có phân phối xấp xỉ chuẩn tắc \(N(0,1)\) (mặc dù xấp xỉ này có thể không tốt với mẫu nhỏ). Chúng ta có thể vẽ biểu đồ của các phần dư này so với các giá trị dự báo hoặc các biến độc lập để tìm kiếm các dạng mẫu bất thường, hoặc phát hiện các quan sát ngoại lai (outliers) (những điểm có phần dư lớn, ví dụ \(|r| > 2\) hoặc 3).
4.8.1 Phát hiện các quan sát ảnh hưởng (influential observations)
Một quan sát ảnh hưởng là một điểm dữ liệu mà nếu loại bỏ nó khỏi phân tích, các ước lượng tham số của mô hình sẽ thay đổi đáng kể. Các thước đo phổ biến để phát hiện các điểm ảnh hưởng bao gồm Cook’s distance, DFBETA, và leverage (hat values). Việc vẽ biểu đồ các thước đo này có thể giúp xác định các điểm cần được kiểm tra kỹ lưỡng hơn.
4.9 Thực hành GLM cơ bản với R (sử dụng hàm glm())
Hàm chính để ước lượng GLM trong R là glm(). Cú pháp cơ bản là: glm(formula, family = ..., data = ...)
formula: Công thức mô hình, ví dụy ~ x1 + x2.data: Data frame chứa các biến.family: Đối tượng chỉ định thành phần ngẫu nhiên và hàm liên kết. Đây là phần quan trọng nhất. Một sốfamilyobject phổ biến:gaussian(link = "identity"): Hồi quy tuyến tính (mặc định cho gaussian).binomial(link = "logit"): Hồi quy logistic (mặc định cho binomial).binomial(link = "probit"): Hồi quy probit.poisson(link = "log"): Hồi quy Poisson (mặc định cho poisson).
4.9.1 Ví dụ 1: Mô hình Logistic với dữ liệu mtcars
Chúng ta sẽ mô hình hóa xác suất một chiếc xe có hộp số sàn (am = 1) dựa trên trọng lượng (wt) và công suất (hp).
# Chuẩn bị dữ liệu
data(mtcars)
# Chuyển đổi 'am' thành factor để R hiểu rõ hơn
mtcars$am <- factor(mtcars$am, levels = c(0, 1), labels = c("Automatic", "Manual"))
str(mtcars$am)
# Xây dựng mô hình Logistic
logit_model <- glm(am ~ wt + hp, data = mtcars, family = binomial(link = "logit"))
# family = "binomial" cũng được, R sẽ tự hiểu link = "logit" là mặc định
# Xem kết quả
summary(logit_model)Diễn giải output của summary(logit_model): * Call: Hiển thị lại lệnh đã chạy. * Deviance Residuals: Tóm tắt phân phối của các phần dư deviance. Nếu mô hình tốt, phân phối này nên gần đối xứng quanh 0. * Coefficients: Đây là phần quan trọng nhất. * Estimate: Các ước lượng \(\hat{\beta}\) trên thang đo logit. * Std. Error: Sai số chuẩn \(SE(\hat{\beta})\). * z value: Thống kê kiểm định Wald (\(z = \hat{\beta}/SE(\hat{\beta})\)). * Pr(>|z|): p-value cho kiểm định Wald. p-value nhỏ (ví dụ < 0.05) cho thấy biến đó có ý nghĩa thống kê. * Signif. codes: Giải thích các ký hiệu *, .. * (Dispersion parameter for binomial family taken to be 1): Thông báo tham số phân tán \(\phi\) được cố định bằng 1. * Null deviance: Deviance của mô hình chỉ có hệ số chặn (intercept-only model). * Residual deviance: Deviance của mô hình hiện tại. * AIC: Tiêu chí thông tin Akaike. * Number of Fisher Scoring iterations: Số vòng lặp mà thuật toán IRLS cần để hội tụ.
4.9.2 Ví dụ 2: Mô hình Poisson với dữ liệu quine
Chúng ta sẽ mô hình hóa số ngày nghỉ học (Days) của học sinh ở Úc dựa trên Dân tộc (Eth), Giới tính (Sex), và Tuổi (Age). Dữ liệu có sẵn trong gói MASS.
# Tải dữ liệu
library(MASS)
data(quine)
str(quine)
# Xây dựng mô hình Poisson
poisson_model <- glm(Days ~ Eth + Sex + Age, data = quine, family = poisson(link = "log"))
# family = "poisson" là đủ
# Xem kết quả
summary(poisson_model)Việc diễn giải output của mô hình Poisson tương tự như mô hình logistic, nhưng các hệ số Estimate bây giờ là trên thang đo log của số ngày nghỉ kỳ vọng. Để diễn giải chúng, ta thường dùng \(\exp(\hat{\beta})\). Ví dụ, \(\exp(\hat{\beta}_{\text{SexM}})\) là tỷ số của số ngày nghỉ kỳ vọng của Nam so với Nữ, khi các biến khác được giữ không đổi.
4.10 Tóm tắt chương
Chương 3 đã trang bị cho chúng ta bộ khung lý thuyết và công cụ thực hành nền tảng về Mô hình Tuyến tính Tổng quát (GLMs), một sự mở rộng thiết yếu của mô hình hồi quy tuyến tính cổ điển.
- Sự cần thiết của GLM: Chúng ta đã nhận thấy những hạn chế nghiêm trọng của mô hình OLS khi áp dụng cho biến phụ thuộc định tính, bao gồm việc tạo ra các dự báo vô lý, vi phạm giả định về phương sai không đổi và phân phối chuẩn của phần dư.
- Kiến trúc của GLM: Một GLM được xác định bởi ba thành phần: Thành phần ngẫu nhiên (phân phối xác suất của biến phụ thuộc thuộc họ hàm mũ), Thành phần hệ thống (bộ tiên đoán tuyến tính của các biến độc lập), và Hàm liên kết (kết nối hai thành phần trên).
- Ước lượng và Suy diễn: Các tham số của GLM được ước lượng bằng phương pháp Hợp lý Tối đa (MLE). Các suy diễn thống kê về ý nghĩa của tham số được thực hiện chủ yếu qua Kiểm định Wald (phổ biến trong output) và Kiểm định Tỷ số hợp lý - LRT (dùng để so sánh các mô hình lồng nhau).
- Đánh giá mô hình: Mức độ phù hợp của mô hình được đánh giá thông qua Deviance và Thống kê Chi-bình phương Pearson. Việc lựa chọn giữa các mô hình (kể cả không lồng nhau) được hỗ trợ bởi các tiêu chí thông tin như AIC và BIC. Phân tích các loại phần dư đã chuẩn hóa (Pearson, Deviance) giúp phát hiện các quan sát ngoại lai hoặc sự không phù hợp của mô hình.
- Thực hành với R: Chúng ta đã làm quen với cú pháp của hàm
glm()trong R, chìa khóa để triển khai hầu hết các mô hình trong giáo trình này, thông qua hai ví dụ cơ bản về hồi quy logistic và hồi quy Poisson.
Với nền tảng vững chắc về GLMs, giờ đây chúng ta đã sẵn sàng để đi sâu vào các ứng dụng cụ thể và phổ biến nhất của nó trong các chương tiếp theo, bắt đầu với mô hình hồi quy cho biến phản hồi nhị phân.
4.11 Case studies
Case Study 3.1: Dự đoán khả năng vỡ nợ của khách hàng cá nhân
- Bối cảnh: Một ngân hàng thương mại muốn xây dựng một mô hình đơn giản để dự đoán khả năng một khách hàng vỡ nợ khoản vay tiêu dùng (biến
default, 1=vỡ nợ, 0=không). Các biến độc lập bao gồmthu_nhap(thu nhập hàng tháng, triệu đồng),tuoi(tuổi của khách hàng), vàti_le_no(tỷ lệ nợ trên thu nhập hàng tháng). - Câu hỏi:
- Tại sao mô hình hồi quy logistic (một loại GLM) lại phù hợp cho bài toán này hơn là mô hình xác suất tuyến tính?
- Xây dựng mô hình GLM phù hợp trong R.
- Dựa vào output, biến nào có ảnh hưởng ý nghĩa thống kê đến khả năng vỡ nợ?
- Vận dụng kiến thức chương 3:
- Sử dụng
glm()vớifamily = binomial(link = "logit"). - Đọc và diễn giải output từ
summary(), chú ý đến các p-value của kiểm định Wald.
# Giả lập dữ liệu set.seed(302) n_kh <- 500 thu_nhap <- rnorm(n_kh, 20, 8) tuoi <- rnorm(n_kh, 35, 10) ti_le_no <- runif(n_kh, 0.1, 0.8) # Tạo logit của xác suất vỡ nợ logit_p_default <- 1 - 0.1*thu_nhap + 0.05*tuoi + 2*ti_le_no - 2 p_default <- 1 / (1 + exp(-logit_p_default)) default <- rbinom(n_kh, 1, p_default) df_vay <- data.frame(default, thu_nhap, tuoi, ti_le_no) # Xây dựng mô hình model_default <- glm(default ~ thu_nhap + tuoi + ti_le_no, data = df_vay, family = binomial) # Xem kết quả summary(model_default) # Diễn giải: # 1. Mô hình logistic phù hợp vì biến phụ thuộc là nhị phân (0/1), nó đảm bảo # xác suất dự báo nằm trong khoảng và xử lý được các vấn đề của LPM. # 2. Xem p-value (cột Pr(>|z|)) trong output. Nếu p < 0.05, biến đó có ý nghĩa. - Sử dụng
Case Study 3.2: Lựa chọn giữa hai mô hình dự báo Churn
- Bối cảnh: Một công ty viễn thông muốn dự đoán khách hàng có rời mạng (churn) hay không. Họ có hai mô hình ứng viên:
- Mô hình 1:
churn ~ so_thang_sd + goi_cuoc(số tháng sử dụng, loại gói cước) - Mô hình 2:
churn ~ so_thang_sd + goi_cuoc + phan_nan(thêm biến số lần phàn nàn)
- Mô hình 1:
- Câu hỏi:
- Hai mô hình này có lồng nhau không? Nếu có, bạn sẽ dùng kiểm định gì để so sánh chúng?
- Sử dụng AIC để so sánh hai mô hình. Mô hình nào tốt hơn?
- Vận dụng kiến thức chương 3:
- Sử dụng LRT (với
anova(model1, model2, test="LRT")) vì mô hình 1 lồng trong mô hình 2. - So sánh giá trị AIC từ
summary()của hai mô hình.
# Giả lập dữ liệu set.seed(303) n_churn <- 1000 so_thang_sd <- runif(n_churn, 1, 72) goi_cuoc <- factor(sample(c("A", "B", "C"), n_churn, replace=TRUE)) phan_nan <- rpois(n_churn, lambda = 0.5) logit_p_churn <- -0.05*so_thang_sd + ifelse(goi_cuoc=="B", 0.5, ifelse(goi_cuoc=="C", 1, 0)) + 0.8*phan_nan - 2 p_churn <- 1 / (1 + exp(-logit_p_churn)) churn <- rbinom(n_churn, 1, p_churn) df_churn <- data.frame(churn, so_thang_sd, goi_cuoc, phan_nan) # Xây dựng mô hình model_churn_1 <- glm(churn ~ so_thang_sd + goi_cuoc, data = df_churn, family = binomial) model_churn_2 <- glm(churn ~ so_thang_sd + goi_cuoc + phan_nan, data = df_churn, family = binomial) # 1. So sánh bằng LRT lrt_result <- anova(model_churn_1, model_churn_2, test = "LRT") print("Kiểm định Tỷ số hợp lý (LRT):") print(lrt_result) # p-value nhỏ (cột Pr(>Chi)) cho thấy mô hình 2 tốt hơn đáng kể. # 2. So sánh bằng AIC aic_1 <- AIC(model_churn_1) aic_2 <- AIC(model_churn_2) cat("\nAIC Mô hình 1:", aic_1, "\n") cat("AIC Mô hình 2:", aic_2, "\n") cat("Mô hình có AIC nhỏ hơn là tốt hơn.\n") - Sử dụng LRT (với
Case Study 3.3: Phân tích số lượng Khiếu nại của khách hàng
- Bối cảnh: Một công ty bảo hiểm muốn phân tích các yếu tố ảnh hưởng đến số lượng khiếu nại (
so_khieu_nai) mà một khách hàng đưa ra trong một năm. Các yếu tố bao gồmloai_bh(loại bảo hiểm: Sức khỏe, Xe cộ, Nhà cửa) vàthoi_gian_kh(thời gian là khách hàng, tính bằng năm). - Câu hỏi:
- Biến phụ thuộc
so_khieu_naicó đặc điểm gì? Loại phân phối nào trong GLM có thể phù hợp để mô hình hóa nó? Hàm liên kết kinh điển là gì? - Xây dựng mô hình GLM phù hợp trong R.
- Kiểm tra Deviance của mô hình. Giá trị
Residual devianceso vớidegrees of freedomcho thấy điều gì? (Gợi ý: Nếu Deviance/df >> 1, có thể có hiện tượng quá phân tán).
- Biến phụ thuộc
- Vận dụng kiến thức chương 3:
- Biến đếm, phù hợp với phân phối Poisson, hàm liên kết kinh điển là log.
- Sử dụng
glm()vớifamily = poisson. - So sánh
Residual deviancevàResidual degrees of freedomtrongsummary().
# Giả lập dữ liệu set.seed(304) n_ins <- 300 loai_bh <- factor(sample(c("Sức khỏe", "Xe cộ", "Nhà cửa"), n_ins, replace=TRUE)) thoi_gian_kh <- runif(n_ins, 1, 15) log_lambda <- ifelse(loai_bh=="Sức khỏe", 0.5, ifelse(loai_bh=="Xe cộ", 0.2, 0)) - 0.05*thoi_gian_kh lambda <- exp(log_lambda) so_khieu_nai <- rpois(n_ins, lambda) df_ins <- data.frame(so_khieu_nai, loai_bh, thoi_gian_kh) # Xây dựng mô hình model_claims <- glm(so_khieu_nai ~ loai_bh + thoi_gian_kh, data = df_ins, family = poisson) # Xem kết quả summary(model_claims) # Kiểm tra quá phân tán dev_div_df <- summary(model_claims)$deviance / summary(model_claims)$df.residual cat("\nTỷ lệ Deviance / df:", dev_div_df, "\n") # Nếu tỷ lệ này lớn hơn 1 đáng kể, có thể có quá phân tán.
Case Study 3.4: Đánh giá mô hình bằng phân tích phần dư
- Bối cảnh: Sử dụng lại
model_defaulttừ Case Study 3.1. Một nhà phân tích lo ngại rằng mô hình có thể bị ảnh hưởng bởi một vài quan sát ngoại lai. - Câu hỏi:
- Trích xuất và vẽ biểu đồ của phần dư Pearson (Pearson residuals) của mô hình.
- Xác định các quan sát có giá trị tuyệt đối của phần dư Pearson lớn hơn 2. Các quan sát này có đặc điểm gì?
- Vận dụng kiến thức chương 3:
- Sử dụng hàm
residuals(model, type = "pearson"). - Vẽ biểu đồ phần dư và lọc các quan sát có phần dư lớn.
# Sử dụng model_default từ Case Study 3.1 # 1. Trích xuất và vẽ biểu đồ phần dư pearson_res <- residuals(model_default, type = "pearson") df_vay$pearson_res <- pearson_res ggplot(df_vay, aes(x = seq_along(pearson_res), y = pearson_res)) + geom_point(aes(color = factor(default))) + geom_hline(yintercept = c(-2, 2), linetype = "dashed", color = "red") + labs(title = "Biểu đồ phần dư Pearson", x = "Chỉ số quan sát", y = "Phần dư Pearson") # 2. Xác định các quan sát ngoại lai outliers <- df_vay[abs(df_vay$pearson_res) > 2, ] print("Các quan sát có phần dư Pearson > 2:") print(outliers) # Các quan sát này là những điểm mà mô hình dự báo kém nhất. # Ví dụ, một khách hàng có các đặc điểm (thu nhập, tuổi, nợ) cho thấy nguy cơ vỡ nợ thấp # (mô hình dự báo p rất nhỏ) nhưng thực tế lại vỡ nợ (y=1). - Sử dụng hàm
Case Study 3.5: So sánh mô hình Logit và Probit
- Bối cảnh: Một nhà nghiên cứu kinh tế muốn mô hình hóa quyết định tham gia lực lượng lao động (
inlf, 1=tham gia) của phụ nữ, dựa vào số con dưới 6 tuổi (k5) và trình độ học vấn (educ). Họ phân vân giữa mô hình Logit và Probit. - Câu hỏi:
- Sự khác biệt cơ bản về lý thuyết giữa mô hình Logit và Probit là gì?
- Xây dựng cả hai mô hình trong R.
- So sánh giá trị AIC của hai mô hình. Có sự khác biệt lớn nào không? So sánh các giá trị dự báo từ hai mô hình.
- Vận dụng kiến thức chương 3:
- Hàm liên kết Logit dựa trên phân phối Logistic, Probit dựa trên phân phối Chuẩn.
- Sử dụng
glm()vớifamily = binomial(link = "logit")vàfamily = binomial(link = "probit"). - So sánh AIC và các giá trị
fitted(model).
# Sử dụng dữ liệu Mroz từ gói wooldridge (install.packages("wooldridge")) library(wooldridge) data(mroz) # Mô hình Logit mroz_logit <- glm(inlf ~ k5 + educ, data = mroz, family = binomial(link = "logit")) # Mô hình Probit mroz_probit <- glm(inlf ~ k5 + educ, data = mroz, family = binomial(link = "probit")) # So sánh AIC cat("AIC Logit:", AIC(mroz_logit), "\n") cat("AIC Probit:", AIC(mroz_probit), "\n") # Thường thì AIC của 2 mô hình này rất sát nhau. # So sánh các giá trị dự báo mroz$pred_logit <- fitted(mroz_logit) mroz$pred_probit <- fitted(mroz_probit) ggplot(mroz, aes(x = pred_logit, y = pred_probit)) + geom_point(alpha=0.4) + geom_abline(intercept = 0, slope = 1, color = "red", linetype = "dashed") + labs(title = "So sánh giá trị dự báo giữa mô hình Logit và Probit", x = "Xác suất dự báo (Logit)", y = "Xác suất dự báo (Probit)") # Biểu đồ cho thấy các dự báo rất tương đồng.
4.12 Bài tập
4.12.1 Bài tập lý thuyết
- Liệt kê và giải thích ít nhất 3 vấn đề chính khi sử dụng Mô hình Hồi quy Tuyến tính Cổ điển (OLS) cho một biến phụ thuộc nhị phân.
- Nêu và mô tả ngắn gọn ba thành phần cốt lõi của một Mô hình Tuyến tính Tổng quát (GLM).
- Hàm liên kết (link function) có vai trò gì trong GLM? Tại sao nó lại quan trọng?
- Điền vào các ô trống trong bảng sau:
| Tên mô hình | Phân phối của Y | Hàm liên kết (tên) |
|---|---|---|
| Hồi quy Logistic | ? | ? |
| Hồi quy Poisson | ? | Log |
| Hồi quy tuyến tính | Normal | ? |
| Hồi quy Probit | Binomial | ? |
- Hàm phương sai (variance function) \(V(\mu)\) là gì? Nó cho biết điều gì về mối quan hệ giữa phương sai và trung bình của biến phụ thuộc?
- Nguyên lý của phương pháp ước lượng Hợp lý Tối đa (MLE) là gì? Nó khác gì so với phương pháp Bình phương Tối thiểu (OLS)?
- Nêu ba thuộc tính tiệm cận tốt của các ước lượng MLE.
- So sánh Kiểm định Wald và Kiểm định Tỷ số hợp lý (LRT). Khi nào bạn sẽ sử dụng LRT?
- Deviance trong GLM có vai trò tương tự như đại lượng nào trong OLS? Một giá trị Deviance lớn cho thấy điều gì?
- Mục đích của việc sử dụng các tiêu chí thông tin như AIC và BIC là gì? Sự khác biệt chính giữa AIC và BIC là gì?
- Tại sao chúng ta cần sử dụng các loại phần dư đã được chuẩn hóa (như Pearson, Deviance) trong GLM thay vì phần dư thô (\(y_i - \hat{\mu}_i\))?
- Phân biệt giữa một quan sát ngoại lai (outlier) và một quan sát có ảnh hưởng (influential observation).
- Hàm liên kết kinh điển (canonical link) là gì? Việc sử dụng nó có lợi ích gì?
- Hiện tượng quá phân tán (overdispersion) là gì? Nó thường xảy ra với loại mô hình nào?
- Mô hình xác suất tuyến tính (LPM) có ưu điểm nào không (nếu có)?
4.12.2 Bài tập thực hành với R
- Mô hình LPM và GLM: Sử dụng bộ dữ liệu
Affairstừ góiAER(install.packages("AER")). Biếnaffairslà số lần ngoại tình (biến đếm). Hãy tạo một biến nhị phânhad_affair(1 nếuaffairs> 0, 0 nếu ngược lại).- Xây dựng một Mô hình Xác suất Tuyến tính (LPM) để dự báo
had_affairdựa trênage(tuổi) vàyearsmarried(số năm kết hôn) bằng hàmlm(). - Tìm các giá trị dự báo từ mô hình LPM. Có giá trị nào nằm ngoài khoảng [0, 1] không?
- Xây dựng một mô hình Logistic cho cùng bài toán bằng hàm
glm(). - So sánh
summary()của hai mô hình.
- Xây dựng một Mô hình Xác suất Tuyến tính (LPM) để dự báo
- Xây dựng và diễn giải GLM: Sử dụng mô hình Logistic từ bài 16c.
- In ra
summary()của mô hình. - Diễn giải hệ số của biến
age. Nó có ý nghĩa thống kê không? - Trích xuất các hệ số ước lượng và khoảng tin cậy 95% cho chúng (dùng
coef()vàconfint()).
- In ra
- So sánh mô hình lồng nhau bằng LRT: Vẫn sử dụng dữ liệu
Affairs.- Xây dựng mô hình Logistic 1:
had_affair ~ age + yearsmarried. - Xây dựng mô hình Logistic 2:
had_affair ~ age + yearsmarried + religiousness + education. - Sử dụng hàm
anova()vớitest="LRT"để so sánh hai mô hình. Kết luận gì về việc thêm các biếnreligiousnessvàeducation?
- Xây dựng mô hình Logistic 1:
- Sử dụng AIC/BIC để lựa chọn mô hình: Giả sử bạn có hai mô hình không lồng nhau để dự báo
had_affair:- Mô hình A:
had_affair ~ age + education - Mô hình B:
had_affair ~ yearsmarried + religiousness
- Xây dựng cả hai mô hình.
- Tính AIC và BIC cho mỗi mô hình.
- Dựa vào cả hai tiêu chí, mô hình nào được ưa thích hơn?
- Mô hình A:
- Mô hình Poisson: Sử dụng bộ dữ liệu
Poisondatatừ góirobust(install.packages("robust")). Biếnylà số lượng lỗi.- Xây dựng một mô hình Poisson để dự đoán
ydựa trênx1,x2,x3. - Xem
summary()của mô hình. Có dấu hiệu của quá phân tán không (so sánhResidual deviancevàdf)? - Diễn giải hệ số của
x1.
- Xây dựng một mô hình Poisson để dự đoán
- Phân tích Deviance: Sử dụng mô hình Poisson từ bài 20.
Null deviancecó ý nghĩa là gì? Nó tương ứng với mô hình nào?Residual deviancecó ý nghĩa là gì?- Sử dụng hiệu số Deviance để kiểm tra xem liệu việc thêm
x1,x2,x3vào mô hình có cải thiện ý nghĩa so với mô hình chỉ có hệ số chặn không. (Gợi ý: \(G^2 = \text{Null deviance} - \text{Residual deviance}\)).
- Phần dư và chẩn đoán mô hình: Sử dụng mô hình Logistic từ bài 16c.
- Trích xuất phần dư Deviance.
- Vẽ biểu đồ phần dư Deviance so với các giá trị dự báo tuyến tính (
predict(model, type = "link")). Có thấy dạng mẫu nào bất thường không? - Sử dụng hàm
plot(model)để xem các biểu đồ chẩn đoán mặc định của R. Quan sát biểu đồ “Residuals vs Fitted” và “Residuals vs Leverage”.
- Mô hình Probit: Sử dụng lại dữ liệu
Affairs.- Xây dựng mô hình Probit để dự báo
had_affairdựa trênagevàyearsmarried. - So sánh các hệ số của mô hình Probit với mô hình Logit. Chúng có giống nhau không? Tại sao? (Gợi ý: hệ số logit thường lớn hơn hệ số probit khoảng 1.6-1.8 lần).
- So sánh AIC của hai mô hình.
- Xây dựng mô hình Probit để dự báo
- Dự báo với GLM: Sử dụng mô hình Logistic từ bài 16c.
- Tạo một data frame mới
new_datachứa thông tin của hai người giả định:- Người 1: 30 tuổi, kết hôn 5 năm.
- Người 2: 50 tuổi, kết hôn 20 năm.
- Sử dụng hàm
predict()để dự báo xác suất có ngoại tình cho hai người này. (Gợi ý:predict(model, newdata = new_data, type = "response")). - Dự báo trên thang đo logit cho hai người này. (Gợi ý:
type = "link").
- Tạo một data frame mới
- Hàm liên kết tùy chỉnh (Nâng cao): Hàm
glm()cho phép các hàm liên kết khác. Ví dụ,family = binomial(link = "cloglog").- Xây dựng mô hình complementary log-log (cloglog) cho bài toán
Affairs(had_affair ~ age + yearsmarried). - So sánh AIC của mô hình này với mô hình Logit và Probit. Trong trường hợp này, có mô hình nào nổi trội hơn hẳn không?
- Xây dựng mô hình complementary log-log (cloglog) cho bài toán
4.13 Tài liệu tham khảo
- Agresti, A. (2015). Foundations of Linear and Generalized Linear Models. Wiley.
- Dobson, A. J., & Barnett, A. G. (2018). An Introduction to Generalized Linear Models (4th ed.). Chapman and Hall/CRC.
- Faraway, J. J. (2016). Extending the Linear Model with R: Generalized Linear, Mixed Effects and Nonparametric Regression Models (2nd ed.). Chapman and Hall/CRC.
- Hardin, J. W., & Hilbe, J. M. (2018). Generalized Linear Models and Extensions (4th ed.). Stata Press.
- McCullagh, P., & Nelder, J. A. (1989). Generalized Linear Models (2nd ed.). Chapman and Hall/CRC.
- Nelder, J. A., & Wedderburn, R. W. M. (1972). Generalized Linear Models. Journal of the Royal Statistical Society. Series A (General), 135(3), 370–384.